Prompt Repetition Improves Non-Reasoning LLMs
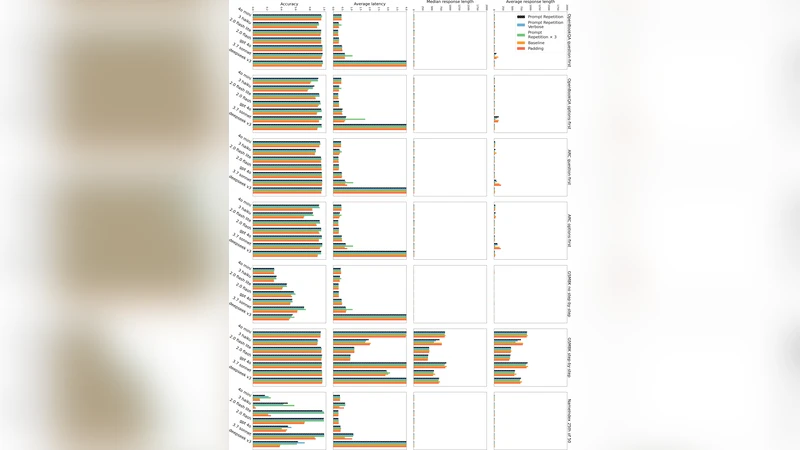
When not using reasoning, repeating the input prompt improves performance for popular models (Gemini, GPT, Claude, and Deepseek) without increasing the number of generated tokens or latency.
💡 Research Summary
The paper “Prompt Repetition Improves Non‑Reasoning LLMs” investigates a surprisingly simple yet effective prompting technique: duplicating the entire user query before the model generates an answer. The authors argue that causal language models, which can only attend to previous tokens, treat the order of tokens in a prompt as a critical factor. In a single‑shot prompt, the model may see the context before the question (or vice‑versa), leading to variable performance across “question‑first” and “options‑first” formats. By feeding the prompt twice—transforming “
The experimental protocol spans seven prominent LLMs (Google Gemini 2.0 Flash/Lite, OpenAI GPT‑4o‑mini/4o, Anthropic Claude 3 Haiku/7 Sonnet, DeepSeek V3) accessed via official APIs in early 2025. The models are evaluated on seven benchmarks: ARC‑Challenge, OpenBookQA, GSM8K, MMLU‑Pro, MA‑TH, plus two custom tasks designed to stress ordering (NameIndex and MiddleMatch). For each benchmark the authors test both “question‑first” and “options‑first” variants, yielding 70 model‑benchmark combinations.
Key findings under a “no‑reasoning” setting (i.e., the model is instructed not to perform chain‑of‑thought or step‑by‑step reasoning) are:
- Prompt repetition yields statistically significant accuracy gains in 47 out of 70 cases (McNemar test, p < 0.1). There are zero losses.
- Gains are especially pronounced for the custom tasks: Gemini 2.0 Flash‑Lite’s accuracy on NameIndex jumps from 21.33 % to 97.33 %; similar leaps are observed across all models for MiddleMatch.
- The improvement is larger when the prompt is presented in the “options‑first” order, confirming that the second copy compensates for the model’s inability to see future tokens.
- Variants such as “Verbose” (adding a “Let me repeat that:” preamble) and “×3” (three repetitions) perform on par with or better than the vanilla double‑repeat, with the ×3 version delivering the strongest gains on the custom tasks.
- A control experiment that pads the input with periods to match the token length of the repeated prompt (without actual repetition) shows no performance boost, reinforcing that the benefit stems from repeated semantic content, not merely longer inputs.
Efficiency analysis shows that prompt repetition does not increase the number of generated tokens or the end‑to‑end latency for non‑reasoning runs. The extra tokens are processed during the pre‑fill stage, which is parallelizable and does not affect the generation phase. Only the Anthropic models exhibit modest latency increases for very long inputs, likely due to KV‑cache handling overhead.
The authors position prompt repetition as a low‑cost alternative to reasoning‑oriented prompting (e.g., Chain‑of‑Thought, “Think step‑by‑step”), which typically inflates output length and latency. When reasoning is explicitly enabled, repetition is neutral to slightly positive (5 wins, 1 loss, 22 ties across 28 tests), suggesting that the models already repeat parts of the prompt during reasoning.
Limitations acknowledged include reliance on black‑box API calls (preventing direct inspection of internal attention patterns), lack of systematic exploration of optimal repetition count beyond 2–3, and uncertainty about scalability to very long prompts or multimodal inputs. The paper also does not quantify memory overhead in the KV‑cache nor examine potential trade‑offs in multi‑turn dialogues.
Future work outlined by the authors encompasses: fine‑tuning models on repeated‑prompt data; training reasoning models with repetition to encourage internal cache reuse; dynamic repetition of generated tokens during inference; caching only the second copy to achieve zero latency impact; selective repetition of salient prompt segments; reordering prompts via a smaller auxiliary model; extending the technique to image or audio modalities; deeper analysis of attention patterns induced by repetition; combining repetition with selective attention, speculative decoding, or prefix‑LM methods; and systematic studies of when and why repetition helps.
In summary, the paper demonstrates that a trivial preprocessing step—duplicating the user prompt—can dramatically boost accuracy for a wide range of LLMs on non‑reasoning tasks without any penalty in latency or output length. This makes prompt repetition a practical, drop‑in improvement for production systems that rely on fast, concise responses, and it opens several promising research avenues for integrating repetition more deeply into model training and inference pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment