CoRA: A Collaborative Robust Architecture with Hybrid Fusion for Efficient Perception
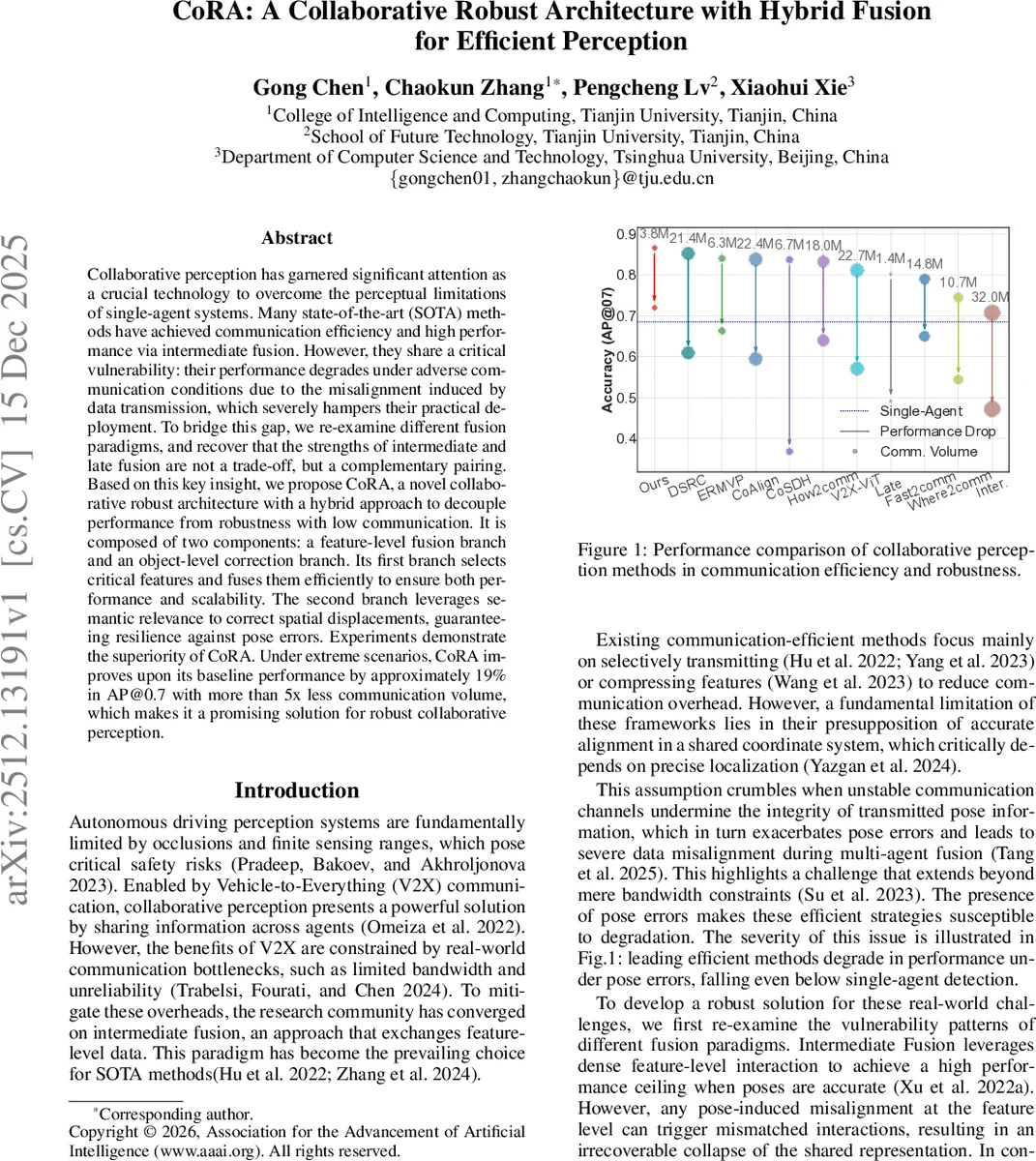
Collaborative perception has garnered significant attention as a crucial technology to overcome the perceptual limitations of single-agent systems. Many state-of-the-art (SOTA) methods have achieved communication efficiency and high performance via intermediate fusion. However, they share a critical vulnerability: their performance degrades under adverse communication conditions due to the misalignment induced by data transmission, which severely hampers their practical deployment. To bridge this gap, we re-examine different fusion paradigms, and recover that the strengths of intermediate and late fusion are not a trade-off, but a complementary pairing. Based on this key insight, we propose CoRA, a novel collaborative robust architecture with a hybrid approach to decouple performance from robustness with low communication. It is composed of two components: a feature-level fusion branch and an object-level correction branch. Its first branch selects critical features and fuses them efficiently to ensure both performance and scalability. The second branch leverages semantic relevance to correct spatial displacements, guaranteeing resilience against pose errors. Experiments demonstrate the superiority of CoRA. Under extreme scenarios, CoRA improves upon its baseline performance by approximately 19% in AP@0.7 with more than 5x less communication volume, which makes it a promising solution for robust collaborative perception.
