Cog-RAG: Cognitive-Inspired Dual-Hypergraph with Theme Alignment Retrieval-Augmented Generation
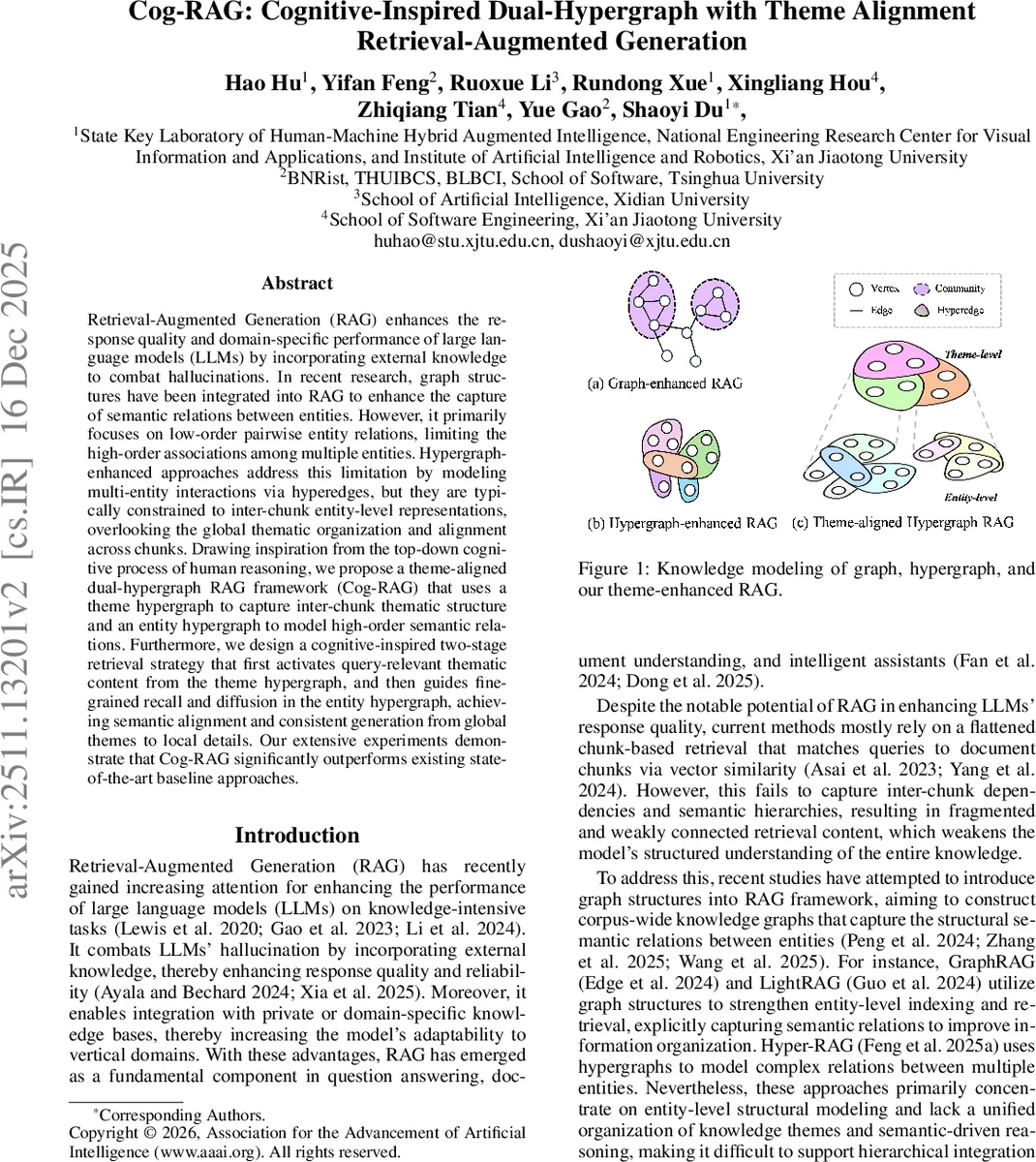
Retrieval-Augmented Generation (RAG) enhances the response quality and domain-specific performance of large language models (LLMs) by incorporating external knowledge to combat hallucinations. In recent research, graph structures have been integrated into RAG to enhance the capture of semantic relations between entities. However, it primarily focuses on low-order pairwise entity relations, limiting the high-order associations among multiple entities. Hypergraph-enhanced approaches address this limitation by modeling multi-entity interactions via hyperedges, but they are typically constrained to inter-chunk entity-level representations, overlooking the global thematic organization and alignment across chunks. Drawing inspiration from the top-down cognitive process of human reasoning, we propose a theme-aligned dual-hypergraph RAG framework (Cog-RAG) that uses a theme hypergraph to capture inter-chunk thematic structure and an entity hypergraph to model high-order semantic relations. Furthermore, we design a cognitive-inspired two-stage retrieval strategy that first activates query-relevant thematic content from the theme hypergraph, and then guides fine-grained recall and diffusion in the entity hypergraph, achieving semantic alignment and consistent generation from global themes to local details. Our extensive experiments demonstrate that Cog-RAG significantly outperforms existing state-of-the-art baseline approaches.
