LCMem: A Universal Model for Robust Image Memorization Detection
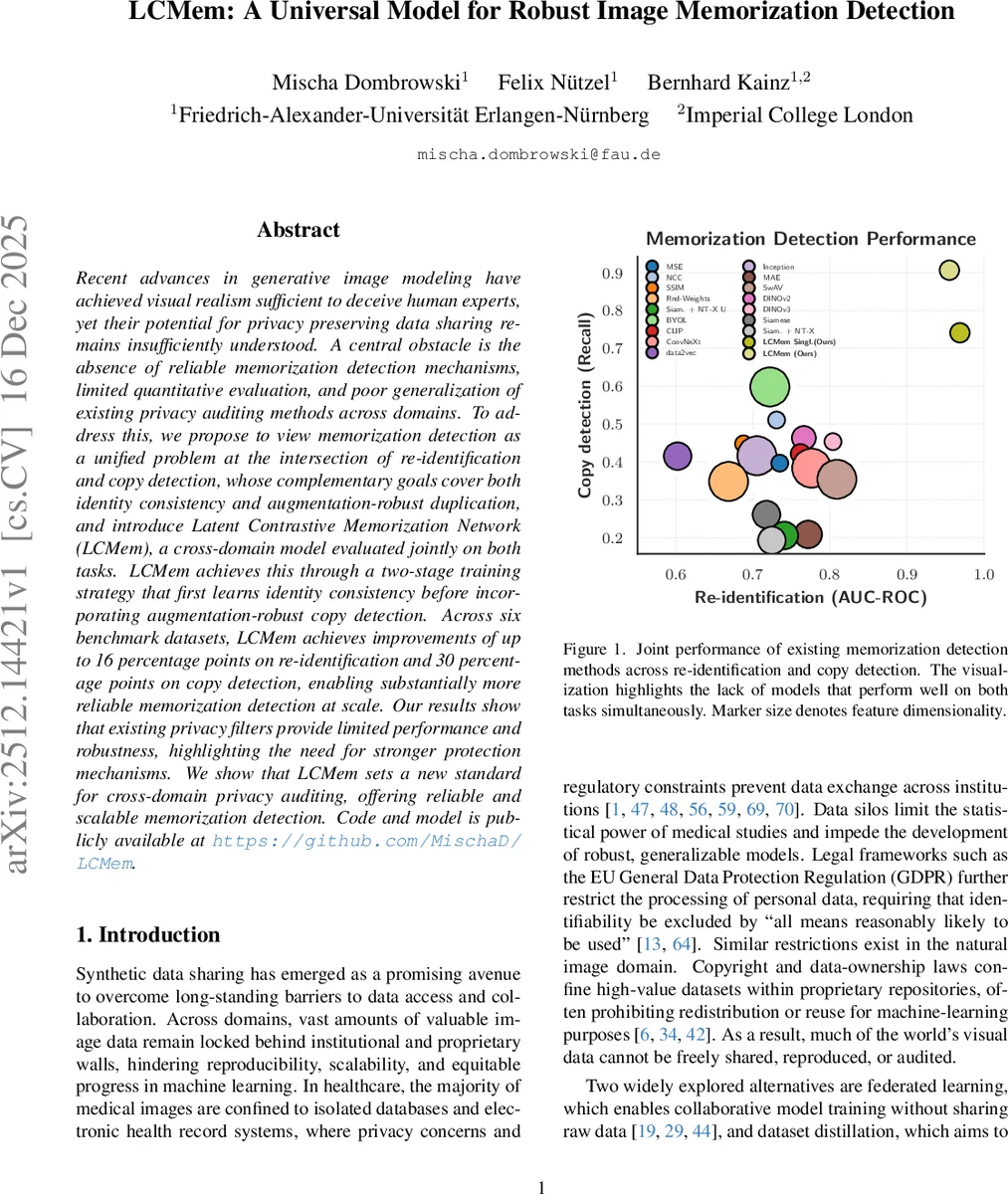
Recent advances in generative image modeling have achieved visual realism sufficient to deceive human experts, yet their potential for privacy preserving data sharing remains insufficiently understood. A central obstacle is the absence of reliable memorization detection mechanisms, limited quantitative evaluation, and poor generalization of existing privacy auditing methods across domains. To address this, we propose to view memorization detection as a unified problem at the intersection of re-identification and copy detection, whose complementary goals cover both identity consistency and augmentation-robust duplication, and introduce Latent Contrastive Memorization Network (LCMem), a cross-domain model evaluated jointly on both tasks. LCMem achieves this through a two-stage training strategy that first learns identity consistency before incorporating augmentation-robust copy detection. Across six benchmark datasets, LCMem achieves improvements of up to 16 percentage points on re-identification and 30 percentage points on copy detection, enabling substantially more reliable memorization detection at scale. Our results show that existing privacy filters provide limited performance and robustness, highlighting the need for stronger protection mechanisms. We show that LCMem sets a new standard for cross-domain privacy auditing, offering reliable and scalable memorization detection. Code and model is publicly available at https://github.com/MischaD/LCMem.
