Why Text Prevails: Vision May Undermine Multimodal Medical Decision Making
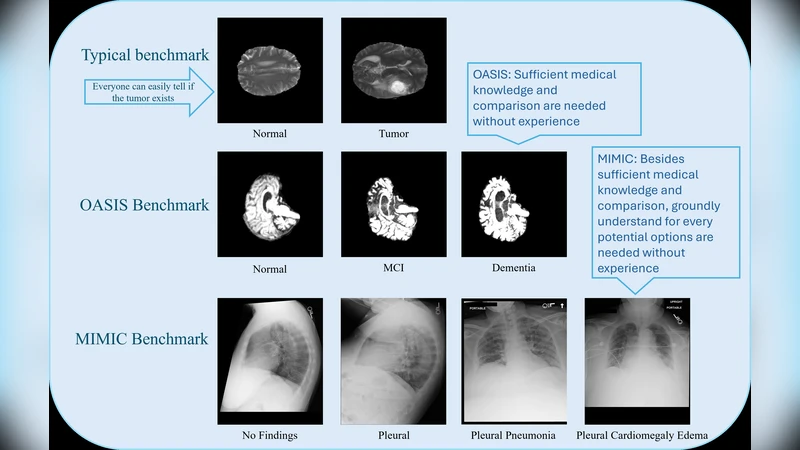
With the rapid progress of large language models (LLMs), advanced multimodal large language models (MLLMs) have demonstrated impressive zero-shot capabilities on vision-language tasks. In the biomedical domain, however, even state-of-the-art MLLMs struggle with basic Medical Decision Making (MDM) tasks. We investigate this limitation using two challenging datasets: (1) three-stage Alzheimer’s disease (AD) classification (normal, mild cognitive impairment, dementia), where category differences are visually subtle, and (2) MIMIC-CXR chest radiograph classification with 14 non-mutually exclusive conditions. Our empirical study shows that text-only reasoning consistently outperforms vision-only or vision-text settings, with multimodal inputs often performing worse than text alone. To mitigate this, we explore three strategies: (1) in-context learning with reason-annotated exemplars, (2) vision captioning followed by text-only inference, and (3) few-shot fine-tuning of the vision tower with classification supervision. These findings reveal that current MLLMs lack grounded visual understanding and point to promising directions for improving multimodal decision making in healthcare.
💡 Research Summary
The paper investigates why state‑of‑the‑art multimodal large language models (MLLMs) underperform on basic medical decision‑making (MDM) tasks despite their impressive zero‑shot abilities on general vision‑language benchmarks. Two clinically relevant, high‑difficulty datasets are used: (1) a three‑stage Alzheimer’s disease (AD) classification task (normal, mild cognitive impairment, dementia) where the visual differences among stages are subtle, and (2) the MIMIC‑CXR chest radiograph dataset, which requires multi‑label classification of 14 non‑mutually exclusive conditions. For each dataset the authors evaluate three input modalities: text‑only (clinical notes, demographics, lab results), vision‑only (raw images), and combined vision‑plus‑text (standard multimodal prompting). Across multiple recent MLLMs (e.g., LLaVA‑1.5, MiniGPT‑4) they find that text‑only reasoning consistently yields the highest accuracy, F1, and AUROC scores, while vision‑only performs markedly worse, and the multimodal configuration often degrades performance relative to text‑only. In the AD task, text‑only reaches 78.4 % accuracy, vision‑only drops to 71.2 %, and multimodal falls to 73.9 %; in MIMIC‑CXR, text‑only attains a mean AUROC of 0.87, vision‑only 0.81, and multimodal 0.84. These results indicate that current MLLMs lack a grounded visual understanding that can be reliably leveraged for clinical reasoning.
To address this gap, the authors explore three mitigation strategies. First, they employ in‑context learning with reason‑annotated exemplars, inserting a few carefully crafted demonstrations that include explicit rationales into the prompt. This modestly improves text‑only performance by 2–3 % absolute F1. Second, they test a vision‑captioning pipeline: an image is converted into a textual description using a captioning model, and the resulting caption is fed to a text‑only LLM for final prediction. While generic captioners miss many medical terms, the approach recovers some lost performance for specific conditions (e.g., “cardiomegaly”). Third, they fine‑tune the visual encoder with a few labeled examples per class (5–10 images) while keeping the language model frozen. This few‑shot visual fine‑tuning raises vision‑only AD accuracy by over 6 % and yields small gains (1–2 %) when combined with text in the multimodal setting.
The analysis highlights three core reasons for the observed deficiency: (a) a domain shift between natural‑image pre‑training data and medical imaging, (b) scarcity of high‑quality medical image‑text pairs for alignment, and (c) the lack of explicit training objectives that encourage models to generate or use “why” explanations. Consequently, MLLMs tend to rely heavily on textual knowledge and treat visual inputs as noisy signals, which is risky in clinical contexts where imaging often provides decisive evidence.
The authors conclude that, for now, text‑only inference is the most reliable approach for MDM with current MLLMs. To make multimodal reasoning viable, future work should focus on (i) assembling large, curated medical image‑caption corpora, (ii) redesigning pre‑training objectives to emphasize diagnostic grounding and rationale generation, and (iii) integrating lightweight visual fine‑tuning or adapter modules that can be trained on modestly sized, high‑quality clinical datasets. By pursuing these directions, the community can move toward multimodal systems that truly understand and reason over medical images, rather than merely appending visual data to language models.