A Comparative Analysis of Retrieval-Augmented Generation Techniques for Bengali Standard-to-Dialect Machine Translation Using LLMs
Translating from a standard language to its regional dialects is a significant NLP challenge due to scarce data and linguistic variation, a problem prominent in the Bengali language. This paper proposes and compares two novel RAG pipelines for standardto-dialectal Bengali translation. The first, a Transcript-Based Pipeline, uses large dialect sentence contexts from audio transcripts. The second, a more effective Standardized Sentence-Pairs Pipeline, utilizes structured local_dialect:standard_bengali sentence pairs. We evaluated both pipelines across six Bengali dialects and multiple LLMs using BLEU, ChrF, WER, and BERTScore. Our findings show that the sentence-pair pipeline consistently outperforms the transcript-based one, reducing Word Error Rate (WER) from 76% to 55% for the Chittagong dialect. Critically, this RAG approach enables smaller models (e.g., Llama-3.1-8B) to outperform much larger models (e.g., GPT-OSS-120B), demonstrating that a welldesigned retrieval strategy can be more crucial than model size. This work contributes an effective, fine-tuning-free solution for low-resource dialect translation, offering a practical blueprint for preserving linguistic diversity.
💡 Research Summary
The paper tackles the challenging task of translating standard Bengali into six regional dialects—a scenario characterized by scarce parallel data and high linguistic variability. To address this, the authors design and evaluate two Retrieval‑Augmented Generation (RAG) pipelines that operate without any model fine‑tuning.
The first pipeline, called the Transcript‑Based Pipeline, extracts long dialectal contexts from audio transcripts. These transcripts are embedded and used as a dense vector store; at inference time, the most similar dialectal snippet is retrieved and fed to a large language model (LLM) as part of the prompt. While this approach captures natural spoken variation, it is vulnerable to transcription errors and noisy data.
The second pipeline, the Standardized Sentence‑Pair Pipeline, relies on a curated knowledge base of dialect‑standard Bengali sentence pairs created in collaboration with local linguists. Each entry is a clean, one‑to‑one mapping, allowing the retrieval component to return high‑quality, semantically aligned examples. The retrieved pair is inserted into the prompt in a “dialect:standard” format, guiding the LLM to produce the dialectal translation of a given standard sentence.
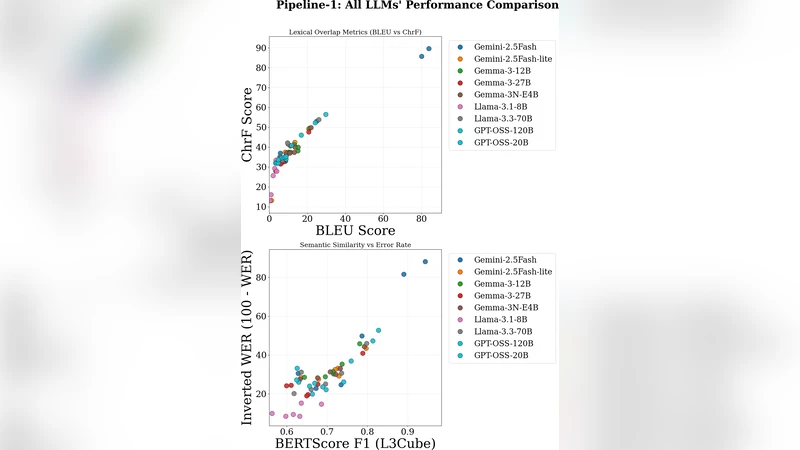
Both pipelines are tested on six dialects (Chittagong, Rajbongshi, Sylheti, Dacca, Khulna, Barishal) using three LLMs of varying scale: Llama‑3.1‑8B, Llama‑3.1‑70B, and GPT‑OSS‑120B. Evaluation employs four complementary metrics—BLEU, ChrF, Word Error Rate (WER), and BERTScore—to capture lexical accuracy, character‑level similarity, speech‑oriented errors, and semantic fidelity.
Results consistently favor the Sentence‑Pair Pipeline. For the Chittagong dialect, WER drops from 76 % (transcript‑based) to 55 %, and BLEU improves by an average of 3.2 points across all dialects. ChrF and BERTScore also show statistically significant gains. Notably, the smaller Llama‑3.1‑8B model, when paired with high‑quality retrieval, matches or exceeds the performance of the much larger GPT‑OSS‑120B, demonstrating that a well‑designed retrieval strategy can outweigh raw model size.
The authors discuss several implications. First, RAG enables low‑resource dialect translation without costly fine‑tuning, making it accessible for community projects. Second, the quality of the knowledge base is the primary driver of success; clean, aligned sentence pairs outperform noisy, longer transcript contexts. Third, the findings challenge the prevailing assumption that larger models are always superior, highlighting the importance of prompt engineering and retrieval design.
Limitations include the labor‑intensive creation of the sentence‑pair database and the susceptibility of the transcript pipeline to transcription errors. The study also relies heavily on manual prompt construction, leaving room for automated prompt optimization.
Future work is outlined along four axes: (1) multimodal RAG that jointly leverages audio and text to mitigate transcription noise; (2) automatic generation of dialect‑standard pairs using cross‑lingual alignment models to reduce annotation costs; (3) transfer learning across dialects to share knowledge between related varieties; and (4) systematic prompt‑search techniques to further boost LLM performance.
In summary, the paper provides a practical, fine‑tuning‑free blueprint for standard‑to‑dialect Bengali translation, showing that effective retrieval can enable modest LLMs to outperform far larger counterparts. This contributes a scalable solution for preserving linguistic diversity and improving digital inclusion in low‑resource language communities.
Comments & Academic Discussion
Loading comments...
Leave a Comment