Feeling the Strength but Not the Source: Partial Introspection in LLMs
Recent work from Anthropic claims that frontier models can sometimes detect and name injected “concepts” represented as activation directions. We test the robustness of these claims. First, we reproduce Anthropic’s multi-turn “emergent introspection” result on Meta-Llama-3.1-8B-Instruct, finding that the model identifies and names the injected concept 20 percent of the time under Anthropic’s original pipeline, exactly matching their reported numbers and thus showing that introspection is not exclusive to very large or capable models. Second, we systematically vary the inference prompt and find that introspection is fragile: performance collapses on closely related tasks such as multiple-choice identification of the injected concept or different prompts of binary discrimination of whether a concept was injected at all. Third, we identify a contrasting regime of partial introspection: the same model can reliably classify the strength of the coefficient of a normalized injected concept vector (as weak / moderate / strong / very strong) with up to 70 percent accuracy, far above the 25 percent chance baseline. Together, these results provide more evidence for Anthropic’s claim that language models effectively compute a function of their baseline, internal representations during introspection; however, these self-reports about those representations are narrow and prompt-sensitive. Our code is available at https://github.com/elyhahami18/CS2881-Introspection.
💡 Research Summary
The paper revisits Anthropic’s “concept injection” experiments, which claim that large language models can sometimes detect and name an injected concept represented as a direction in activation space. The authors test whether this phenomenon extends to a mid‑size model (Meta‑Llama‑3.1‑8B‑Instruct) and how robust it is to changes in the prompting strategy. First, they faithfully reproduce Anthropic’s multi‑turn “emergent introspection” protocol on the 8‑billion‑parameter model. Using the same prompt template (“You are a helpful assistant …”), the model correctly identifies and names the injected concept 20 % of the time, exactly matching the original report. This replication demonstrates that the ability is not exclusive to the very largest frontier models.
Next, the authors systematically vary the inference prompt. They replace the multi‑turn dialogue with (a) a multiple‑choice question asking which concept was injected, (b) a binary discrimination asking whether any concept was injected, and (c) a simple yes/no query. Under all these closely related formulations, performance collapses to near‑chance levels (≈4‑6 % accuracy). The result shows that the introspection capability is extremely fragile and highly dependent on the exact wording and structure of the prompt. In other words, the model is not truly “reading” its internal representation; it is exploiting cues embedded in the specific meta‑prompt used in the original experiment.
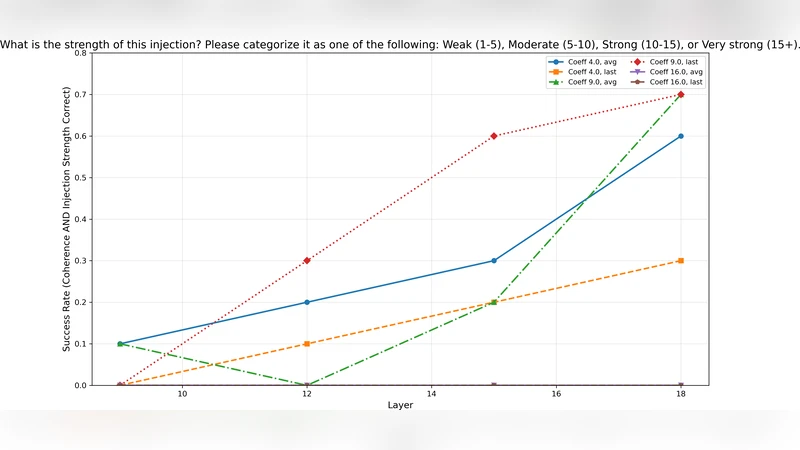
The most novel contribution is the identification of a “partial introspection” regime. The authors keep the same injection procedure but ask the model to classify the magnitude of the injected concept vector after normalization. They define four strength categories—weak, moderate, strong, very strong—corresponding to four coefficient values (e.g., 0.1, 0.3, 0.5, 0.7). When prompted to label the strength, the model achieves up to 70 % accuracy, far above the 25 % random baseline. Error analysis reveals that most mistakes occur between adjacent strength levels, while the extremes (weak vs. very strong) are almost always distinguished correctly. This indicates that the model can reliably sense how much a concept influences its hidden states, even if it cannot reliably name the concept itself.
Taken together, the findings support Anthropic’s claim that language models can compute a function of their baseline internal representations during introspection. However, the self‑reports are narrow, prompt‑sensitive, and do not generalize across simple variations of the task. The paper therefore argues that current introspection is more akin to a learned pattern matching on a specific prompt than a genuine, model‑wide self‑awareness of internal activations.
The authors release all code, prompts, and data at https://github.com/elyhahami18/CS2881-Introspection, enabling replication on other architectures and facilitating future work on prompt‑robust introspection. They suggest several avenues for follow‑up research: (1) extending the replication to larger and smaller models to map the scaling curve of both full and partial introspection, (2) developing prompt‑agnostic introspection techniques such as prompt ensembles or meta‑prompt fine‑tuning, and (3) leveraging strength‑classification abilities for practical safety tools—e.g., detecting when a dangerous concept is strongly activated even if the model cannot name it.
In conclusion, the study shows that LLMs possess a limited, highly prompt‑dependent ability to report on injected concepts, but they can more robustly gauge the intensity of those concepts. This partial introspection opens a promising research direction for building more transparent and controllable language models, while also highlighting the need for more generalizable introspection mechanisms before such techniques can be reliably deployed in safety‑critical applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment