📝 Original Info
- Title: INTELLECT-3: Technical Report
- ArXiv ID: 2512.16144
- Date: 2025-12-18
- Authors: Researchers from original ArXiv paper
📝 Abstract
We present INTELLECT-3, a 106B-parameter Mixture-of-Experts model (12B active) trained with large-scale reinforcement learning on our end-to-end RL infrastructure stack. INTELLECT-3 achieves state of the art performance for its size across math, code, science and reasoning benchmarks, outperforming many larger frontier models. We open-source the model together with the full infrastructure stack used to create it, including RL frameworks, complete recipe, and a wide collection of environments, built with the verifiers library, for training and evaluation from our Environments Hub community platform. Built for this effort, we introduce prime-rl, an open framework for large-scale asynchronous reinforcement learning, which scales seamlessly from a single node to thousands of GPUs, and is tailored for agentic RL with first-class support for multi-turn interactions and tool use. Using this stack, we run both SFT and RL training on top of the GLM-4.5-Air-Base model, scaling RL training up to 512 H200s with high training efficiency.
💡 Deep Analysis
Deep Dive into INTELLECT-3: Technical Report.
We present INTELLECT-3, a 106B-parameter Mixture-of-Experts model (12B active) trained with large-scale reinforcement learning on our end-to-end RL infrastructure stack. INTELLECT-3 achieves state of the art performance for its size across math, code, science and reasoning benchmarks, outperforming many larger frontier models. We open-source the model together with the full infrastructure stack used to create it, including RL frameworks, complete recipe, and a wide collection of environments, built with the verifiers library, for training and evaluation from our Environments Hub community platform. Built for this effort, we introduce prime-rl, an open framework for large-scale asynchronous reinforcement learning, which scales seamlessly from a single node to thousands of GPUs, and is tailored for agentic RL with first-class support for multi-turn interactions and tool use. Using this stack, we run both SFT and RL training on top of the GLM-4.5-Air-Base model, scaling RL training up to
📄 Full Content
INTELLECT-3: Technical Report
Prime Intellect Team
Mika Senghaas
Fares Obeid
Sami Jaghouar
William Brown
Jack Min Ong
Daniel Auras∗
Matej Sirovatka
Jannik Straube
Andrew Baker
Sebastian Müller
Justus Mattern
Manveer Basra
Aiman Ismail
Dominik Scherm
Cooper Miller
Ameen Patel
Simon Kirsten
Mario Sieg
Christian Reetz
Kemal Erdem
Vincent Weisser
Johannes Hagemann†
Abstract
We present INTELLECT-3, a 106B-parameter Mixture-of-Experts model (12B active)
trained with large-scale reinforcement learning on our end-to-end RL infrastructure stack.
INTELLECT-3 achieves state of the art performance for its size across math, code, science
and reasoning benchmarks, outperforming many larger frontier models. We open-source the
model together with the full infrastructure stack used to create it, including RL frameworks,
complete recipe, and a wide collection of environments, built with the verifiers library,
for training and evaluation from our Environments Hub community platform.
Built for this effort, we introduce prime-rl, an open framework for large-scale asyn-
chronous reinforcement learning, which scales seamlessly from a single node to thousands
of GPUs, and is tailored for agentic RL with first-class support for multi-turn interactions
and tool use. Using this stack, we run both SFT and RL training on top of the GLM-4.5-
Air-Base model, scaling RL training up to 512 H200s with high training efficiency.
