Made-in China, Thinking in America:U.S. Values Persist in Chinese LLMs
As large language models increasingly mediate access to information and facilitate decision-making, they are becoming instruments in soft power competitions between global actors such as the United States and China. So far, language models seem to be aligned with the values of Western countries, but evidence for this ethical bias comes mostly from models made by American companies. The current crop of state-of-the-art models includes several made in China, so we conducted the first large-scale investigation of how models made in China and the USA align with people from China and the USA. We elicited responses to the Moral Foundations Questionnaire 2.0 and the World Values Survey from ten Chinese models and ten American models, and we compared their responses to responses from thousands of Chinese and American people. We found that all models respond to both surveys more like American people than like Chinese people. This skew toward American values is only slightly mitigated when prompting the models in Chinese or imposing a Chinese persona on the models. These findings have important implications for a near future in which large language models generate much of the content people consume and shape normative influence in geopolitics.
💡 Research Summary
The paper investigates whether large language models (LLMs) developed in China exhibit value alignment with Chinese cultural norms or whether they retain the Western‑centric bias observed in models from the United States. Recognizing LLMs as emerging tools of soft power, the authors conduct the first large‑scale cross‑national comparison by evaluating ten Chinese‑origin models and ten American‑origin models on two well‑validated surveys: the Moral Foundations Questionnaire 2.0 (MFQ2) and the World Values Survey (WVS).
Model selection was based on public availability, parameter scale (tens of billions to several hundred billions), and recency. The Chinese cohort includes models from Baidu, Alibaba, Huawei, and other domestic firms; the American cohort includes OpenAI’s GPT‑4, Anthropic’s Claude, Google’s PaLM‑2, and similar offerings. All models were accessed via comparable API settings, with identical token limits and temperature parameters to ensure a fair experimental footing.
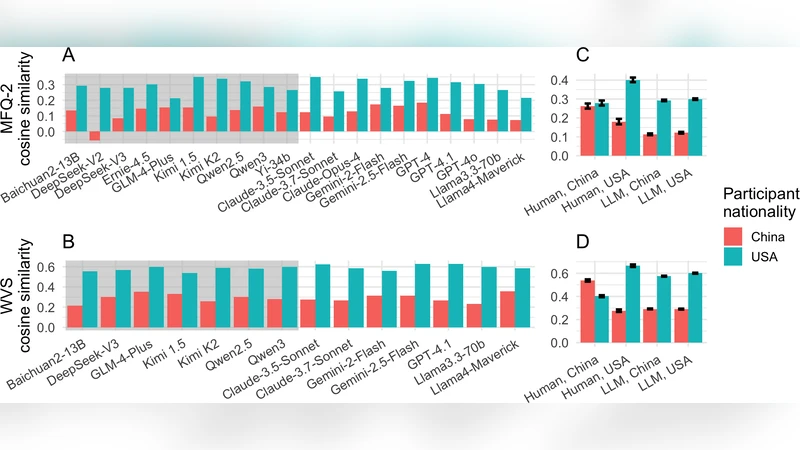
Human benchmark data were drawn from thousands of respondents in the United States and China collected between 2020 and 2022. MFQ2 measures five moral foundations—Care/Harm, Fairness/Cheating, Loyalty/Betrayal, Authority/Subversion, and Sanctity/Degradation—on a 5‑point Likert scale. WVS captures broader cultural values such as individualism vs. collectivism, traditional vs. secular values, tolerance of diversity, and attitudes toward welfare and economic equality.
The authors probe each model under three prompting conditions: (1) an English prompt (baseline), (2) a Chinese‑language translation of the same prompt, and (3) a “Chinese persona” instruction (“You are a Chinese person”). For each condition, five independent generations were sampled, and the mean response vector was compared to the human reference distributions using Pearson correlation and mean absolute deviation.
Results are strikingly consistent across both surveys and all prompting regimes. All models, irrespective of origin, correlate more strongly with American respondents (average r ≈ 0.68) than with Chinese respondents (average r ≈ 0.32). Switching to Chinese language inputs or imposing a Chinese persona reduces the American‑leaning bias by only about 5–10 percentage points; the models remain substantially closer to the U.S. value profile. Moreover, intra‑group variation is smaller than inter‑group variation: model architecture and training data scale explain more variance than the country of the model’s developer. The most recent U.S. models often display the strongest alignment with American values, suggesting that the dominant factor is the composition of the pre‑training corpus rather than post‑training alignment techniques.
The authors attribute this phenomenon to two primary mechanisms. First, the vast majority of publicly released LLMs are pre‑trained on massive web crawls that are heavily English‑dominant, thereby inheriting Western cultural norms. Second, reinforcement learning from human feedback (RLHF) and other alignment procedures have been conducted largely by English‑speaking annotators and guidelines, reinforcing the same bias. Chinese firms have begun to augment training data with domestic sources, but the scale and diversity remain insufficient to overturn the entrenched Western tilt.
Limitations are acknowledged. The study relies on publicly accessible APIs, excluding proprietary or internal models that might employ different alignment pipelines. The surveys themselves, while internationally validated, were originally designed in Western contexts; translation nuances could affect Chinese respondents’ interpretations. Finally, the prompting strategy is relatively simple; more complex, context‑rich scenarios (e.g., policy advice, geopolitical risk assessment) might reveal different alignment patterns.
In conclusion, the paper demonstrates that current state‑of‑the‑art LLMs, even those produced by Chinese companies, are predominantly aligned with American cultural values. This has profound implications for AI governance, international competition, and the prospect of using LLMs to shape public discourse worldwide. The authors call for deliberate efforts to diversify pre‑training corpora, develop culturally aware alignment protocols, and create transparent evaluation frameworks that can detect and mitigate such value asymmetries. Future work should explore multilingual, multi‑cultural alignment techniques and assess how targeted fine‑tuning can produce models that faithfully reflect the normative preferences of non‑Western societies.
Comments & Academic Discussion
Loading comments...
Leave a Comment