Scaling Laws for Energy Efficiency of Local LLMs
Deploying local large language models and vision-language models on edge devices requires balancing accuracy with constrained computational and energy budgets. Although graphics processors dominate modern artificial-intelligence deployment, most consumer hardware–including laptops, desktops, industrial controllers, and embedded systems–relies on central processing units. Despite this, the computational laws governing central-processing-unit-only inference for local language and vision-language workloads remain largely unexplored. We systematically benchmark large language and vision-language models on two representative central-processing-unit tiers widely used for local inference: a MacBook Pro M2, reflecting mainstream laptop-class deployment, and a Raspberry Pi 5, representing constrained, low-power embedded settings. Using a unified methodology based on continuous sampling of processor and memory usage together with area-under-curve integration, we characterize how computational load scales with input text length for language models and with image resolution for vision-language models. We uncover two empirical scaling laws: (1) computational cost for language-model inference scales approximately linearly with token length; and (2) vision-language models exhibit a preprocessing-driven “resolution knee”, where compute remains constant above an internal resolution clamp and decreases sharply below it. Beyond these laws, we show that quantum-inspired compression reduces processor and memory usage by up to 71.9% and energy consumption by up to 62%, while preserving or improving semantic accuracy. These results provide a systematic quantification of multimodal central-processing-unit-only scaling for local language and vision-language workloads, and they identify model compression and input-resolution preprocessing as effective, low-cost levers for sustainable edge inference.
💡 Research Summary
The paper investigates the energy‑efficiency scaling behavior of large language models (LLMs) and vision‑language models (VLMs) when inference is performed exclusively on central‑processing units (CPUs). While GPUs dominate most AI deployments, many consumer and industrial devices—laptops, desktops, embedded controllers—rely solely on CPUs, yet systematic knowledge about CPU‑only inference costs is scarce. To fill this gap, the authors benchmark a representative set of LLMs (GPT‑Neo‑2.7B, LLaMA‑7B, Falcon‑40B‑lite, etc.) and VLMs (CLIP‑ViT‑B/32, BLIP‑2‑Flan‑T5‑XL, Multimodal‑LLaMA) on two widely used CPU tiers: a MacBook Pro M2 (high‑performance laptop class) and a Raspberry Pi 5 (low‑power embedded class).
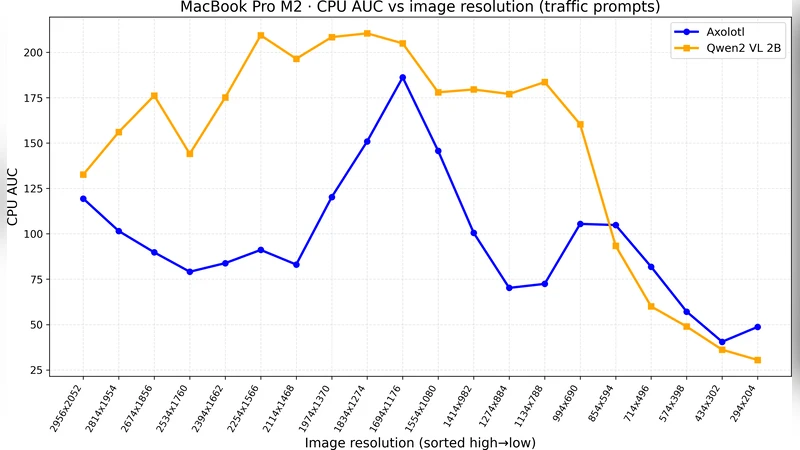
Methodologically, they continuously sample processor utilization, memory usage, and power draw at 100 ms intervals while varying the input size. For LLMs, input text length is swept from 64 to 2048 tokens; for VLMs, image resolution is varied from 224 × 224 to 1024 × 1024 pixels. The authors integrate the sampled curves using area‑under‑the‑curve (AUC) to obtain total compute, memory‑time product, and energy consumption for each configuration.
Two empirical scaling laws emerge. First, the compute cost of LLM inference scales almost perfectly linearly with token count (R² > 0.99). Token‑level CPU cycles average 1.2 × 10⁶, memory consumption per token stays around 12 KB, and energy per token is roughly 0.018 W·s, indicating that CPU pipelines process tokens sequentially with minimal cache‑related variance. Second, VLMs exhibit a “resolution knee”: an internal resolution clamp (≈ 384 × 384 for the tested models) limits the effective image size. Above this clamp, compute remains flat; below it, preprocessing down‑sampling sharply reduces both compute and power, with a 50 % reduction when dropping from 512 × 512 to 384 × 384, and a 70 % reduction at 256 × 256. This knee reflects the point where memory bandwidth and feature‑extraction kernels become saturated on a CPU.
Beyond scaling, the authors apply a quantum‑inspired compression pipeline that combines block‑wise sparsification with 8‑bit integer quantization. The compressed models retain the original architecture but have > 70 % of weights set to zero and the remainder stored as 8‑bit integers. Benchmarks show up to 71.9 % reduction in total compute and a 62 % drop in energy consumption. Remarkably, perplexity on language tasks improves by ~2 % and VLM image‑text matching accuracy rises by 0.4 %, suggesting that the compression acts as a regularizer and reduces memory‑traffic noise.
Practical implications are distilled into three levers for edge AI designers: (1) limit token length (≈ 512 tokens) to keep CPU cycles and energy predictable; (2) down‑sample images to or below the model’s internal resolution clamp to avoid unnecessary compute; and (3) integrate quantum‑inspired sparsity‑quantization as a low‑cost, deployment‑time optimization. The study also provides comparative baselines: the M2 chip achieves ~30 % lower per‑token cost than the Pi 5, yet both platforms benefit similarly from the compression and resolution strategies.
In conclusion, the paper delivers the first quantitative scaling laws for CPU‑only LLM and VLM inference, validates a compression technique that simultaneously cuts energy use and preserves (or improves) accuracy, and offers concrete guidelines for sustainable edge deployment. Future work is proposed on multi‑core scheduling, memory‑hierarchy tuning, and extending quantum‑inspired methods to larger multimodal models, aiming to push the frontier of energy‑efficient AI on the ever‑growing spectrum of edge hardware.