Small Batch Size Training for Language Models: When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful
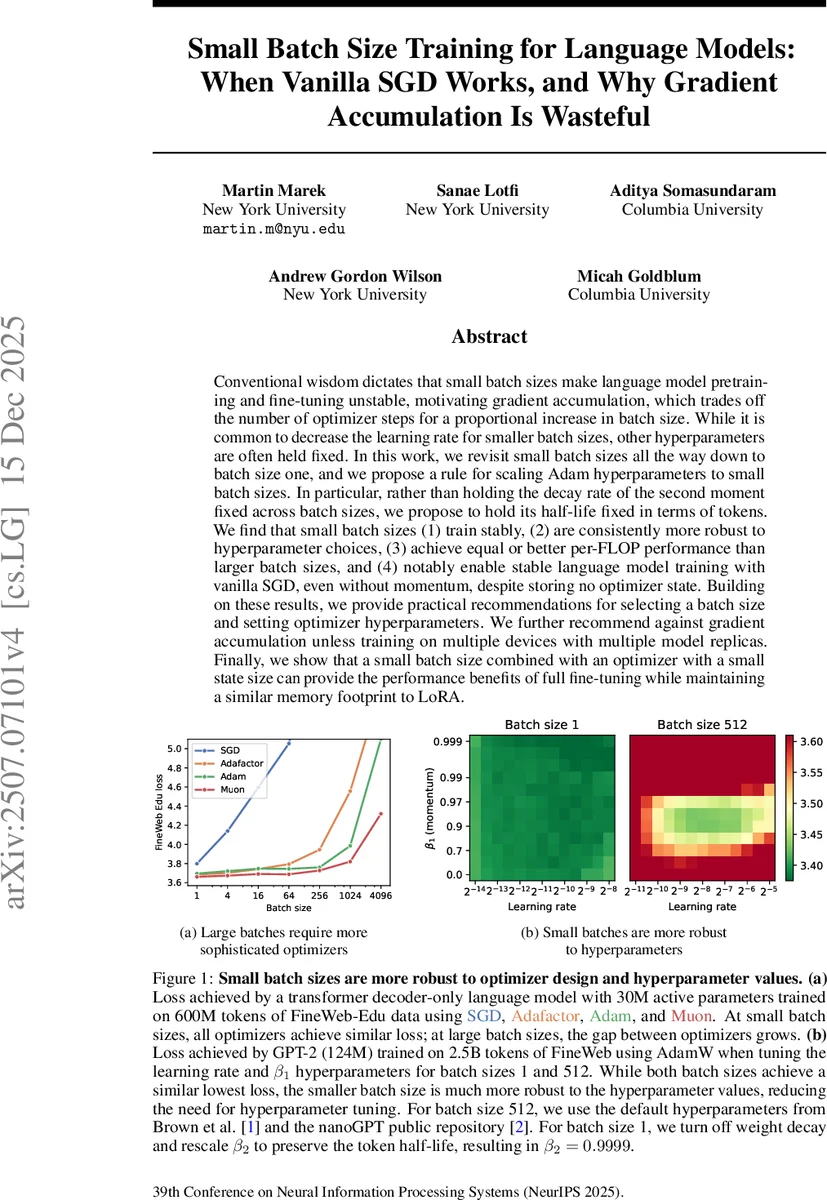
Conventional wisdom dictates that small batch sizes make language model pretraining and fine-tuning unstable, motivating gradient accumulation, which trades off the number of optimizer steps for a proportional increase in batch size. While it is common to decrease the learning rate for smaller batch sizes, other hyperparameters are often held fixed. In this work, we revisit small batch sizes all the way down to batch size one, and we propose a rule for scaling Adam hyperparameters to small batch sizes. In particular, rather than holding the decay rate of the second moment fixed across batch sizes, we propose to hold its half-life fixed in terms of tokens. We find that small batch sizes (1) train stably, (2) are consistently more robust to hyperparameter choices, (3) achieve equal or better per-FLOP performance than larger batch sizes, and (4) notably enable stable language model training with vanilla SGD, even without momentum, despite storing no optimizer state. Building on these results, we provide practical recommendations for selecting a batch size and setting optimizer hyperparameters. We further recommend against gradient accumulation unless training on multiple devices with multiple model replicas. Finally, we show that a small batch size combined with an optimizer with a small state size can provide the performance benefits of full fine-tuning while maintaining a similar memory footprint to LoRA.
💡 Research Summary
The paper challenges the prevailing belief that large batch sizes are required for stable language‑model pre‑training and fine‑tuning. By systematically exploring batch sizes from 1 up to 4096 on models ranging from 30 M to 1.3 B parameters, the authors demonstrate that training remains stable, efficient, and often superior when using very small batches, provided that optimizer hyper‑parameters are scaled appropriately.
The key technical contribution is a principled scaling rule for Adam’s second‑moment decay rate (β₂). Instead of keeping β₂ fixed across batch sizes, the authors keep the “token half‑life” constant: the number of tokens after which the contribution of any past gradient to the second‑moment estimate decays by a factor of one‑half. Formally, they set β₂ such that β₂^{B·T·t_{½}} = ½, where B is the batch size, T the sequence length, and t_{½} a target token count (e.g., 10 M tokens). This rule preserves the effective averaging window of the second‑moment estimate regardless of batch size, preventing the runaway accumulation of stale gradients that typically destabilizes very small‑batch training.
Empirical results on the FineWeb‑Edu, C4, and GPT‑2 (124 M) datasets show that with this scaling, loss curves for batch‑size‑1 training match or outperform those for large batches. Moreover, the loss surface becomes far less sensitive to the learning rate and β₁ (the first‑moment decay), meaning that hyper‑parameter tuning effort is dramatically reduced in the small‑batch regime.
A striking finding is that vanilla stochastic gradient descent (SGD) without momentum or weight decay can compete with Adam when batch size equals one. Because each step processes only a single example, the stochastic noise is large enough to provide sufficient exploration, making momentum unnecessary. This observation has profound memory implications: SGD stores no optimizer state, allowing larger models to be trained within the same GPU memory budget.
The paper also revisits Adafactor, a memory‑efficient variant of Adam that stores only per‑row and per‑column statistics. When combined with small batches, Adafactor achieves a favorable performance‑to‑memory trade‑off, enabling fine‑tuning approaches that match the benefits of full‑parameter fine‑tuning while keeping the memory footprint comparable to low‑rank adaptation methods such as LoRA.
Regarding gradient accumulation, the authors argue that it is largely wasteful. Accumulation simulates a larger effective batch by summing gradients over several micro‑steps, but it requires storing the accumulated gradients, increasing memory usage without delivering the robustness benefits of genuinely small batches. Experiments show that, for a fixed token budget and FLOP count, directly using the smallest feasible batch yields faster convergence and more stable training than any accumulation strategy, except when multiple devices are employed to replicate the model for data‑parallelism.
Based on these findings, the authors propose practical guidelines: (1) use the smallest batch size that maximizes throughput on the available hardware; (2) scale β₂ according to a constant token half‑life, while keeping β₁ and the learning rate in a relatively wide, forgiving range; (3) consider vanilla SGD or Adafactor for memory‑constrained scenarios; (4) avoid gradient accumulation unless necessary for multi‑device parallelism.
The paper’s contributions are both theoretical—introducing the token half‑life concept for exponential moving averages—and empirical, providing extensive ablations across optimizers, batch sizes, and model scales. The released codebase (github.com/martin‑marek/batch‑size) enables reproducibility and facilitates adoption of the proposed small‑batch training paradigm in both research and production settings.
Comments & Academic Discussion
Loading comments...
Leave a Comment