Multi-View Foundation Models
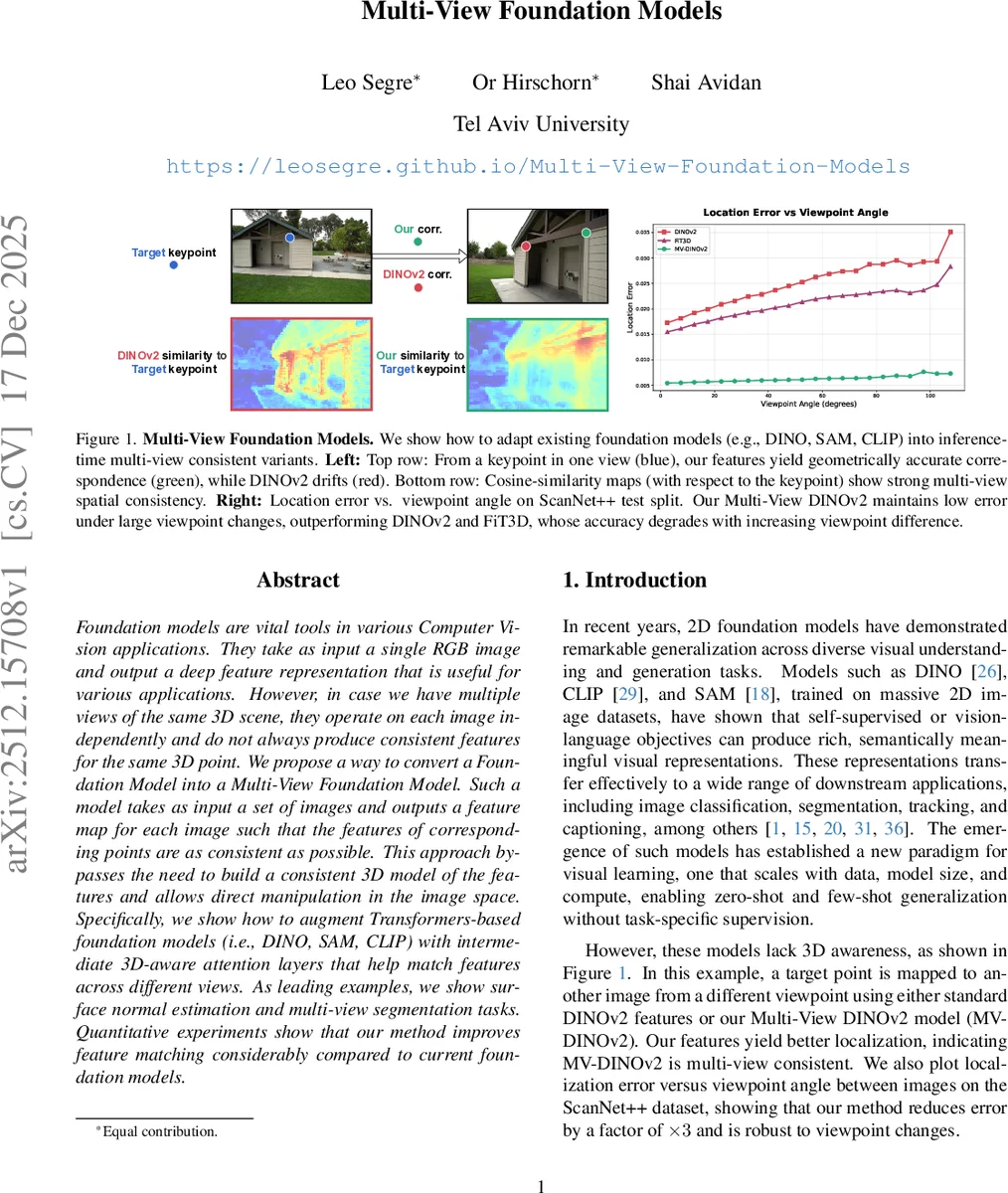
Foundation models are vital tools in various Computer Vision applications. They take as input a single RGB image and output a deep feature representation that is useful for various applications. However, in case we have multiple views of the same 3D scene, they operate on each image independently and do not always produce consistent features for the same 3D point. We propose a way to convert a Foundation Model into a Multi-View Foundation Model. Such a model takes as input a set of images and outputs a feature map for each image such that the features of corresponding points are as consistent as possible. This approach bypasses the need to build a consistent 3D model of the features and allows direct manipulation in the image space. Specifically, we show how to augment Transformers-based foundation models (i.e., DINO, SAM, CLIP) with intermediate 3D-aware attention layers that help match features across different views. As leading examples, we show surface normal estimation and multi-view segmentation tasks. Quantitative experiments show that our method improves feature matching considerably compared to current foundation models.
💡 Research Summary
This paper addresses a critical limitation in contemporary 2D foundation models like DINO, CLIP, and SAM: their lack of 3D geometric consistency. While these models produce powerful feature representations from single RGB images, they process multiple views of the same 3D scene independently, leading to inconsistent features for the same physical point across different viewpoints. To bridge this gap, the authors propose a novel and efficient framework for converting any Transformer-based 2D foundation model into a Multi-View Foundation Model (MVFM).
The core innovation is the introduction of lightweight “Multi-View Adapter” (MV-Adapter) modules inserted between the transformer blocks of a frozen, pre-trained backbone. During inference, the model takes in multiple images along with their camera poses. The adapters are conditioned on Plücker ray embeddings derived from the camera poses, which provide a pose-invariant geometric context. This allows the adapters to perform 3D-aware cross-attention operations, fusing information across different views to produce feature maps that are geometrically aligned. The adapters are initialized as zero-convolutions, ensuring the model initially behaves identically to the original foundation model. Training is parameter-efficient, involving fine-tuning only the adapter parameters and using LoRA for the backbone, which preserves the rich semantic priors of the pre-trained model.
A key challenge is avoiding feature collapse when enforcing consistency. Instead of a naive loss that directly minimizes distance between corresponding features, the method employs a geometry-aware dense correspondence loss. For a query point in one view, it computes a similarity map across all spatial locations in another view’s feature map. It then applies a softmax and a differentiable SoftArgMax to predict the corresponding pixel location. The loss minimizes the distance between this predicted location and the true location obtained from camera geometry. This forces the feature space to encode accurate geometric mappings rather than converging to a trivial constant. An additional regularization term maintains high cosine similarity and similar norm between the adapted features and the original foundation model’s features, preserving semantic fidelity.
Comprehensive experiments demonstrate the framework’s effectiveness. Evaluated on correspondence tasks using the ScanNet++ dataset and a diverse generalization benchmark, the proposed MVFMs (e.g., MV-DINOv2, MV-CLIP) significantly outperform the base foundation models and the recent inference-based method FiT3D in localization accuracy. Notably, the method maintains low error even under large viewpoint changes, whereas competitors degrade. The adapted features also retain high similarity to the original feature space. Qualitative results visually confirm the improved multi-view consistency of the feature similarity maps. Furthermore, the utility of these consistent features is validated on downstream 3D-aware tasks like surface normal estimation and multi-view semantic segmentation, where they enable more accurate predictions compared to single-view features.
In summary, this work presents a scalable, inference-time framework that imbues powerful 2D foundation models with 3D geometric consistency. It bypasses the need for costly per-scene optimization or explicit 3D reconstruction, offering a practical path towards unified representations that are both semantically rich and geometrically coherent, with broad applicability in robotics, AR/VR, and autonomous systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment