📝 Original Info
- Title: Dynamic Learning Rate Scheduling based on Loss Changes Leads to Faster Convergence
- ArXiv ID: 2512.14527
- Date: 2025-12-16
- Authors: Shreyas Subramanian, Bala Krishnamoorthy, Pranav Murthy
📝 Abstract
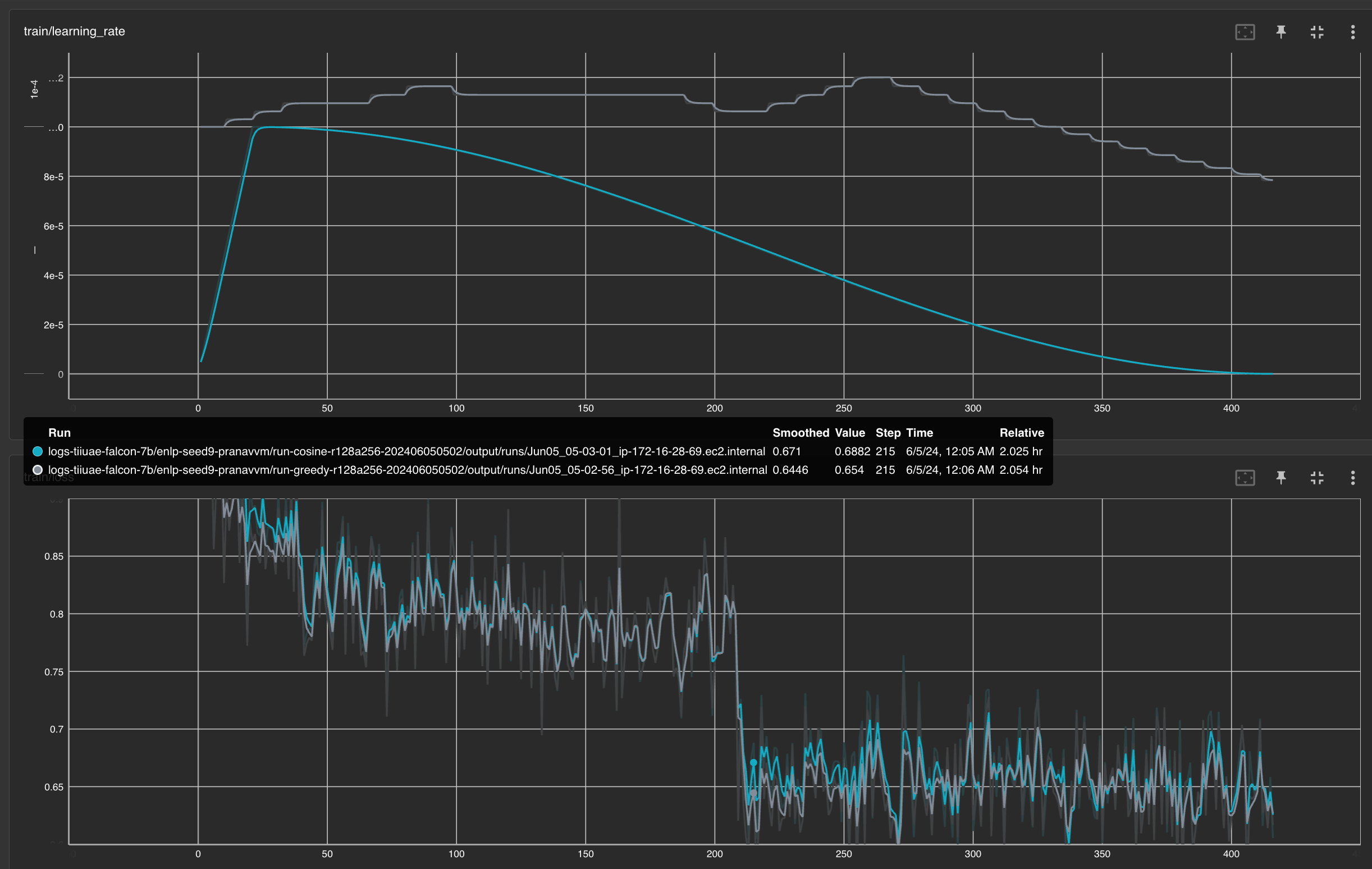
Despite significant advances in optimizers for training, most research works use common scheduler choices like Cosine or exponential decay. In this paper, we study \emph{GreedyLR}, a novel scheduler that adaptively adjusts the learning rate during training based on the current loss. To validate the effectiveness of our proposed scheduler, we conduct experiments on several NLP, CV, and LLM tasks with up to $7B$ parameters, including both fine-tuning and pre-training experiments. The results show that our approach outperforms several state-of-the-art schedulers in terms of accuracy, speed, and convergence. We also provide a theoretical analysis of the GreedyLR algorithm, including a proof of convergence and derivation of the optimal scaling factor $F$ that maximizes the convergence rate, along with experiments to show robustness of the algorithm to realistic noisy landscapes. Our scheduler is easy to implement, computationally efficient, and could be considered a good default scheduler for training.
💡 Deep Analysis
Deep Dive into Dynamic Learning Rate Scheduling based on Loss Changes Leads to Faster Convergence.
Despite significant advances in optimizers for training, most research works use common scheduler choices like Cosine or exponential decay. In this paper, we study \emph{GreedyLR}, a novel scheduler that adaptively adjusts the learning rate during training based on the current loss. To validate the effectiveness of our proposed scheduler, we conduct experiments on several NLP, CV, and LLM tasks with up to $7B$ parameters, including both fine-tuning and pre-training experiments. The results show that our approach outperforms several state-of-the-art schedulers in terms of accuracy, speed, and convergence. We also provide a theoretical analysis of the GreedyLR algorithm, including a proof of convergence and derivation of the optimal scaling factor $F$ that maximizes the convergence rate, along with experiments to show robustness of the algorithm to realistic noisy landscapes. Our scheduler is easy to implement, computationally efficient, and could be considered a good default scheduler f
📄 Full Content
Dynamic Learning Rate Scheduling based on Loss Changes Leads to Faster
Convergence
Shreyas Subramanian
Amazon Web Services
Seattle, Washington
subshrey@amazon.com
Bala Krishnamoorthy
Amazon Web Services
Seattle, Washington
bkrism@amazon.com
Pranav Murthy
Amazon Web Services
Seattle, Washington
pranavvm@amazon.com
Abstract
Despite significant advances in optimizers for
training, most research works use common
scheduler choices like Cosine or exponential de-
cay. In this paper, we study GreedyLR, a novel
scheduler that adaptively adjusts the learning
rate during training based on the current loss.
To validate the effectiveness of our proposed
scheduler, we conduct experiments on several
NLP, CV, and LLM tasks with up to 7B pa-
rameters, including both fine-tuning and pre-
training experiments. The results show that
our approach outperforms several state-of-the-
art schedulers in terms of accuracy, speed, and
convergence. We also provide a theoretical
analysis of the GreedyLR algorithm, includ-
ing a proof of convergence and derivation of
the optimal scaling factor F that maximizes
the convergence rate, along with experiments
to show robustness of the algorithm to realis-
tic noisy landscapes. Our scheduler is easy
to implement, computationally efficient, and
could be considered a good default scheduler
for training.
1
Introduction
Selecting a learning rate (LR) scheduler for train-
ing is important, but is often done with minimal
thought. Many recent works default to using spe-
cific LR schedulers such as the Cosine Annealing
scheduler, frequently without a strong technical
justification for their choice.
As a first form of changing learning rates adap-
tively through training, several adaptive optimiza-
tion methods have been proposed, such as Adam
(Adaptive Moment Estimation) (Kingma and Ba,
2014) and RMSProp (Root Mean Square Propaga-
tion), which dynamically adjust the learning rate
based on gradients and the history of updates. How-
ever, these adaptive optimizers often underperform
in practice with their default settings (Wilson et al.,
2017; Macêdo et al., 2021). Techniques proposed
by (Vaswani et al., 2019; Armijo, 1966) aim to de-
termine the optimal LR at each training step by
treating it as a line search problem. These methods
still use a fixed, predetermined schedule.
The main drawback of fixed schedules is their
generality, which prevents adaptation to the spe-
cific characteristics of the optimization problem or
the model architecture. Different problems and ar-
chitectures often require distinct LR schedules for
optimal performance. Therefore, there is a press-
ing need for a learning rate scheduler that is both
simple and adaptable to the specific optimization
problem.
There is a growing trend towards using learning
rate schedules that adjust the LR during training. In
our work, we propose a novel and simple scheduler
called GreedyLR, which adaptively chooses the
learning rate. Our contributions are as follows:
1. We conduct a variety of experiments from
small models to Large Language Models
(LLMs) with billions of parameters to validate
performance of the scheduler across model
scalses, use cases and datasets
2. We demonstrate GreedyLR’s effectiveness
across both fine-tuning and pre-training
paradigms,
establishing its utility as a
general-purpose scheduler for diverse training
scenarios
3. We study critical hyperparameters, as well as
the robustness of the scheduler to simulated
noisy environments to encourage using
GreedyLR as a default scheduler choice in
training experiments.
arXiv:2512.14527v1 [cs.AI] 16 Dec 2025
2
Related Work
The scheduling of learning rates is a critical factor
in the training of deep neural networks (DNNs), in-
fluencing both convergence speed and final model
performance. (Macêdo et al., 2021; Dauphin et al.,
2014) suggest that neural network training occurs
in phases, advocating for different learning rates at
each phase to facilitate convergence. (Smith and
Topin, 2017; Smith, 2015) employ cyclical varia-
tions of the learning rate based on preset heuristics
to improve training dynamics. (Nakamura et al.,
2021) propose a novel annealing schedule com-
bining a sigmoid function with a warmup phase
that maintains large learning rates during early and
middle training stages while smoothing transitions
to avoid abrupt changes in step size. (Yedida and
Saha, 2019) derive a theoretical framework for dy-
namically computing learning rates based on the
Lipschitz constant of the loss function, though their
experiments indicate challenges in generalizing
across architectures like ResNets. (Khodamoradi
et al., 2021a) introduce an Adaptive Scheduler for
Learning Rate (ASLR) that requires minimal hy-
perparameter tuning and adapts based on validation
error trends, reducing computational burden while
remaining effective across various network topolo-
gies. (Kim et al., 2021) propose an automated
scheduler combining adaptive warmup and prede-
fined decay phases for large-batch t
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.