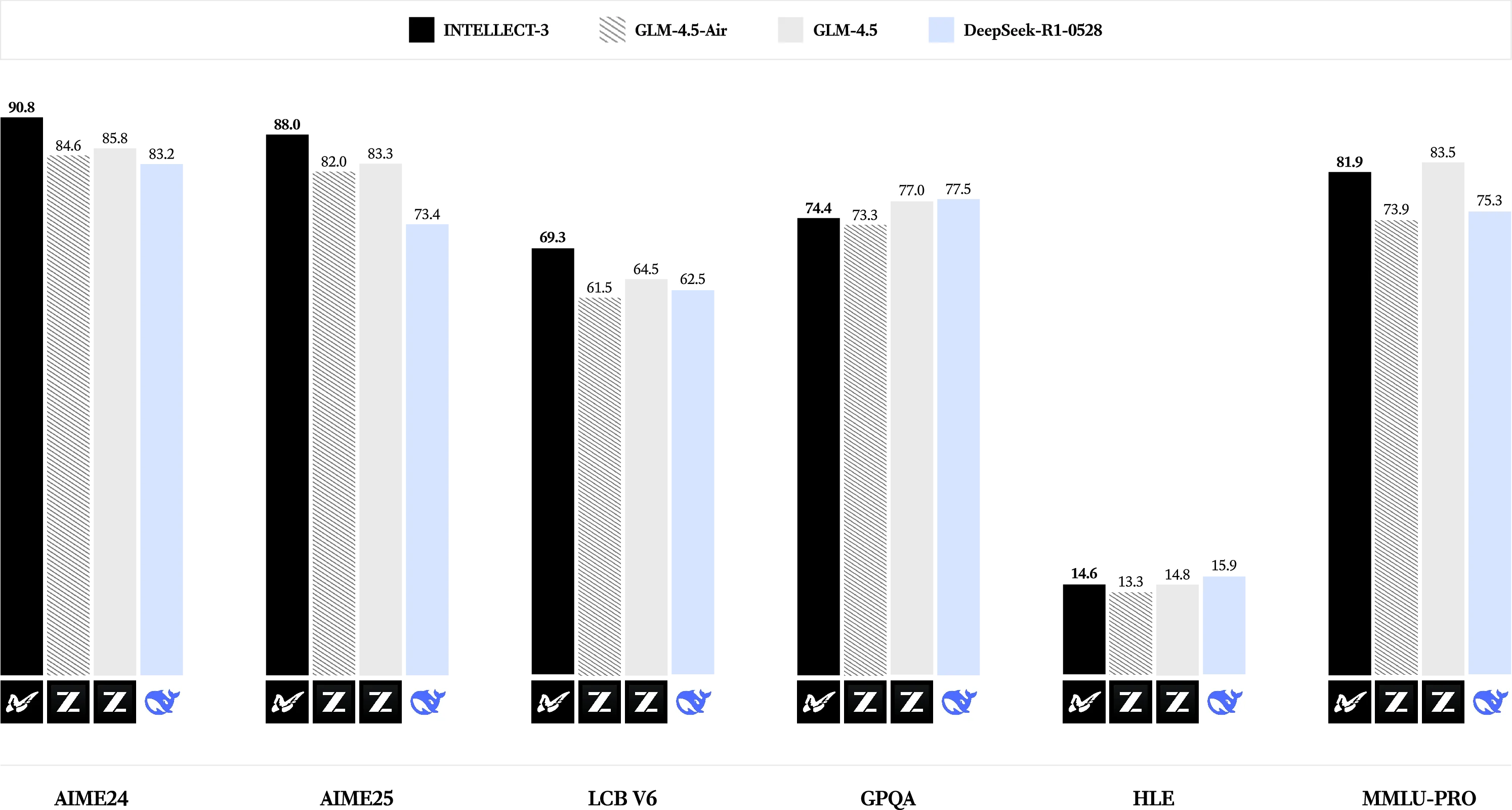
Intellect-3
GLM-4.5-Air
GLM-4.5
DeepSeek-R1-0528
90.8
84.6
85.8
83.2
88.0
82.0
83.3
73.4
69.3
61.5
64.5
62.5
74.4
73.3
77.0
77.5
14.6
13.3
14.8
15.9
81.9
73.9
83.5
75.3
aime24
aime25
LCB v6
GPQA
HLE
MMLU-PRO
Figure 1: INTELLECT-3 Evaluation Results.1
∗Partially while at ellamind
†Prime Intellect, Inc. Correspondence to: johannes@primeintellect.ai
arXiv:2512.16144v1 [cs.LG] 18 Dec 2025
Contents
1
Introduction
4
2
Training Infrastructure
4
2.1
prime-rl: A Framework for Asynchronous Reinforcement Learning at Scale . . . .
5
2.1.1
Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5
2.1.2
Asynchronous Off-Policy Training . . . . . . . . . . . . . . . . . . . . . .
6
2.1.3
Continuous Batching & In-Flight Weight Updates . . . . . . . . . . . . . .
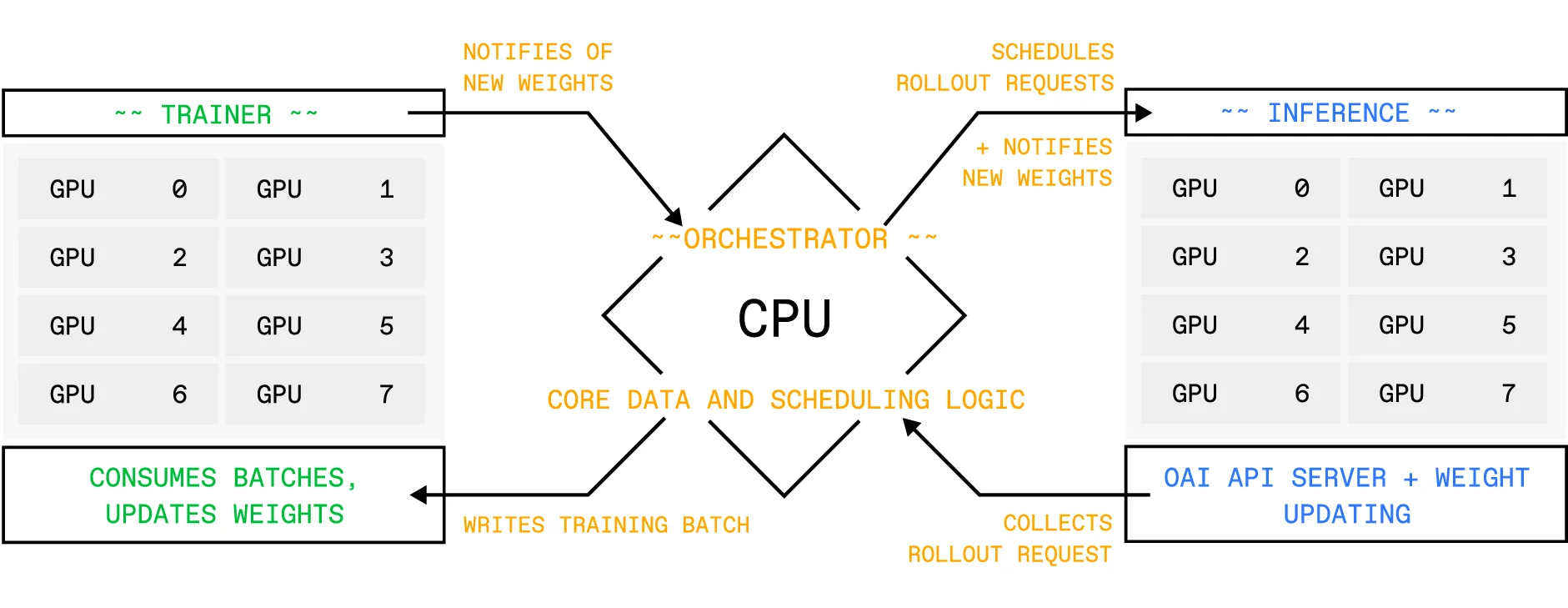
6
2.1.4
Multi-Client Orchestrator . . . . . . . . . . . . . . . . . . . . . . . . . . .
7
2.1.5
Online Data Filtering . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
7
2.1.6
Scaling Sequence Length . . . . . . . . . . . . . . . . . . . . . . . . . . .