💡 Research Summary
Cog‑RAG introduces a cognitively inspired Retrieval‑Augmented Generation (RAG) architecture that simultaneously models global thematic structure and fine‑grained multi‑entity relations using a dual‑hypergraph. Traditional RAG pipelines either flatten documents into independent chunks and rely on vector similarity, or they enrich retrieval with a knowledge graph that captures only pairwise entity links. Both approaches miss higher‑order associations among multiple entities and lack a unified representation of the document’s overarching themes, leading to fragmented context and potential hallucinations in large language model (LLM) outputs.
The proposed system builds two complementary hypergraphs. The theme hypergraph captures inter‑chunk thematic organization. Documents are first split into overlapping chunks; a large language model, guided by prompts (P_ext_theme, P_ext_key), extracts a concise “theme label” for each chunk and a set of key entities that embody that theme. The theme label becomes a hyperedge, while the key entities serve as vertices. This structure explicitly encodes the narrative flow across the whole corpus, mirroring the human tendency to first identify a high‑level problem theme before diving into details.
The entity hypergraph operates within each chunk. Using another set of prompts (P_ext_entity, P_ext_low, P_ext_high), the model extracts all entities and constructs two types of hyperedges: low‑order (pairwise) edges (E_low) and high‑order edges (E_high) that connect three or more entities to represent complex semantic patterns such as co‑occurrence in events, causal chains, or shared attributes. By preserving these high‑order links, the entity hypergraph avoids the information loss typical of graph‑only methods that reduce multi‑entity interactions to a series of binary edges.
Retrieval follows a two‑stage, top‑down cognitive process. Stage 1 – Theme‑aware retrieval: From the user query, a set of theme keywords (X_theme) is generated via LLM prompting (P_keyword). These keywords are matched against the theme hypergraph to retrieve the most relevant theme hyperedges (E_rel). A diffusion step gathers neighboring key‑entity vertices (V_dif), providing a contextually enriched, theme‑centric knowledge set. The LLM then produces an initial answer A_theme that reflects the global thematic anchor.
Stage 2 – Entity‑aligned retrieval: Using A_theme as a guide, the system extracts concrete entity keywords (X_entity) with a dedicated prompt (P_align). These keywords are matched to vertices in the entity hypergraph, retrieving the top‑k relevant entities (V_rel). A second diffusion gathers surrounding high‑order hyperedges (E_dif), delivering detailed relational information that aligns with the previously identified theme. Finally, the LLM receives a combined input comprising the original query, A_theme, V_rel, E_dif, and their textual contexts, and generates the final answer A. This pipeline ensures semantic alignment across granularity levels: global themes steer the retrieval of local details, and detailed evidence reinforces the thematic narrative.
Empirical evaluation spans five datasets from two benchmarks: UltraDomain (Mix, CS, Agriculture) covering heterogeneous domains, and MIRA‑GE (Neurology, Pathology) focusing on medical QA. Metrics include accuracy, precision, recall, F1, BLEU, and ROUGE. Cog‑RAG consistently outperforms state‑of‑the‑art baselines such as GraphRAG, LightRAG, and Hi‑RAG, achieving average gains of 6–12 percentage points. Notably, on the Neurology dataset, the model shows substantial improvements in “theme‑detail consistency,” indicating that the generated answers maintain a coherent storyline while providing precise medical facts. The approach also generalizes across different LLM backbones (Claude‑2, GPT‑4, LLaMA‑2), confirming its robustness.
The paper acknowledges several limitations. First, the quality of theme and entity extraction heavily depends on handcrafted prompts; suboptimal prompts can degrade hypergraph construction. Second, building and diffusing over dual hypergraphs incurs higher memory and computational costs, which may hinder scalability to corpora of tens of gigabytes without further optimization. Third, the current pipeline assumes a static knowledge base; dynamic updates would require incremental hypergraph maintenance mechanisms.
Future work directions include: (i) automated prompt optimization or self‑supervised fine‑tuning to improve extraction reliability; (ii) hypergraph compression, sampling, or hierarchical indexing to reduce computational overhead; (iii) extending the framework to multimodal hypergraphs that integrate text, tables, and images; and (iv) incorporating interactive human‑LLM feedback loops where users can refine theme or entity cues on the fly, further aligning the system with human reasoning patterns.
In summary, Cog‑RAG offers a novel, cognitively motivated architecture that bridges the gap between high‑level thematic comprehension and low‑level factual detail in retrieval‑augmented generation. By leveraging dual hypergraphs and a two‑stage retrieval process, it markedly improves the factual accuracy, coherence, and explanatory power of LLM‑driven systems, setting a new benchmark for knowledge‑rich, hallucination‑resistant generation.
Comments & Academic Discussion
Loading comments...
Leave a Comment