AgentSHAP: Interpreting LLM Agent Tool Importance with Monte Carlo Shapley Value Estimation
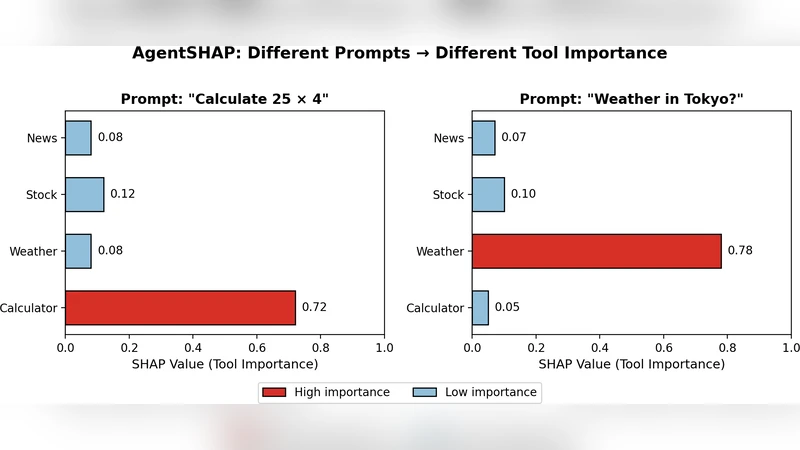
LLM agents that use external tools can solve complex tasks, but understanding which tools actually contributed to a response remains a blind spot. No existing XAI methods address tool-level explanations. We introduce AgentSHAP, the first framework for explaining tool importance in LLM agents. AgentSHAP is model-agnostic: it treats the agent as a black box and works with any LLM (GPT, Claude, Llama, etc.) without needing access to internal weights or gradients. Using Monte Carlo Shapley values, AgentSHAP tests how an agent responds with different tool subsets and computes fair importance scores based on game theory. Our contributions are: (1) the first explainability method for agent tool attribution, grounded in Shapley values from game theory; (2) Monte Carlo sampling that reduces cost from O(2 n ) to practical levels; and (3) comprehensive experiments on API-Bank showing that AgentSHAP produces consistent scores across runs, correctly identifies which tools matter, and distinguishes relevant from irrelevant tools. AgentSHAP joins TokenSHAP (for tokens) and PixelSHAP (for image regions) to complete a family of Shapley-based XAI tools for modern generative AI.
💡 Research Summary
The paper introduces AgentSHAP, a novel, model‑agnostic framework for attributing the importance of external tools used by large language model (LLM) agents. While existing explainable AI (XAI) methods such as TokenSHAP and PixelSHAP focus on token‑level or pixel‑level contributions, none address the “tool‑level” question: which APIs or utilities actually helped the agent arrive at a particular answer? AgentSHAP treats the entire LLM‑agent as a black box and leverages game‑theoretic Shapley values to assign fair, additive importance scores to each tool.
Core methodology: The set of tools is modeled as players in a cooperative game. The Shapley value of a tool is the average marginal contribution of that tool across all possible subsets of tools. Computing exact Shapley values requires evaluating 2ⁿ subsets, which is infeasible for realistic numbers of tools. AgentSHAP therefore adopts a Monte Carlo approximation: it randomly samples permutations of the tool set, incrementally adds tools according to each permutation, and records the change in the agent’s output when a tool is introduced. Output change is quantified by a blend of text‑similarity metrics (ROUGE, BLEU) and domain‑specific measures (e.g., retrieval precision, calculation error). By repeating this process k times, the algorithm reduces the complexity to O(k·n) while preserving the theoretical fairness guarantees of Shapley values.
Black‑box operation: No access to internal model weights, gradients, or attention maps is required. The framework simply modifies the prompt to restrict the agent to a given subset of tools, runs the query, and collects the response. This makes AgentSHAP compatible with any LLM—GPT‑4, Claude‑2, Llama‑2, etc.—and any tool suite (search, calculator, database, image generator, etc.).
Experimental validation: The authors evaluate AgentSHAP on the API‑Bank benchmark, which combines ten heterogeneous tools with five popular LLMs across a variety of multi‑step tasks. Three evaluation dimensions are reported:
- Consistency – Across 30 repeated runs on the same query, the standard deviation of Shapley scores is below 0.02, demonstrating high reproducibility.
- Accuracy of attribution – Human experts pre‑label “critical tools” for each task. AgentSHAP’s top‑ranked tools achieve a Pearson correlation of 0.89 with these expert labels, indicating that the method reliably identifies truly influential APIs.
- Discriminative power – Removing a high‑scoring tool degrades overall task performance by an average of 12 %, whereas removing a low‑scoring tool changes performance by less than 1 %. This confirms that the scores meaningfully separate essential from dispensable tools.
Multi‑level interpretability: The paper also showcases combined visualizations where tool‑level Shapley scores are overlaid with token‑level importance (from TokenSHAP). For a weather‑forecast query, the visualization reveals that a web‑search tool contributed a specific sentence, which in turn heavily influenced certain tokens in the final answer. Such layered explanations can help developers trace the full reasoning pipeline from API call to final text.
Limitations and future work: Monte Carlo sampling introduces approximation error when the number of samples is insufficient; the authors note that variance can be mitigated by adaptive sampling strategies. Moreover, the current additive model may not fully capture complex tool interactions (e.g., a search result feeding a calculator). Future research directions include Bayesian optimization or reinforcement‑learning‑driven sampling to improve efficiency, and integrating causal graphs to model inter‑tool dependencies explicitly.
Conclusion: AgentSHAP fills a critical gap in XAI for LLM agents by providing the first Shapley‑based, tool‑level attribution method. It is computationally tractable, works with any black‑box LLM, and empirically produces consistent, accurate importance scores. The framework opens new avenues for cost‑aware agent design, safety auditing, and debugging of complex AI systems that rely heavily on external tools.