📝 Original Info
- Title: 그래프 신경망 기반 강화학습을 활용한 라벨 전이 시스템 제어 합성
- ArXiv ID: 2512.15295
- Date: 2025-12-17
- Authors: Toshihide Ubukata, Enhong Mu, Takuto Yamauchi, Mingyue Zhang, Jialong Li, Kenji Tei
📝 Abstract
Controller synthesis is a formal method approach for automatically generating Labeled Transition System (LTS) controllers that satisfy specified properties. The efficiency of the synthesis process, however, is critically dependent on exploration policies. These policies often rely on fixed rules or strategies learned through reinforcement learning (RL) that consider only a limited set of current features. To address this limitation, this paper introduces GCRL, an approach that enhances RL-based methods by integrating Graph Neural Networks (GNNs). GCRL encodes the history of LTS exploration into a graph structure, allowing it to capture a broader, non-current-based context. In a comparative experiment against state-of-the-art methods, GCRL exhibited superior learning efficiency and generalization across four out of five benchmark domains, except one particular domain characterized by high symmetry and strictly local interactions.
💡 Deep Analysis
Deep Dive into 그래프 신경망 기반 강화학습을 활용한 라벨 전이 시스템 제어 합성.
Controller synthesis is a formal method approach for automatically generating Labeled Transition System (LTS) controllers that satisfy specified properties. The efficiency of the synthesis process, however, is critically dependent on exploration policies. These policies often rely on fixed rules or strategies learned through reinforcement learning (RL) that consider only a limited set of current features. To address this limitation, this paper introduces GCRL, an approach that enhances RL-based methods by integrating Graph Neural Networks (GNNs). GCRL encodes the history of LTS exploration into a graph structure, allowing it to capture a broader, non-current-based context. In a comparative experiment against state-of-the-art methods, GCRL exhibited superior learning efficiency and generalization across four out of five benchmark domains, except one particular domain characterized by high symmetry and strictly local interactions.
📄 Full Content
Graph Contextual Reinforcement Learning for
Efficient Directed Controller Synthesis
Toshihide Ubukata1, Enhong Mu2, Takuto Yamauchi1,
Mingyue Zhang2, Jialong Li1,3*, Kenji Tei3
1Waseda University, Tokyo, 169-8050, Japan.
2Southwest University, China.
3Institute of Science Tokyo, Tokyo, 152-8550, Japan.
*Corresponding author(s). E-mail(s): lijialong@fuji.waseda.jp;
Abstract
Controller synthesis is a formal method approach for automatically generating
Labeled Transition System (LTS) controllers that satisfy specified properties. The
efficiency of the synthesis process, however, is critically dependent on exploration
policies. These policies often rely on fixed rules or strategies learned through rein-
forcement learning (RL) that consider only a limited set of current features. To
address this limitation, this paper introduces GCRL, an approach that enhances
RL-based methods by integrating Graph Neural Networks (GNNs). GCRL
encodes the history of LTS exploration into a graph structure, allowing it to cap-
ture a broader, non-current-based context. In a comparative experiment against
state-of-the-art methods, GCRL exhibited superior learning efficiency and gen-
eralization across four out of five benchmark domains, except one particular
domain characterized by high symmetry and strictly local interactions.
Keywords: Directed Controller Synthesis, Exploration Policy, Labeled Transition
System, Graph Neural Networks
1 Introduction
In modern software engineering, it is essential that complex systems are not only func-
tional but also provably correct. This is especially critical in safety-sensitive domains
such as aerospace [1] and railway systems, where failures can have severe consequences.
Controller synthesis [2, 3] is a key formal method that addresses this challenge by
1
arXiv:2512.15295v1 [cs.AI] 17 Dec 2025
automatically generating a controller—typically represented as a Labeled Transition
System (LTS)—that is guaranteed to satisfy specified properties, such as safety, with
respect to a given model of its environment. The appeal of this approach lies in its abil-
ity to produce correct-by-construction systems, automating a particularly challenging
aspect of system design [4].
Despite its advantages, a major barrier to the practical adoption of controller syn-
thesis is the state-space explosion problem. The total number of system states can grow
exponentially with the number of components and the complexity of the specifica-
tions, making it infeasible to construct and explore the entire state space. To mitigate
this issue, on-the-fly Directed Controller Synthesis (DCS) [5] offers a promising alter-
native. Rather than constructing the full state space in advance, DCS incrementally
explores only the relevant portions needed to synthesize a correct controller, thereby
managing the exponential growth more effectively.
The effectiveness of DCS, however, hinges on the design of its exploration
policy—the strategy that determines which frontier state to examine next. A well-
designed exploration policy acts as an effective heuristic, efficiently steering the search
toward promising regions of the state space and away from unproductive ones, thus
reducing synthesis costs. Conversely, a poor policy may direct the search into irrelevant
areas, wasting time and computational resources. To improve exploration strategies,
recent research has applied Reinforcement Learning (RL) to automatically learn effec-
tive policies [6]. By framing policy design as an RL problem, a learning agent can
discover strategies that outperform manually crafted heuristics.
