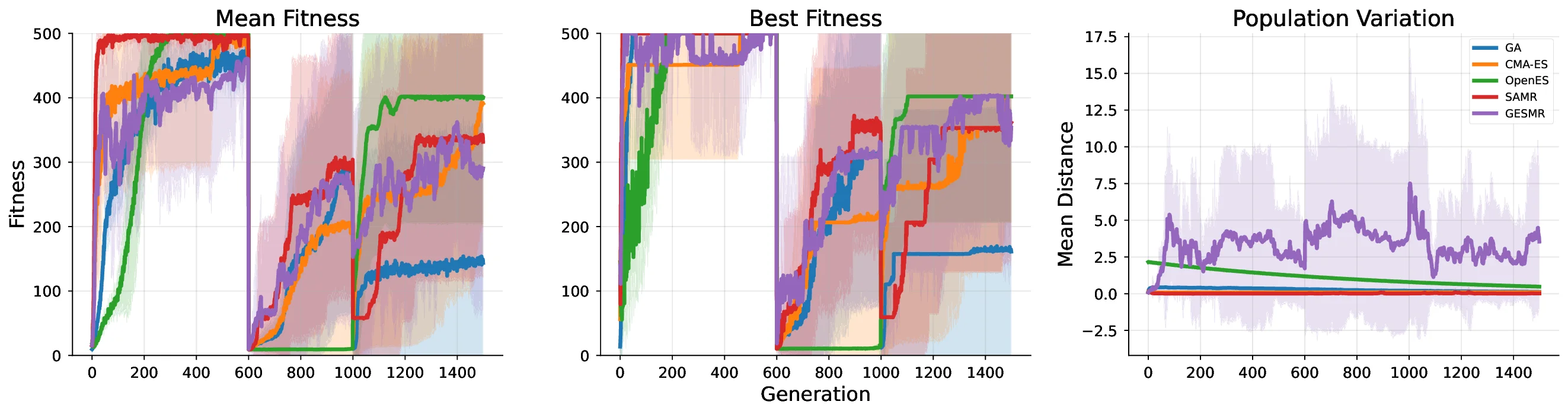
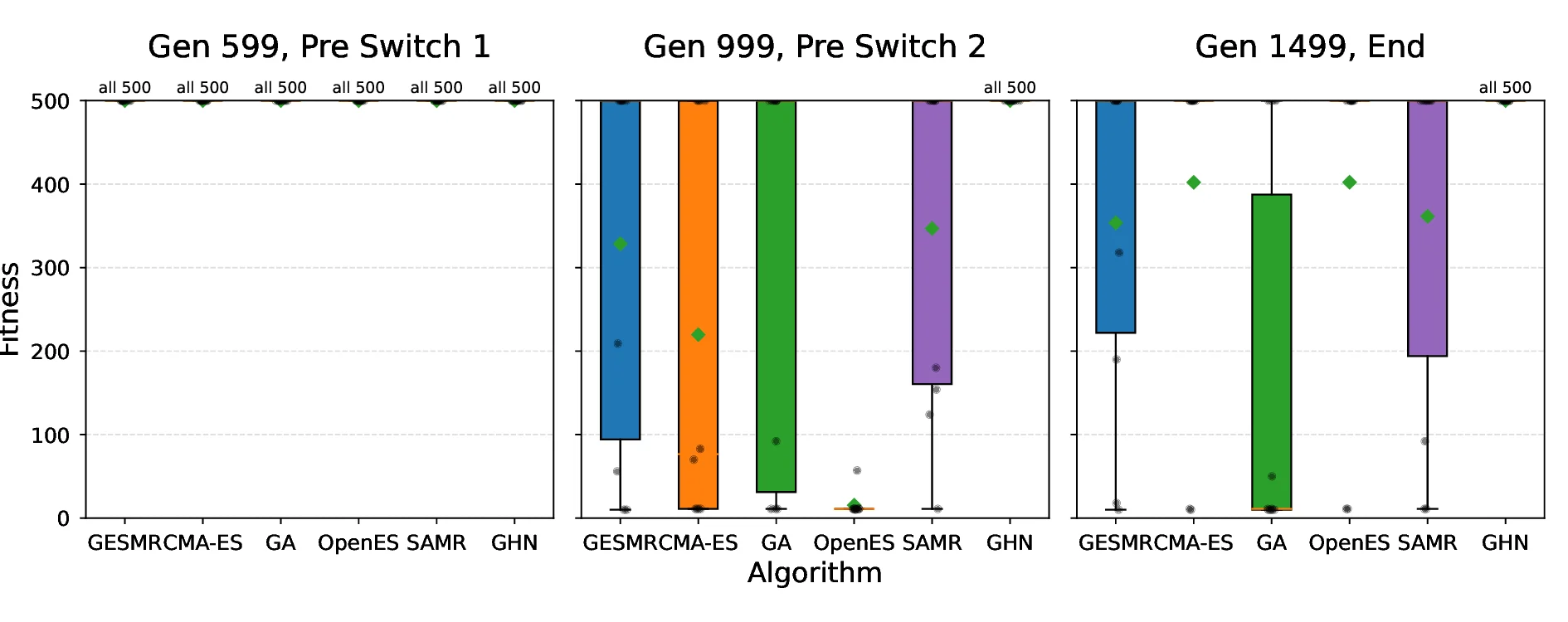
How can neural networks evolve themselves without relying on external optimizers? We propose Self-Referential Graph HyperNetworks, systems where the very machinery of variation and inheritance is embedded within the network. By uniting hypernetworks, stochastic parameter generation, and graph-based representations, Self-Referential GHNs mutate and evaluate themselves while adapting mutation rates as selectable traits. Through new reinforcement learning benchmarks with environmental shifts (CartPoleSwitch, LunarLander-Switch), Self-Referential GHNs show swift, reliable adaptation and emergent population dynamics. In the locomotion benchmark Ant-v5, they evolve coherent gaits, showing promising fine-tuning capabilities by autonomously decreasing variation in the population to concentrate around promising solutions. Our findings support the idea that evolvability itself can emerge from neural self-reference. Self-Referential GHNs reflect a step toward synthetic systems that more closely mirror biological evolution, offering tools for autonomous, open-ended learning agents.
Deep Dive into Hypernetworks That Evolve Themselves.
How can neural networks evolve themselves without relying on external optimizers? We propose Self-Referential Graph HyperNetworks, systems where the very machinery of variation and inheritance is embedded within the network. By uniting hypernetworks, stochastic parameter generation, and graph-based representations, Self-Referential GHNs mutate and evaluate themselves while adapting mutation rates as selectable traits. Through new reinforcement learning benchmarks with environmental shifts (CartPoleSwitch, LunarLander-Switch), Self-Referential GHNs show swift, reliable adaptation and emergent population dynamics. In the locomotion benchmark Ant-v5, they evolve coherent gaits, showing promising fine-tuning capabilities by autonomously decreasing variation in the population to concentrate around promising solutions. Our findings support the idea that evolvability itself can emerge from neural self-reference. Self-Referential GHNs reflect a step toward synthetic systems that more closely m
Hypernetworks That Evolve Themselves
Joachim Winther Pedersen1, Erwan Plantec1, Eleni Nisioti1, Marcello Barylli1,
Milton Montero1, Kathrin Korte1, and Sebastian Risi1,2
1IT University of Copenhagen, Denmark
2 Sakana AI
jwin@itu.dk, sebr@itu.dk
Abstract
How can neural networks evolve themselves without rely-
ing on external optimizers?
