Step-GUI Technical Report
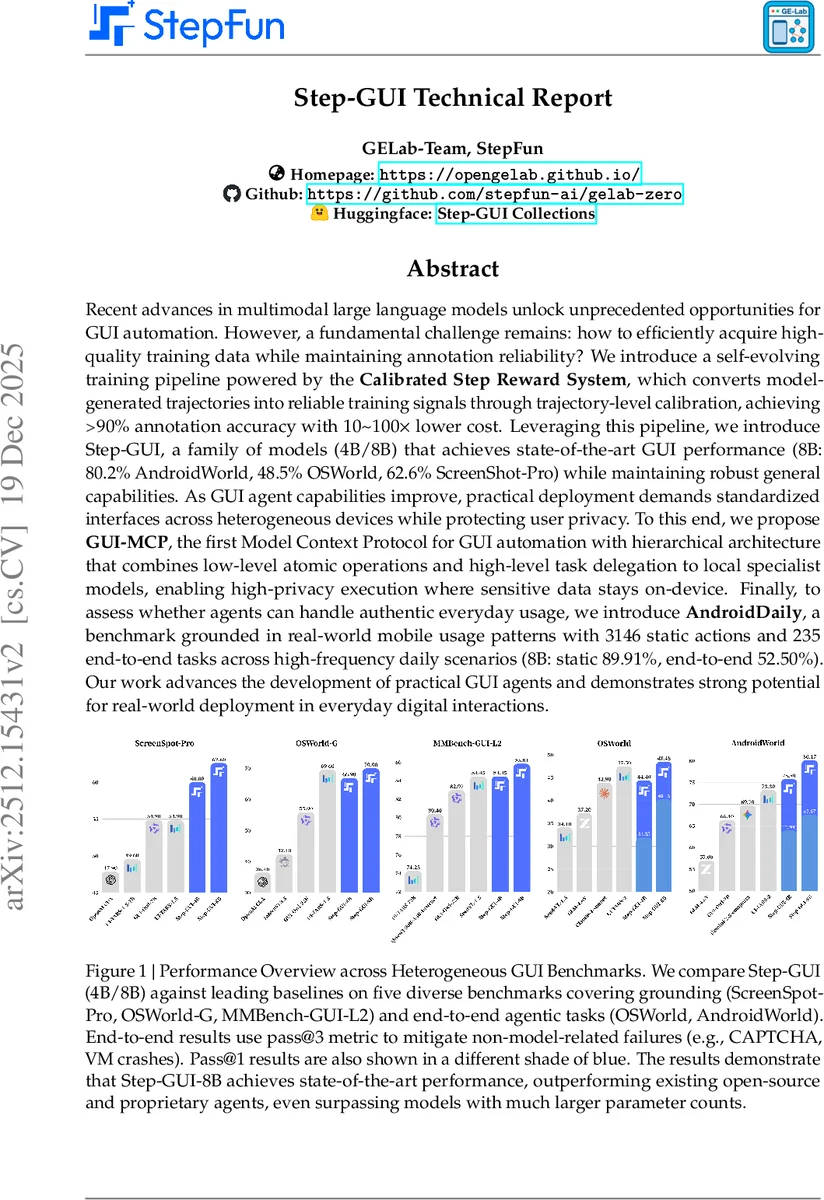
Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
💡 Research Summary
The paper presents a comprehensive framework for building practical GUI‑automation agents, addressing three long‑standing challenges: (1) obtaining high‑quality training data at low cost, (2) standardizing interaction across heterogeneous devices while preserving user privacy, and (3) evaluating agents on realistic everyday tasks.
To solve the data problem, the authors introduce the Calibrated Step Reward System (CSRS). CSRS anchors model‑generated multi‑step interaction trajectories to external verification signals—either automated scripts or human annotations—providing a trajectory‑level reward that calibrates step‑level annotations. This approach yields over 90 % annotation accuracy while reducing labeling cost by a factor of 10–100 compared with traditional step‑wise labeling.
The training pipeline is split into a “mid‑train” stage and a “cold‑start” stage. Mid‑train mixes large‑scale general multimodal and knowledge data (≈5.9 M samples) with agent‑oriented data such as action‑alignment pairs (170 K) and multi‑step trajectories (4 M) across Android, Ubuntu, Windows, and macOS. This stage endows the model with broad world knowledge, visual grounding, and basic instruction‑to‑action mapping. Cold‑start focuses on error‑driven knowledge injection: execution failures are analyzed, the missing knowledge is reformulated as VQA pairs, and 864 K such samples are added alongside 404 K high‑quality trajectories. The cold‑start mixture (≈1.67 M samples) therefore concentrates on patching knowledge gaps while preserving general multimodal competence.
Grounding for GUI is re‑thought beyond simple text‑region alignment. The authors argue that a GUI element carries functional semantics, latent state, and HCI conventions. They build an iterative grounding‑cleaning pipeline that uses a pass‑rate label and a complexity scorer to filter noisy annotations, then applies curriculum‑based SFT and reinforcement learning to progressively introduce more challenging functional and intent‑alignment tasks.
Built on the Qwen3‑VL backbone, the authors train two specialist models: StepGUI‑4B and StepGUI‑8B. StepGUI‑8B achieves state‑of‑the‑art results on several public benchmarks—80.2 % on AndroidWorld, 48.5 % on OSWorld, and 62.6 % on ScreenShot‑Pro—surpassing both open‑source and proprietary agents, even those with far larger parameter counts. The 4 B model remains lightweight enough for consumer‑grade hardware, enabling on‑device inference without cloud dependence.
For deployment, the paper proposes GUI‑MCP (Model Context Protocol for GUI), the first MCP implementation tailored to GUI automation. GUI‑MCP defines a hierarchical dual‑layer architecture: a Low‑level MCP exposing atomic operations (click, swipe, text input) and a High‑level MCP that delegates whole tasks to locally deployed specialist models such as StepGUI‑4B. This separation lets a central LLM focus on high‑level planning while routine UI actions are off‑loaded. Crucially, GUI‑MCP supports a “privacy mode” where raw screenshots and sensitive UI states never leave the device; only semantic summaries are transmitted to external LLMs, thereby protecting user data while still leveraging cloud‑based reasoning.
To assess real‑world applicability, the authors introduce AndroidDaily, a benchmark derived from empirical mobile usage patterns. AndroidDaily contains 3,146 static actions for single‑step prediction and 235 end‑to‑end tasks covering high‑frequency scenarios (transport, shopping, social media, entertainment, local services). StepGUI‑8B scores 89.91 % on the static benchmark and 52.50 % on the end‑to‑end benchmark, demonstrating strong performance on everyday tasks while also revealing remaining gaps for full autonomy.
In summary, the contributions are: (1) CSRS‑driven self‑evolving data pipeline with 10–100× cost reduction, (2) StepGUI family achieving SOTA performance across multiple GUI benchmarks, (3) GUI‑MCP, a standardized, privacy‑preserving protocol for LLM‑device interaction, and (4) AndroidDaily, an ecologically valid benchmark for daily mobile usage. Together, these advances provide a full stack—from data collection and model training to deployment standards and realistic evaluation—paving the way for GUI agents that can reliably assist users in their daily digital interactions.
Comments & Academic Discussion
Loading comments...
Leave a Comment