However, current RL-based approaches suffer from a critical limitation: they base
decisions almost exclusively on local features of immediate successor states. This is
analogous to an explorer navigating a forest using only what’s visible in front of
them—able to evaluate nearby terrain but unaware of the broader trails already
explored or where they might lead. As a result, the RL agent lacks contextual aware-
ness and cannot leverage information from its exploration history, such as recurring
structural patterns or early indicators of dead ends. This contextual blindness signif-
icantly limits the agent’s ability to learn informed, forward-looking DCS exploration
policies.
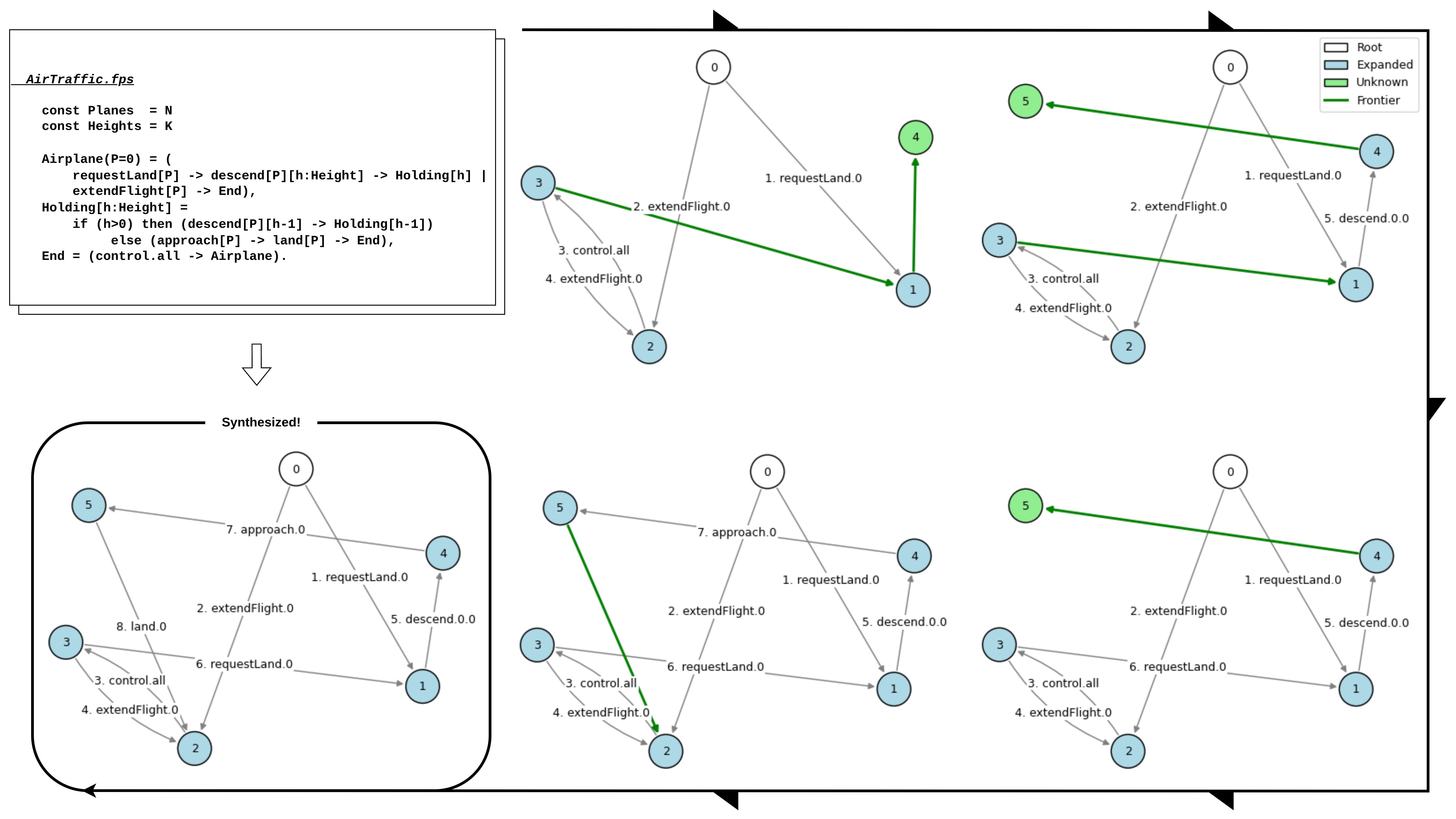
To overcome this limitation, we propose Graph Contextual Reinforcement Learning
(GCRL)—an approach that incorporates structural information from the exploration
history into the decision-making process. The core idea of GCRL is to model the
already explored portion of the LTS as a graph at each decision point, and then encode
and process this graph using Graph Neural Networks (GNNs) [7]. GNNs can aggregate
information across the graph, producing rich node embeddings that capture both local
and global relationships, as well as structural patterns over time. This gives the RL
agent a bird’s-eye view of the explored space, enabling it to make decisions informed
by both current and historical context
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.