Exo2Ego: Exocentric Knowledge Guided MLLM for Egocentric Video Understanding
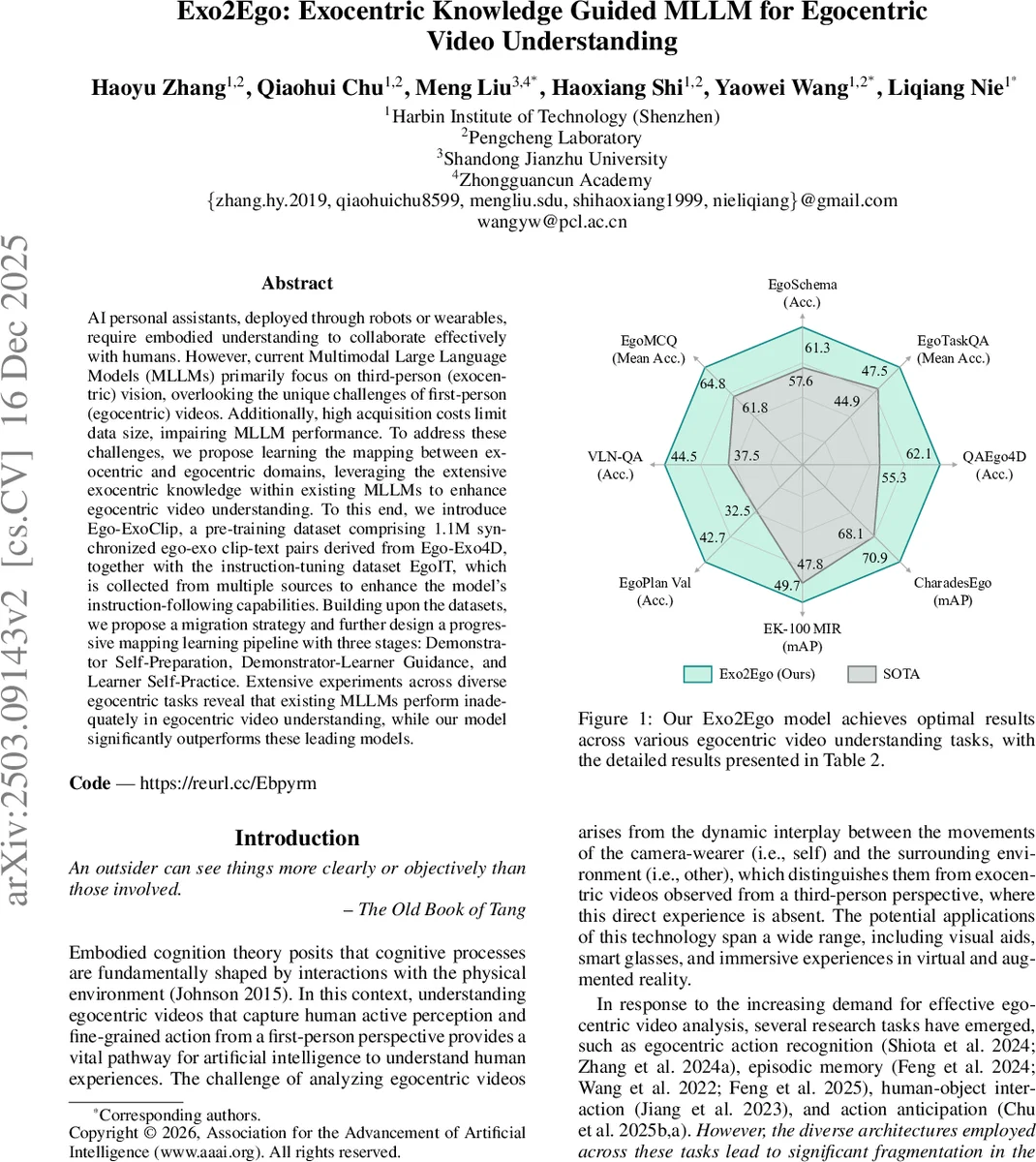
AI personal assistants, deployed through robots or wearables, require embodied understanding to collaborate effectively with humans. However, current Multimodal Large Language Models (MLLMs) primarily focus on third-person (exocentric) vision, overlooking the unique challenges of first-person (egocentric) videos. Additionally, high acquisition costs limit data size, impairing MLLM performance. To address these challenges, we propose learning the mapping between exocentric and egocentric domains, leveraging the extensive exocentric knowledge within existing MLLMs to enhance egocentric video understanding. To this end, we introduce Ego-ExoClip, a pre-training dataset comprising 1.1M synchronized ego-exo clip-text pairs derived from Ego-Exo4D, together with the instruction-tuning dataset EgoIT, which is collected from multiple sources to enhance the model’s instruction-following capabilities. Building upon the datasets, we propose a migration strategy and further design a progressive mapping learning pipeline with three stages: Demonstrator Self-Preparation, Demonstrator-Learner Guidance, and Learner Self-Practice. Extensive experiments across diverse egocentric tasks reveal that existing MLLMs perform inadequately in egocentric video understanding, while our model significantly outperforms these leading models.
💡 Research Summary
The paper addresses a critical gap in current multimodal large language models (MLLMs): while they excel at processing third‑person (exocentric) visual data, they struggle with first‑person (egocentric) video understanding, a capability essential for embodied AI assistants deployed on robots or wearable devices. The authors argue that the scarcity and high acquisition cost of egocentric video data limit the training of large‑scale models, and that directly transferring unpaired exocentric videos introduces bias and instability. Inspired by cognitive science findings that humans learn by observing others (exocentric view) and mapping those observations onto their own experience (egocentric view), they propose a “demonstrator‑learner” framework that explicitly learns a bidirectional mapping between the two visual domains.
To enable this, two new datasets are constructed. Ego‑ExoClip is a pre‑training corpus of 1.1 million synchronized ego‑exocentric clip‑text pairs derived from the Ego‑Exo4D collection. The authors filter the original 5,035 video groups down to 2,925 high‑quality groups, then expand timestamp‑level narrations into clip‑level descriptions using a data‑driven temporal window (average tempo β and scale factor α = 1.92 s). This yields 623.6 hours of video and 261.3 K narrations, ensuring each narration aligns with a single clip. EgoIT is an instruction‑tuning dataset of roughly 600 K samples, each consisting of a video path, a task instruction, a question, and an answer. Using GPT‑4o, ten diverse instruction variants are generated per source dataset, covering three task families: (1) action recognition (EGTEA, Something‑Something‑V2), (2) question answering (EgoTimeQA, OpenEQA), and (3) captioning (EgoExoLearn).
Training proceeds in four phases. First, the exocentric and egocentric visual encoders are separately pre‑trained on large web video‑text corpora (for the exocentric encoder) and EgoClip (for the egocentric encoder), while the language model (LLM) remains frozen. This yields strong initial visual representations for each domain.
Stage 1 – Demonstrator Self‑Preparation: the exocentric encoder (the “demonstrator”) is fine‑tuned on the exocentric side of Ego‑ExoClip using a vision‑grounded text generation (VTG) loss. The LLM stays frozen, ensuring the demonstrator learns to generate accurate textual descriptions from exocentric clips.
Stage 2 – Demonstrator‑Learner Guidance: the demonstrator encoder is frozen, and the egocentric encoder (the “learner”) along with two mapping functions F : X→Y (ego → exo) and G : Y→X (exo → ego) are jointly optimized. Because F alone is under‑constrained, the authors enforce bijectivity by coupling it with G and applying a cycle‑consistency loss (CCL): L_CCL = E_x
Comments & Academic Discussion
Loading comments...
Leave a Comment