We propose Self-Referential
Graph HyperNetworks, systems where the very machinery
of variation and inheritance is embedded within the net-
work. By uniting hypernetworks, stochastic parameter gen-
eration, and graph-based representations, Self-Referential
GHNs mutate and evaluate themselves while adapting mu-
tation rates as selectable traits. Through new reinforcement
learning benchmarks with environmental shifts (CartPole-
Switch, LunarLander-Switch), Self-Referential GHNs show
swift, reliable adaptation and emergent population dynam-
ics. In the locomotion benchmark Ant-v5, they evolve co-
herent gaits, showing promising fine-tuning capabilities by
autonomously decreasing variation in the population to con-
centrate around promising solutions. Our findings support
the idea that evolvability itself can emerge from neural self-
reference. Self-Referential GHNs reflect a step toward syn-
thetic systems that more closely mirror biological evolution,
offering tools for autonomous, open-ended learning agents.
Data/Code available at:
https://github.com/
Joachm/self-referential_GHNs
Introduction
Neural networks have achieved remarkable success across
diverse domains such as image recognition (Krizhevsky
et al., 2012; He et al., 2016), natural-language under-
standing (Devlin et al., 2019; Brown et al., 2020), and
strategic decision-making in games (Silver et al., 2016).
This progress is powered largely by gradient-based opti-
mization procedures, including back-propagation (Rumel-
hart et al., 1986).
Nevertheless, gradient methods ex-
hibit persistent shortcomings—susceptibility to local min-
ima, ill-conditioned landscapes, and an inability to cope
with non-differentiable objectives or discrete architectural
choices (Goodfellow et al., 2016; Choromanska et al., 2015).
These limitations have sparked a renewed wave of in-
terest in evolutionary algorithms (EAs) as an alternative
or complementary approach to optimizing neural networks
(Rechenberg, 1984; Holland, 1984; Back, 1996; Risi et al.,
2025).
Modern large-scale instantiations, including Ope-
nAI Evolution Strategies (Salimans et al., 2017), Deep Neu-
roevolution (Such et al., 2017), and population-based neu-
ral architecture search (Real et al., 2019; Stanley et al.,
2019) demonstrate that, when supplied with massive par-
allel compute, EAs can match or exceed gradient learners
on reinforcement-learning and AutoML benchmarks. Their
derivative-free, population-based nature also makes them
well-suited to distributed training regimes (Jaderberg et al.,
2017; Salimans et al., 2017).
A lesson from evolutionary biology is that the rate and
structure of mutation matter: low variation accelerates ex-
ploitation but risks premature convergence, whereas high
variation fosters exploration but risks already accrued fitness
(Giraud et al., 2001). Adaptive mutation rates, as heritable
traits of individuals, might be especially important in open-
ended systems, where the fitness landscape might undergo
severe changes over time (Lehman et al., 2025).
Yet, most contemporary neuroevolution approaches keep
the evolutionary machinery outside the neural substrate be-
ing optimized: an algorithm separated from the individu-
als in the population is responsible for producing mutations
to the individuals. In this work, we collapse that boundary
by embedding the variation-producing mechanism inside the
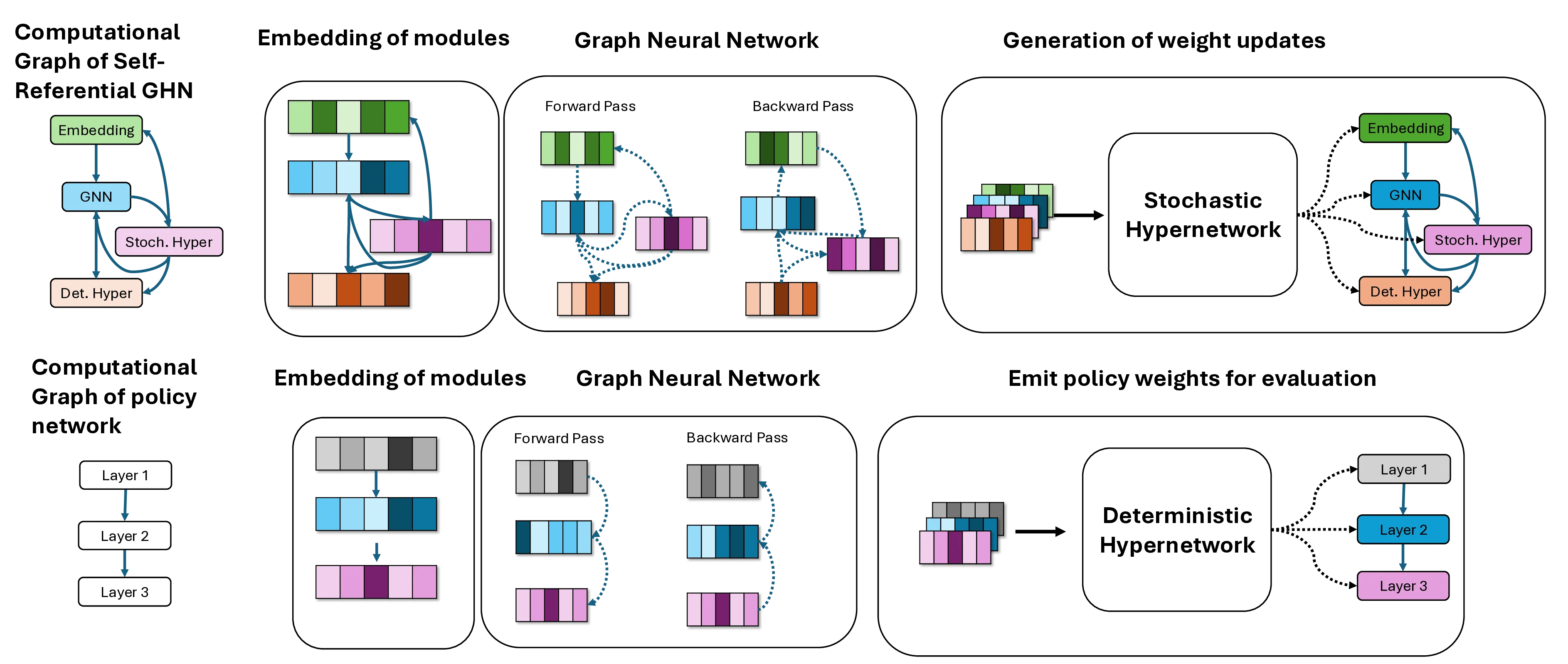
neural network itself. Building on Graph HyperNetworks
(GHNs) (Zhang et al., 2020) and prior self-referential sys-
tems (Schmidhuber, 1992a,b; Chang and Lipson, 2018; Ran-
dazzo et al., 2021), we introduce Self-Referential Graph Hy-
perNetworks: architectures that (i) generate parameter up-
dates to copies of themselves, (ii) inject stochastic, learn-
able variation into those parameters, and (iii) thereby enact
a localized mechanics for increasing and decreasing explo-
ration. See Figure 1 for a visual overview of the structure of
the self-referential GHN.
By internalizing evolution, Self-Referential GHNs realize
three key advantages:
1. Derivative-free optimisation of non-differentiable or dis-
crete architectures while remaining fully neural and end-
to-end trainable.
2. Rapid adaptation to non-stationary tasks, as demonstrated
by our CartPole-Switch and LunarLander-Switch exper-
arXiv:2512.16406v1 [cs.NE] 18 Dec 2025
Embedding
GNN
Stoch. Hyper
Det. Hyper
Stochastic
Hypernetwork
Embedding
GNN
Stoch. Hyper
Det. Hyper
Computational
Graph of Self-
Referential GHN
Embedding of modules
Graph Neural Network
Forward Pass
Backward Pass
Generation of weight updates
Layer 1
Computational
Graph of policy
network
Layer 2
Layer 3
Embedding of modules
Forward
…(Full text truncated)…
This content is AI-processed based on ArXiv data.