💡 Research Summary
The paper addresses two fundamental challenges in collaborative perception for connected autonomous vehicles: limited communication bandwidth and unreliable pose information caused by localization errors. While most recent state‑of‑the‑art (SOTA) methods rely on intermediate fusion—exchanging dense feature maps to achieve high detection accuracy—they assume perfectly aligned coordinate frames. In real V2X scenarios, pose errors (e.g., GPS/IMU drift, packet loss) corrupt the alignment, causing catastrophic performance drops. Late fusion, on the other hand, is more robust to pose errors because it merges detections at the object level, but it sacrifices the rich contextual information of dense features, resulting in a lower accuracy ceiling.
The authors propose CoRA (Collaborative Robust Architecture), a dual‑branch system that simultaneously exploits the strengths of both fusion paradigms while mitigating their weaknesses. The first branch performs feature‑level fusion. It introduces a receiver‑centric Competitive Information Transmission (CIT) module that replaces the traditional sender‑centric broadcast. Ego vehicles first receive lightweight confidence maps from all collaborators, compute a demand coefficient indicating which spatial regions are missing, and then generate a pixel‑wise winner‑take‑all selection to request only the most informative collaborator for each pixel. Collaborators respond with sparse feature patches masked by the request mask, keeping the communication load essentially constant regardless of the number of agents. These sparse features are then processed by the Lightweight Collaboration (LC) module, which employs a Collaborative State Space Model (CSSM) based on the Mamba architecture and a gating unit to adaptively fuse collaborator features with ego features. During training, a teacher branch provides full‑resolution features, and an alignment loss (L_align) distills knowledge into the sparse‑feature pipeline, compensating for information loss.
The second branch tackles pose‑induced misalignment at the object level. The Pose‑Aware Correction (PAC) module receives classification and regression maps from each collaborator, extracts high‑confidence detections, and augments each detection with a positional embedding derived from its bounding‑box parameters. Cross‑agent attention computes a matching score between ego and collaborator detections, effectively re‑associating objects despite pose errors. The resulting attention map re‑weights collaborator detections, correcting spatial displacement before the final fusion.
Experiments are conducted on two large‑scale benchmarks, OPV2V and V2X‑Seq, under a range of simulated pose errors (0–0.5 m translation, 0–5° rotation) and strict bandwidth caps (≤4 MB). CoRA achieves an average 19 % improvement in AP@0.7 over a strong intermediate‑fusion baseline while reducing communication volume by 82 % (e.g., from 3.80 MB to 0.68 MB). Importantly, the communication cost remains nearly flat as the number of collaborators grows from 2 to 8, demonstrating scalability. Ablation studies reveal that removing CIT leads to linear growth in bandwidth and performance degradation, while omitting PAC causes a steep drop in AP once pose error exceeds 0.3 m. The LC module is also essential; without it, the sparse features cannot be effectively aligned, resulting in a 10 % performance loss.
Key contributions are: (1) a novel dual‑stream hybrid architecture that decouples high accuracy from robustness, (2) the receiver‑centric CIT mechanism and the CSSM‑based LC module for efficient feature‑level collaboration, (3) the PAC module for pose‑aware object‑level correction, and (4) extensive empirical validation showing superior performance‑communication trade‑offs compared to nine existing methods.
Limitations include the current focus on 2‑D LiDAR feature maps; extending the framework to multimodal data (camera, radar) and to 3‑D feature representations remains future work. Additionally, the pose error model assumes Gaussian noise, which may not capture complex urban localization failures. The authors suggest future directions such as integrating asynchronous communication, end‑to‑end pose estimation within the collaborative pipeline, and exploring adaptive bandwidth allocation based on scene dynamics.
Comments & Academic Discussion
Loading comments...
Leave a Comment