📝 Original Info
📝 Abstract
Current tool-using AI agents suffer from limited action space, context inefficiency, and probabilistic instability that makes them unsuitable for handling repetitive tasks which are otherwise reliably and efficiently tackled by agentic workflows built on platforms like n8n [12] and Zapier [8] . Earlier works like CodeAct [15], DynaSaur [13], Code Mode [4] have tried to tackle the first two issues by using the whole Python language as its action space: The number of tools that the agent can call becomes infinite. Python code blocks can execute complex actions into a single step and print only relevant results which helps in keeping the context lean. However, the probabilistic instability issue still remains, as for the same task in the same environment, the agent can follow different trajectories due to the probabilistic nature of LLMs. Therefore, we need procedural memory for consistency and reliability. This paper proposes CodeMem, an architecture to implement procedural memory via code which can be used to build and run reusable agentic workflows with deterministic reliability.
💡 Deep Analysis
Deep Dive into CodeMem: Architecting Reproducible Agents via Dynamic MCP and Procedural Memory.
Current tool-using AI agents suffer from limited action space, context inefficiency, and probabilistic instability that makes them unsuitable for handling repetitive tasks which are otherwise reliably and efficiently tackled by agentic workflows built on platforms like n8n [12] and Zapier [8] . Earlier works like CodeAct [15], DynaSaur [13], Code Mode [4] have tried to tackle the first two issues by using the whole Python language as its action space: The number of tools that the agent can call becomes infinite. Python code blocks can execute complex actions into a single step and print only relevant results which helps in keeping the context lean. However, the probabilistic instability issue still remains, as for the same task in the same environment, the agent can follow different trajectories due to the probabilistic nature of LLMs. Therefore, we need procedural memory for consistency and reliability. This paper proposes CodeMem, an architecture to implement procedural memory vi
📄 Full Content
CodeMem: Architecting Reproducible Agents via
Dynamic MCP and Procedural Memory
Nishant Gaurav
nishant@agentr.dev
Adit Akarsh
adit@agentr.dev
Tejas Ravishankar
tejas@agentr.dev
Manoj Bajaj
manoj@agentr.dev
Abstract
Current tool-using AI agents suffer from limited action space, context inefficiency,
and probabilistic instability that makes them unsuitable for handling repetitive
tasks which are otherwise reliably and efficiently tackled by agentic workflows
built on platforms like n8n [12] and Zapier [8]. Earlier works like CodeAct [15],
DynaSaur [13], Code Mode [4] have tried to tackle the first two issues by using
the whole Python language as its action space: The number of tools that the agent
can call becomes infinite. Python code blocks can execute complex actions into
a single step and print only relevant results which helps in keeping the context
lean. However, the probabilistic instability issue still remains, as for the same
task in the same environment, the agent can follow different trajectories due to
the probabilistic nature of LLMs. Therefore, we need procedural memory for
consistency and reliability. This paper proposes CodeMem, an architecture to
implement procedural memory via code which can be used to build and run reusable
agentic workflows with deterministic reliability.
1
Introduction
Tool-using language agents have evolved from single-shot chatbots into complex systems capable of
planning and state management. Frameworks like CoALA emphasize that capable agents require
structured memory, rich action spaces, and iterative decision-making loops [14]. However, most
production architectures still rely on token-heavy, tool-centric interaction patterns where the LLM
micromanages every step. This paper proposes CodeMem, an architecture that reframes the LLM as
an architect of executable workflows. Instead of standard chat-based tool calling, the agent utilizes a
sandbox to write, validate, and save successful logic into a persistent procedural memory bank. This
approach solves the reproducibility crisis inherent in probabilistic models by shifting complex logic
from volatile context windows into deterministic code.
The plan for the rest of the paper is as follows. We first summarize the relevant literature which
form the basis for CodeMem (in Section 2). Then we dive deeper into the benefits of CodeAct over
ReAct which establishes that Code is the right format for capturing procedures (in Section 3). The
next Section covers the key bottlenecks which must be solved (in Section 4). Section 5 proposes
the CodeMem Architecture which overcomes the key bottlenecks specified in the previous section.
In Section 6, we show how CodeMem creates procedural memory with a real-world case-study.
Section 7 shows experiments which prove the benefits of CodeMem quantitatively. Finally we
summarize the findings in Section 8.
Preprint.
arXiv:2512.15813v1 [cs.SE] 17 Dec 2025
2
Related Work
2.1
Procedural Memory in Theory
The CoALA framework organizes agent memory into working, episodic, semantic, and procedural
categories [14]. While working memory (context) and semantic memory (RAG) are well-solved,
procedural memory (implicit knowledge of how to execute tasks) remains a bottleneck. The paper
suggests three possible approaches for capturing procedural memory in AI Agents:
1. Rewriting the code of the Agent
2. Editing the weights of the LLMs
3. Editing the instructions of the AI Agent
Theoretically both these approaches make sense, but practical implementations are still missing.
LangGraph, a popular agentic framework, calls this out in their documentation:
“In practice, it is fairly uncommon for agents to modify their model weights or
rewrite their code. However, it is more common for agents to modify their own
prompts.” [9]
2.2
Implementing Procedural Memory via Meta Prompting
Frameworks like LangGraph distinguish between short-term memory (thread-scoped checkpoints)
and long-term memory (cross-thread persistence) [10].
Short-Term:
LangGraph effectively manages conversation state (i.e. the messages history, includ-
ing human, AI, and tool messages) via checkpoints. All kinds of memory (semantic, episodic, and
procedural) can be captured in short term memory but there is no guarantee that the agent will utilize
this memory reliably. That’s why we need long term memory.
Long-Term:
For capturing semantic and episodic memory we can leverage RAG and there are
several open-source projects (e.g. Graphiti [6], LightRAG [7]) which are getting used in production.
However, capturing procedural memory is still an underexplored topic. LangGraph conceptualizes
procedural updates primarily as modifications to graph topology or just the system instructions (e.g.,
“update the prompt to handle X better next time”) [9].
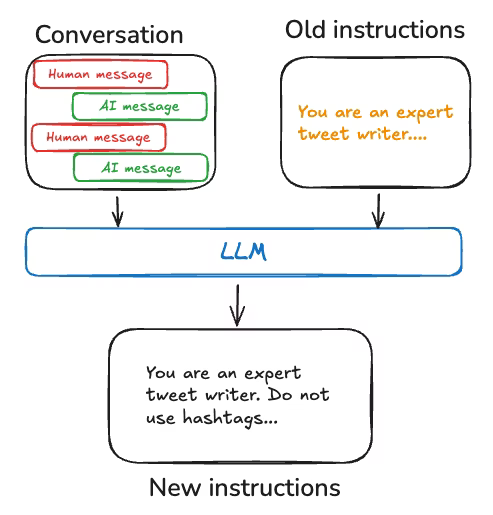
For example, the LangGraph team built a Tweet generator using external feedback and prompt re-
writing to produce high-quality paper summaries for Twitter. In this case, the specific summarization
prompt was diff
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.