The AI Productivity Index (APEX)
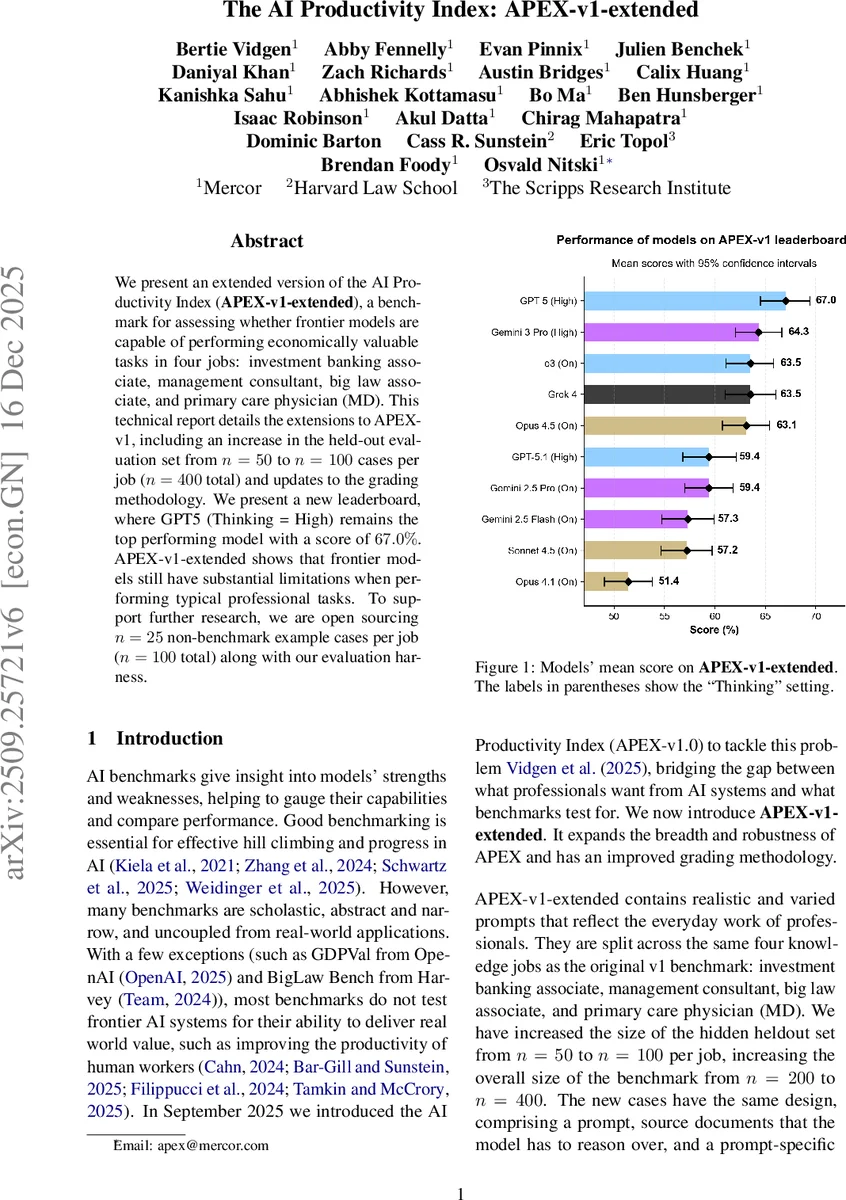
We present an extended version of the AI Productivity Index (APEX-v1-extended), a benchmark for assessing whether frontier models are capable of performing economically valuable tasks in four jobs: investment banking associate, management consultant, big law associate, and primary care physician (MD). This technical report details the extensions to APEX-v1, including an increase in the held-out evaluation set from n = 50 to n = 100 cases per job (n = 400 total) and updates to the grading methodology. We present a new leaderboard, where GPT5 (Thinking = High) remains the top performing model with a score of 67.0%. APEX-v1-extended shows that frontier models still have substantial limitations when performing typical professional tasks. To support further research, we are open sourcing n = 25 non-benchmark example cases per role (n = 100 total) along with our evaluation harness.
💡 Research Summary
The paper introduces APEX‑v1‑extended, an expanded benchmark designed to evaluate whether frontier large language models (LLMs) can perform economically valuable tasks in four professional domains: investment‑banking associate, management consultant, big‑law associate, and primary‑care physician. Compared with the original APEX‑v1.0, the new version doubles the hidden test set to 100 cases per job (400 total) and releases an open‑source development set of 25 cases per job (100 total) under a CC‑BY license. Each case consists of a realistic prompt, a set of source documents (PDF, XLSX, TXT, DOCX, CSV) limited to 100 000 tokens, and a rubric containing on average 14.8 objective criteria. The prompts are authored by 137 domain experts with an average of seven years of professional experience; each expert spent roughly 2.7 hours (range 0.5–20 h) to craft and validate a prompt.
Methodologically, the authors make three major changes to the evaluation pipeline. First, they replace the multi‑judge panel used in APEX‑v1.0 with a single LLM judge, Gemini 2.5 Flash, to improve transparency and reduce evaluation time. Second, each model’s response to a prompt is sampled eight times (instead of three) and the mean score is used, allowing a more stable estimate of performance. Third, they report 95 % confidence intervals alongside mean percentages, and they conduct statistical tests (Friedman omnibus test, pairwise t‑tests with Bonferroni correction) to assess significance. All models are queried with “Thinking” turned on and set to “High” where available, and temperature is fixed at 0.7.
Ten frontier models from OpenAI, Anthropic, Google DeepMind, and xAI are evaluated. GPT‑5 (Thinking = High) achieves the highest overall mean score of 67.0 %, followed by Gemini 3 Pro (64.3 %) and Grok 4 (63.5 %). Performance varies by job: the law domain yields the highest scores (up to 77.9 % for GPT‑5), while investment banking is the most challenging (top score 63 %). The Friedman test confirms that differences among models are highly significant (p < 0.000001). Z‑score analysis further highlights GPT‑5’s advantage (0.50) over the next best model (Opus 4.5, 0.28), especially on the hardest tasks.
A comparison between the hidden test set and the open development set shows only minor rank shifts; most models differ by 1–2 percentage points, though a few (GPT‑5.1, Gemini 2.5 Flash, Sonnet 4.5) lose more than 10 points on the development set, indicating sensitivity to data distribution.
The authors acknowledge several limitations: (1) the rubric, while objective, still reflects expert judgment and may retain bias; (2) reliance on a single LLM judge could propagate systematic errors; (3) the benchmark evaluates only single‑turn responses, omitting multi‑turn interaction, real‑time decision making, and collaborative workflows that are common in professional settings. They propose future work to incorporate multi‑judge ensembles, multi‑turn scenarios, and new metrics that capture model‑human collaboration efficiency.
In conclusion, APEX‑v1‑extended provides a rigorous, scalable framework for measuring AI productivity in high‑stakes professional tasks. The results demonstrate that even the most advanced models still fall short of human‑level competence across many real‑world tasks, underscoring the need for continued model improvements and more sophisticated evaluation ecosystems before AI can reliably augment professional productivity.
Comments & Academic Discussion
Loading comments...
Leave a Comment