7
2.1.7
Distributed Muon . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
8
2.1.8
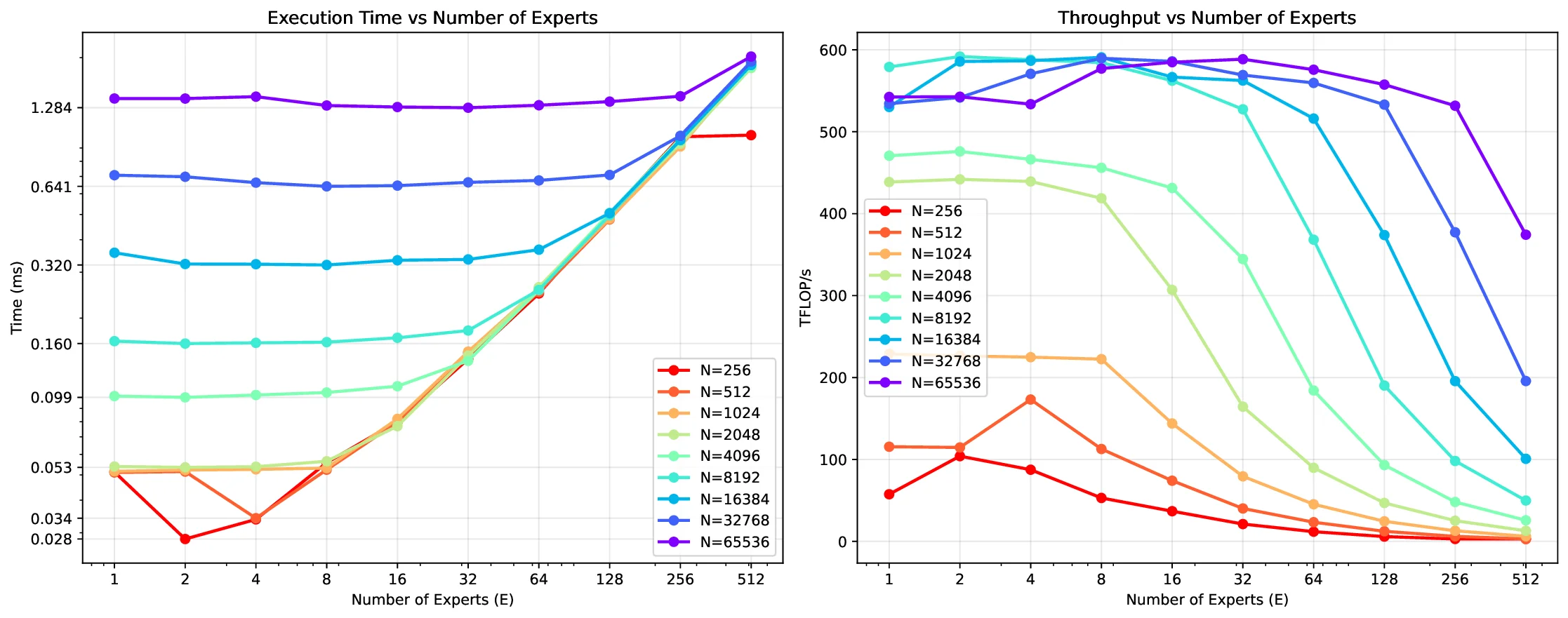
Efficient Mixture-of-Experts Support
. . . . . . . . . . . . . . . . . . . .
8
2.2
Verifiers: Environments for LLM Reinforcement Learning
. . . . . . . . . . . . .
9
2.2.1
Environment Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
9
2.2.2
Integration with prime-rl . . . . . . . . . . . . . . . . . . . . . . . . . .
10
2.2.3
Environments Hub . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
11
2.2.4
Evaluations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
11
2.3
Prime Sandboxes: Code Execution for RL Training . . . . . . . . . . . . . . . . .
