Meta Pruning via Graph Metanetworks : A Universal Meta Learning Framework for Network Pruning
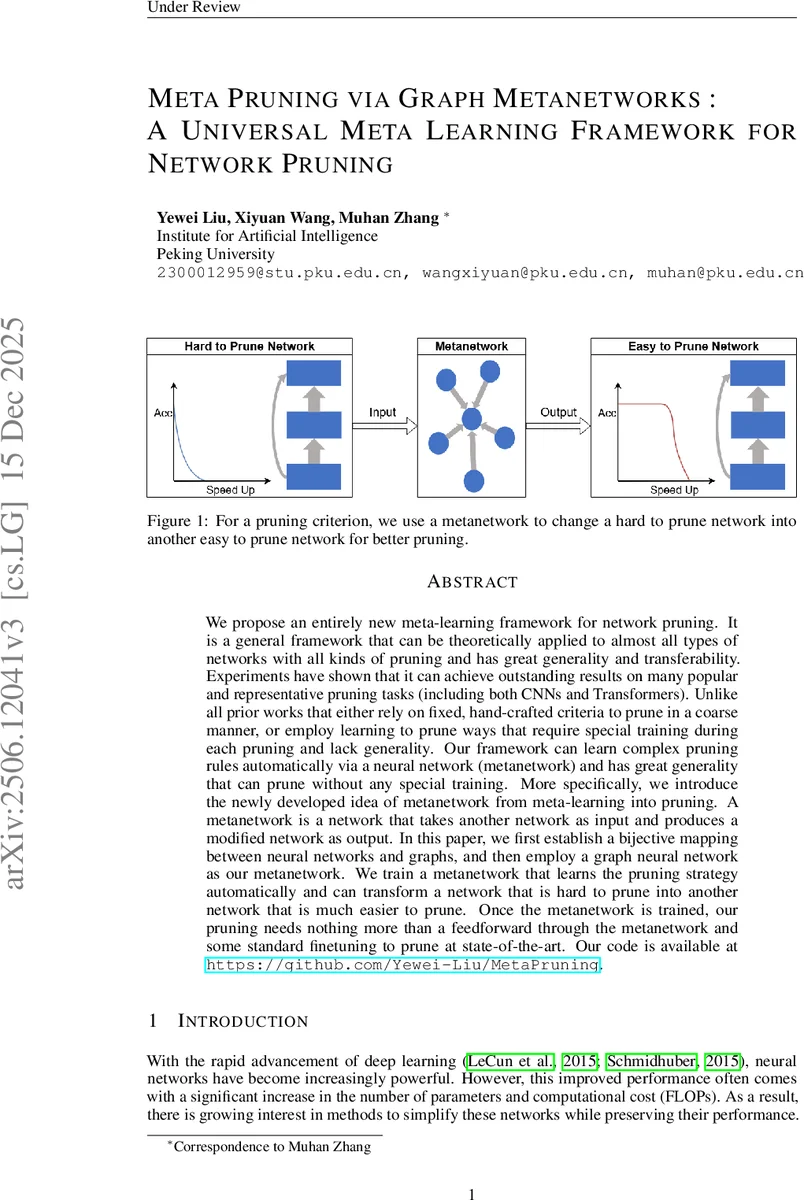
We propose an entirely new meta-learning framework for network pruning. It is a general framework that can be theoretically applied to almost all types of networks with all kinds of pruning and has great generality and transferability. Experiments have shown that it can achieve outstanding results on many popular and representative pruning tasks (including both CNNs and Transformers). Unlike all prior works that either rely on fixed, hand-crafted criteria to prune in a coarse manner, or employ learning to prune ways that require special training during each pruning and lack generality. Our framework can learn complex pruning rules automatically via a neural network (metanetwork) and has great generality that can prune without any special training. More specifically, we introduce the newly developed idea of metanetwork from meta-learning into pruning. A metanetwork is a network that takes another network as input and produces a modified network as output. In this paper, we first establish a bijective mapping between neural networks and graphs, and then employ a graph neural network as our metanetwork. We train a metanetwork that learns the pruning strategy automatically and can transform a network that is hard to prune into another network that is much easier to prune. Once the metanetwork is trained, our pruning needs nothing more than a feedforward through the metanetwork and some standard finetuning to prune at state-of-the-art. Our code is available at https://github.com/Yewei-Liu/MetaPruning
💡 Research Summary
This paper introduces “Meta Pruning,” a novel and universal meta-learning framework for network pruning that fundamentally rethinks how pruning strategies can be learned and applied. The core idea is to employ a “metanetwork”—a neural network that takes another neural network as input and outputs a modified network—to automatically learn how to transform a given network into one that is significantly easier to prune according to a specific pruning criterion.
The key technical innovation lies in the implementation of this metanetwork using Graph Neural Networks (GNNs). The authors first establish a bijective mapping between a neural network and a graph representation. In this mapping, each neuron (or channel in CNNs) becomes a node, and connections between them (e.g., via linear, convolutional, or residual layers) become edges. Node features encapsulate parameters associated with the neuron (weights, biases, batch norm statistics), while edge features represent the connection weights (e.g., flattened convolution kernels). This conversion preserves the structural and parametric information of the original network in a format amenable to GNN processing.
The metanetwork itself is built upon a message-passing GNN architecture, specifically using Principal Neighborhood Aggregation (PNA). It processes the input graph through several layers, updating node and edge features. Crucially, the final output is designed as a residual update: the metanetwork predicts a small delta change, which is scaled by a tiny coefficient (e.g., 0.01) and added to the original input features. This encourages the metanetwork to learn subtle, pruning-friendly adjustments rather than completely overwriting the network.
The metanetwork is trained via a “meta-training” process. A small set of “data models” (networks to be pruned) and a standard training dataset (e.g., CIFAR-10) are used. In each iteration, one data model is converted to a graph, passed through the metanetwork, and converted back to a network. Two losses are computed on this transformed network: an accuracy loss (cross-entropy on the training data) to prevent catastrophic damage to the network’s performance, and a sparsity loss derived from the chosen pruning criterion (e.g., promoting low group L2 norm scores) to encourage the network to become easy to prune. Gradients from these losses are backpropagated to update the metanetwork.
Once trained, the pruning pipeline is remarkably simple and efficient. For a new target network, one only needs to: (1) convert it to a graph, (2) perform a single forward pass through the pre-trained metanetwork to obtain the transformed graph, (3) convert it back to a network, (4) apply standard pruning based on the chosen criterion (e.g., removing channels with the smallest group norms), and (5) perform light fine-tuning. No additional meta-training on the target network is required, granting the framework exceptional generality and transferability.
The authors demonstrate the framework’s effectiveness primarily on structured pruning for CNNs (e.g., ResNet) and Vision Transformers, achieving state-of-the-art results. They also show its potential applicability to unstructured and N:M sparsity pruning. The proposed Meta Pruning framework distinguishes itself from prior work by being the first to leverage a graph-based metanetwork for pruning, offering a powerful, general-purpose solution that automates the learning of pruning strategies and eliminates the need for expensive per-model training during the pruning phase itself.
Comments & Academic Discussion
Loading comments...
Leave a Comment