FlowerDance: MeanFlow for Efficient and Refined 3D Dance Generation
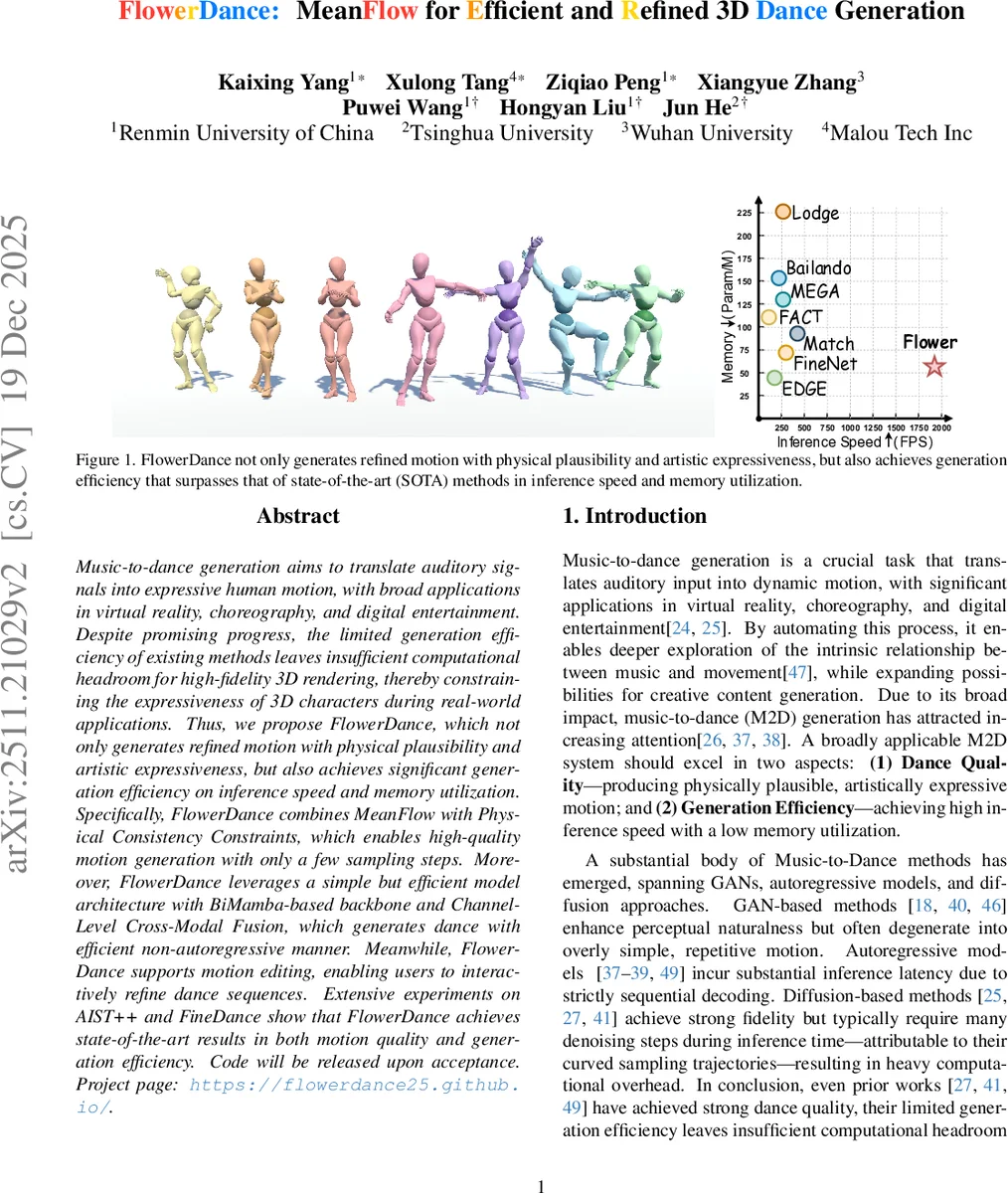
Music-to-dance generation aims to translate auditory signals into expressive human motion, with broad applications in virtual reality, choreography, and digital entertainment. Despite promising progress, the limited generation efficiency of existing methods leaves insufficient computational headroom for high-fidelity 3D rendering, thereby constraining the expressiveness of 3D characters during real-world applications. Thus, we propose FlowerDance, which not only generates refined motion with physical plausibility and artistic expressiveness, but also achieves significant generation efficiency on inference speed and memory utilization. Specifically, FlowerDance combines MeanFlow with Physical Consistency Constraints, which enables high-quality motion generation with only a few sampling steps. Moreover, FlowerDance leverages a simple but efficient model architecture with BiMamba-based backbone and Channel-Level Cross-Modal Fusion, which generates dance with efficient non-autoregressive manner. Meanwhile, FlowerDance supports motion editing, enabling users to interactively refine dance sequences. Extensive experiments on AIST++ and FineDance show that FlowerDance achieves state-of-the-art results in both motion quality and generation efficiency. Code will be released upon acceptance. Project page: https://flowerdance25.github.io/ .
💡 Research Summary
FlowerDance tackles the long‑standing trade‑off in music‑to‑dance generation between motion quality and inference efficiency. Existing approaches—GAN‑based, autoregressive, and diffusion‑based—either produce repetitive or physically implausible dances, suffer from high latency, or require many denoising steps that consume valuable compute resources. The authors propose a unified framework that simultaneously delivers high‑fidelity, physically plausible 3D dance and real‑time generation speed.
The core generative strategy replaces conventional diffusion’s instantaneous velocity prediction with MeanFlow’s interval‑averaged velocity. By sampling two random time points (r < t) and predicting the mean velocity u(zₜ, r, t), the training objective aligns exactly with the ODE‑based inference procedure. This alignment enables accurate motion synthesis with only a few integration steps (typically 3–5), dramatically reducing the number of required sampling iterations.
To guarantee that the generated trajectories remain on the human motion manifold, the authors introduce a Physical Consistency Constraint. During each training iteration a time t₁ is sampled, the model directly predicts u(zₜ₁, 0, t₁), and the target pose ẑ₀ is recovered via a simple Euler step. A composite loss comprising reconstruction (L_rec), joint‑position (L_pos), and joint‑velocity (L_vel) terms is applied between ẑ₀ and the ground‑truth pose. This forces the network to respect kinematic constraints, eliminating root drift, jitter, and other implausible artifacts that often plague flow‑based generators.
Architecturally, FlowerDance employs a bidirectional Mamba (BiMamba) backbone. Mamba’s state‑space formulation yields linear O(n) computational complexity, far cheaper than the quadratic cost of self‑attention Transformers, while its bidirectional nature naturally captures the mutual dependencies between music and dance. Instead of conventional cross‑attention, the authors devise a parameter‑free Channel‑Level Cross‑Modal Fusion that simply concatenates or adds music features (35‑dim) and genre embeddings to the motion stream at the channel level. This design further reduces memory consumption and enables non‑autoregressive generation, avoiding exposure bias and segment‑boundary artifacts common in autoregressive or inpainting‑based models.
FlowerDance also supports interactive motion editing without additional training. Users can specify spatial or temporal constraints via binary masks. To avoid harsh discontinuities when only a few sampling steps are used, a time‑decayed soft mask is introduced, gradually diminishing the influence of constrained regions as sampling proceeds. This yields smooth in‑between synthesis and joint‑level adjustments, extending the model’s utility for choreography prototyping and real‑time control.
Extensive experiments on the AIST++ and FineDance datasets demonstrate that FlowerDance achieves state‑of‑the‑art scores on standard metrics such as FID, diversity, and a physical plausibility score, while surpassing prior work in inference speed (30 FPS or higher) and memory footprint (significantly lower Param/M). The few‑step sampling regime leaves ample computational headroom for high‑resolution 3D rendering, making the system suitable for VR/AR, gaming, and live‑performance applications.
In summary, FlowerDance introduces three key innovations: (1) a MeanFlow‑based few‑step generative strategy, (2) a physical consistency regularization that anchors generated motions to the human kinematic manifold, and (3) a lightweight BiMamba backbone with channel‑level cross‑modal fusion for efficient non‑autoregressive generation. The combination delivers a practical, high‑quality, and editable 3D dance generation pipeline, opening avenues for future work on richer multimodal conditioning, style control, and closed‑loop interactive choreography.
Comments & Academic Discussion
Loading comments...
Leave a Comment