11
2.3.1
The Limits of Naive Orchestration . . . . . . . . . . . . . . . . . . . . . .
11
2.3.2
Prime Sandboxes Architecture . . . . . . . . . . . . . . . . . . . . . . . .
11
2.3.3
Asynchronous Lifecycle Management . . . . . . . . . . . . . . . . . . . .
12
2.3.4
Image Distribution and Infrastructure Density . . . . . . . . . . . . . . . .
12
2.3.5
Security and Capabilities . . . . . . . . . . . . . . . . . . . . . . . . . . .
13
2.4
Compute Orchestration: Frontier GPU Infrastructure
. . . . . . . . . . . . . . . .
13
3
INTELLECT-3 Training
13
3.1
Environments Mix
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
13
3.1.1
Math
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
14
3.1.2
Code
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
14
3.1.3
Science . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
14
3.1.4
Logic . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
14
3.1.5
Deep Research . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
14
3.1.6
Software Engineering . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
15
3.2
Supervised Fine-Tuning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
15
3.3
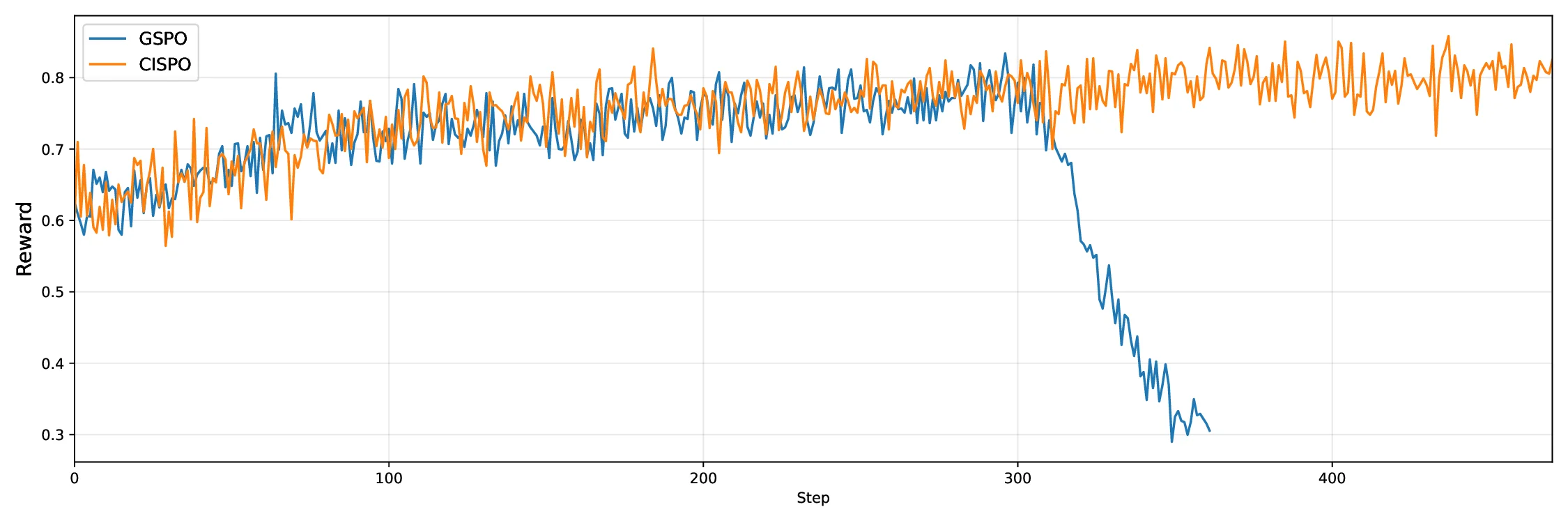
Reinforcement Learning
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
17
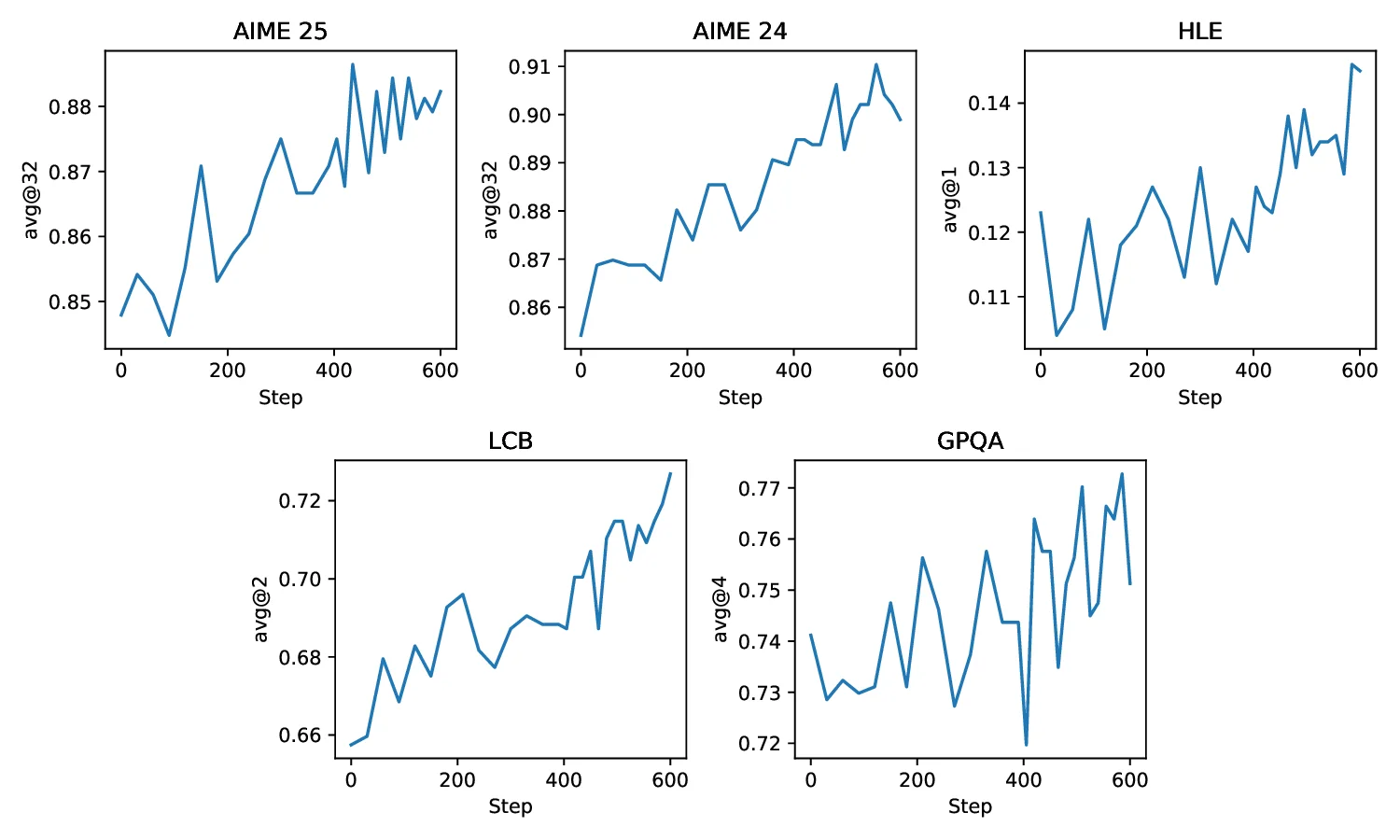
4
Evaluations
18
1All the models above were evaluated using our public, reproducible Environments Hub implementations.
To ensure the best results, we use APIs provided directly by the model creators whenever available to avoid any
performance loss from quantization or other inference optimizations.
2
5
Conclusion & Future Work
19
A Reproducing Evaluations
27
A.1
Evaluation Environments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
27
A.2 API models . . . . . . . .
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.