💡 Research Summary
Paper Overview
The authors address a pressing privacy issue in modern generative image models: the risk that synthetic images unintentionally replicate training data, thereby leaking personal or copyrighted content. Existing detection methods treat re‑identification (determining whether two images depict the same underlying instance) and copy detection (recognizing an augmented version of an image) as separate problems, evaluate on a single dataset, and fail to generalize across domains. This work proposes a unified formulation that simultaneously satisfies both objectives, and introduces a novel model—Latent Contrastive Memorization Network (LCMem)—that operates in the latent space of diffusion models and is trained in two distinct stages to first master identity consistency and then acquire augmentation‑robust duplication detection.
Key Contributions
- Unified Problem Definition – The paper formalizes memorization detection as a joint task that requires both strict identity matching (re‑identification) and robustness to common augmentations (copy detection).
- Latent‑Space Architecture – By leveraging the pretrained autoencoder from a latent diffusion model (SDv2), images are compressed from pixel space (e.g., 512 × 512 × 3) to a low‑dimensional latent (64 × 64 × 4). This reduces memory consumption by a factor of 64, speeds up training, and removes high‑frequency noise irrelevant for identity matching.
- Two‑Stage Training Strategy –
- Stage 1: Trains a Siamese ConvNeXt‑Tiny backbone on clean latent pairs using a combined loss that mixes binary cross‑entropy (BCE) for re‑identification with a contrastive NT‑Xent term. The model focuses solely on learning accurate identity embeddings.
- Stage 2: Introduces strong image‑space augmentations (color jitter, rotations, crops, etc.), encodes the augmented images back into latent space, and fine‑tunes the entire network. The contrastive component now enforces that augmented views of the same instance remain close, while the BCE component continues to sharpen the binary decision boundary.
The final loss is L_final = α·L_contrastive + (1‑α)·L_BCE, where α balances identity clustering against classification accuracy.
- Efficient Retrieval – Because the Siamese branches process each image independently, feature vectors for all real images can be pre‑computed and stored. During inference, copy detection reduces to a simple nearest‑neighbor lookup in the latent feature atlas, enabling fast, scalable privacy audits.
- Extensive Cross‑Domain Evaluation – Six benchmark datasets spanning medical imaging (e.g., chest X‑ray, OCT) and natural images (CIFAR‑10, ImageNet subsets) are used. Metrics include AU‑ROC for re‑identification (with a strict 1 % false‑negative budget, i.e., 99 % recall) and recall for copy detection (thresholded to achieve 95 % recall on validation). LCMem outperforms all baselines, achieving up to 16 percentage‑point gains in AU‑ROC and 30 percentage‑point gains in recall.
- Memorization Rate Measurement – The authors train a pseudo‑conditional diffusion model to generate synthetic counterparts for each real image, then apply LCMem to assess whether the generated sample is deemed a duplicate. LCMem identifies a substantially higher proportion of memorized outputs than traditional similarity metrics (MSE, SSIM, CLIP, etc.).
Technical Insights
- Latent Contrastive Learning: By applying NT‑Xent directly on latent embeddings, the model learns augmentation‑invariant clusters without needing explicit data‑level augmentations during the first stage. This circumvents the instability that would arise from augmenting latent vectors directly.
- ConvNeXt‑Tiny Backbone: Replacing ResNet with ConvNeXt‑Tiny yields better parameter efficiency and higher representational capacity, which is crucial when operating on compressed latent maps.
- Joint Loss Design: The combination of a contrastive term (encouraging intra‑class compactness) and a binary classification term (ensuring a calibrated decision threshold) is essential; ablation studies show that using either loss alone degrades either re‑identification or copy detection performance.
- Scalability: Pre‑computing latents and features enables the model to handle millions of real images with modest GPU memory, making it suitable for large‑scale privacy audits in industry settings.
Limitations & Future Directions
- Augmentation in Latent Space: Many common augmentations cannot be applied directly to latent tensors, requiring a round‑trip through the decoder and encoder, which adds computational overhead. Developing latent‑aware augmentations could further streamline Stage 2.
- Label Dependence: The re‑identification stage relies on explicit identity labels (patient IDs, creator IDs, etc.). For fully unlabeled datasets, performance may drop; future work could explore self‑supervised clustering or proxy labels.
- Multi‑Modal Extension: Current work focuses on image‑image pairs. Extending the framework to handle text‑image or audio‑image pairs would broaden applicability to multimodal generative models.
Impact
LCMem sets a new benchmark for privacy‑preserving synthetic data pipelines. By providing a single model that simultaneously guarantees high‑precision re‑identification and robust copy detection across diverse domains, it enables regulators, data custodians, and AI developers to audit generated content with confidence. The publicly released code and pretrained weights facilitate immediate adoption, and the methodological advances (latent‑space contrastive learning, two‑stage training) are likely to inspire further research in secure generative modeling and cross‑domain similarity learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment