Highly Imbalanced Regression with Tabular Data in SEP and Other Applications
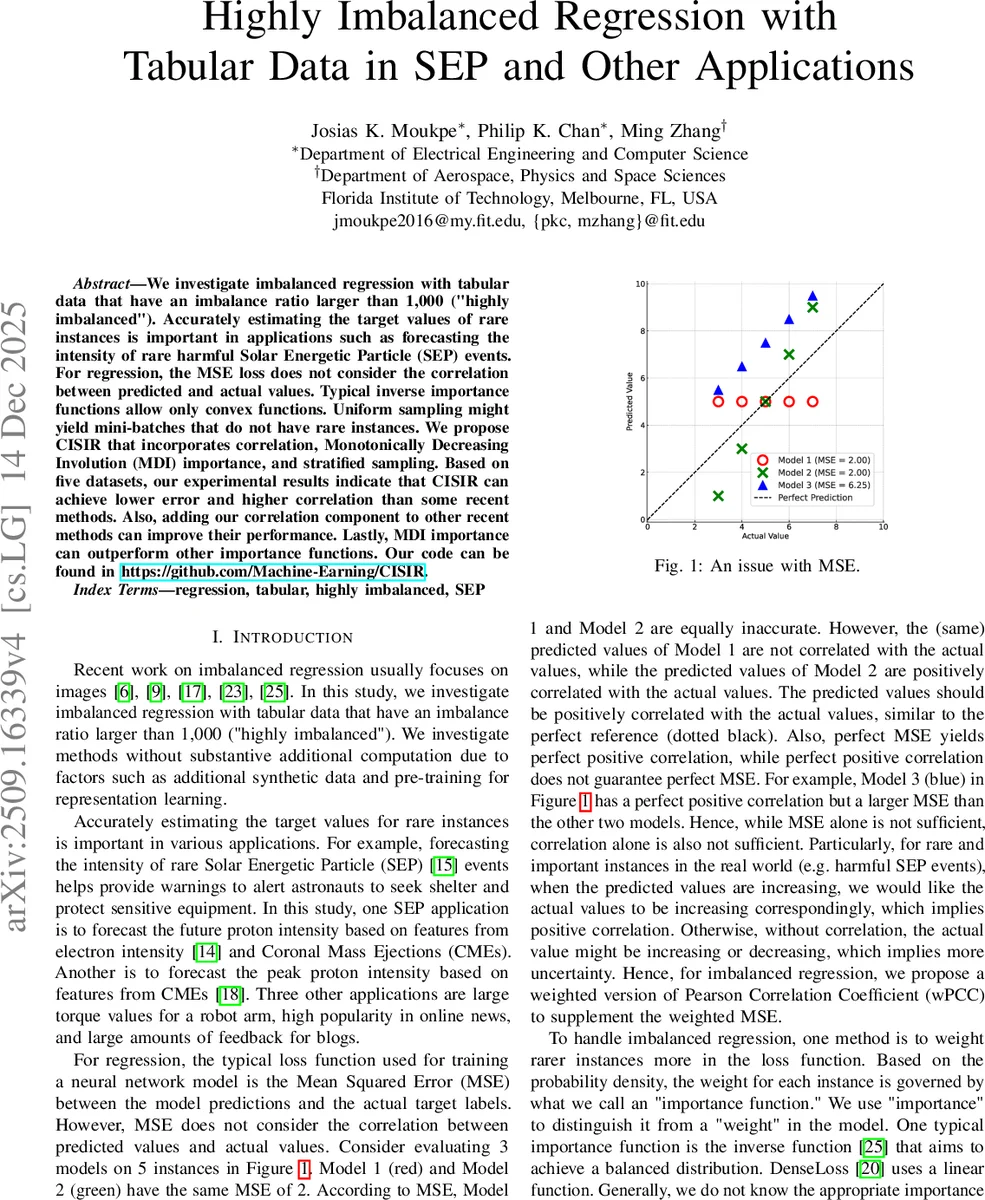
We investigate imbalanced regression with tabular data that have an imbalance ratio larger than 1,000 (“highly imbalanced”). Accurately estimating the target values of rare instances is important in applications such as forecasting the intensity of rare harmful Solar Energetic Particle (SEP) events. For regression, the MSE loss does not consider the correlation between predicted and actual values. Typical inverse importance functions allow only convex functions. Uniform sampling might yield mini-batches that do not have rare instances. We propose CISIR that incorporates correlation, Monotonically Decreasing Involution (MDI) importance, and stratified sampling. Based on five datasets, our experimental results indicate that CISIR can achieve lower error and higher correlation than some recent methods. Also, adding our correlation component to other recent methods can improve their performance. Lastly, MDI importance can outperform other importance functions. Our code can be found in https://github.com/Machine-Earning/CISIR.
💡 Research Summary
The research paper titled “Highly Imbalanced Regression with Tabral Data in SEP and Other Applications” addresses a critical challenge in machine learning: performing accurate regression in environments characterized by extreme data imbalance. In many real-world scenarios, such as forecasting the intensity of Solar Energetic Particle (SEP) events, the imbalance ratio can exceed 1,000, meaning the target values of interest—rare, high-intensity events—are extremely infrequent compared to common events. The authors identify that standard regression techniques fail significantly under these “highly imbalanced” conditions.
The paper identifies three fundamental flaws in existing methodologies. First, the standard Mean Squared Error (MSE) loss function focuses solely on minimizing the distance between predicted and actual values. It fails to account for the correlation between these two variables, which is crucial for capturing the underlying patterns and trends of rare events. Second, existing inverse importance functions, which are often used to reweight samples, are typically limited to convex functions, making them unable to handle complex, non-convex data distributions effectively. Third, the use of uniform sampling in mini-batch training poses a significant risk; in highly imbalanced datasets, rare instances may be entirely absent from many mini-batches, preventing the model from ever learning their specific characteristics.
To overcome these limitations, the authors propose a novel framework called CISIR (Correlation, Importance, and Stratified sampling for Imbalanced Regression). CISIR integrates three synergistic components. The first component introduces a correlation-based loss, which encourages the model to predict values that follow the statistical trends of the actual targets, rather than just minimizing point-wise error. A key strength of this component is its modularity; it can be integrated into other existing regression methods to enhance their performance. The second component is the Monotonically Decreasing Involution (MDI) importance function. This new approach to importance weighting outperforms traditional functions by providing a more effective way to prioritize rare samples. The third component is the implementation of stratified sampling, which ensures that rare instances are consistently represented within each mini-batch during the training process.
The experimental results, conducted across five diverse datasets, demonstrate the superiority of CISIR. The proposed method achieves lower error rates and higher correlation coefficients compared to several state-of-the-art (SOTA) methods. Furthermore, the study proves that the MDI importance function is more robust and effective than previous importance-weighting strategies. By addressing the structural, weighting, and sampling aspects of imbalanced regression, CISIR provides a comprehensive solution for high-stakes applications like SEP forecasting, where accurately predicting rare, high-impact events is of paramount importance.
Comments & Academic Discussion
Loading comments...
Leave a Comment