BLURR: A Boosted Low-Resource Inference for Vision-Language-Action Models
Vision-language-action (VLA) models enable impressive zero shot manipulation, but their inference stacks are often too heavy for responsive web demos or high frequency robot control on commodity GPUs. We present BLURR, a lightweight inference wrapper that can be plugged into existing VLA controllers without retraining or changing model checkpoints. Instantiated on the pi-zero VLA controller, BLURR keeps the original observation interfaces and accelerates control by combining an instruction prefix key value cache, mixed precision execution, and a single step rollout schedule that reduces per step computation. In our SimplerEnv based evaluation, BLURR maintains task success rates comparable to the original controller while significantly lowering effective FLOPs and wall clock latency. We also build an interactive web demo that allows users to switch between controllers and toggle inference options in real time while watching manipulation episodes. This highlights BLURR as a practical approach for deploying modern VLA policies under tight compute budgets.
💡 Research Summary
This paper introduces BLURR (Boosted Low-Resource Inference), a lightweight inference wrapper designed to significantly accelerate Vision-Language-Action (VLA) models without modifying their pre-trained weights or architecture. VLA models, such as Pi-0, OpenVLA, and TraceVLA, enable impressive zero-shot robotic manipulation but suffer from high computational latency due to heavy vision encoders and multimodal decoders, making them unsuitable for real-time applications like responsive web demos or high-frequency robot control.
BLURR addresses this gap by optimizing the inference pipeline itself, adhering to three core principles: reducing redundant prefix computation, minimizing per-step token cost, and maximizing hardware utilization. Its key technical innovations include: 1) Prefix KV Caching: The language instruction is processed once at the start of an episode to create a Key-Value cache, which is reused in all subsequent control steps, eliminating repetitive encoding of static text. 2) Single-Step Rollout: Instead of predicting a sequence of actions over multiple steps (e.g., 10), BLURR reduces the control horizon to a single step, drastically cutting per-step computation for short-horizon tasks. 3) Efficient Decoder Execution: The action decoder runs in BF16 precision to reduce memory bandwidth, is wrapped with torch.compile for kernel fusion and reduced Python overhead, and employs FlashAttention kernels for optimized attention computation.
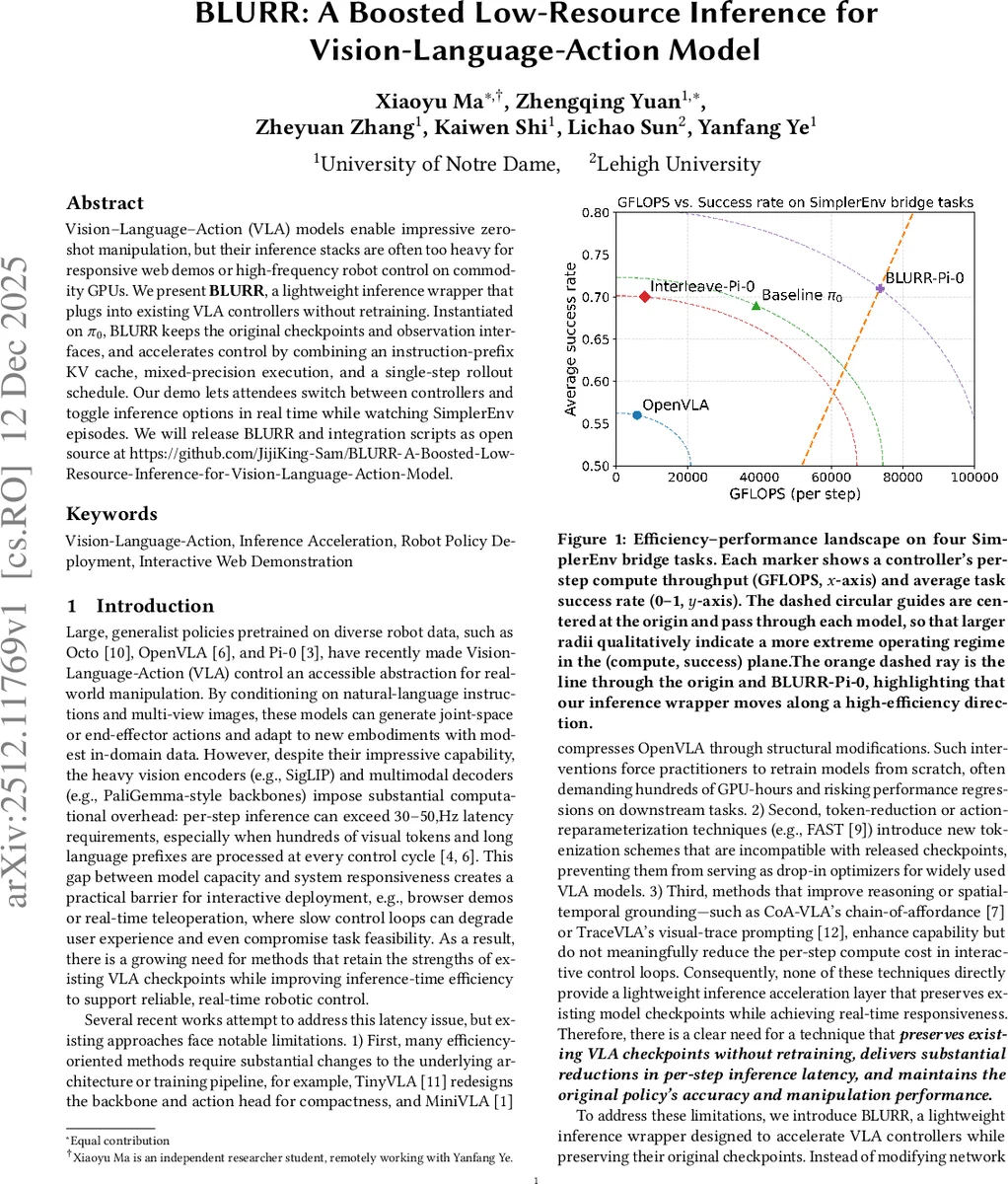
The method is evaluated on four in-domain manipulation tasks from the SimplerEnv benchmark (Carrot-on-plate, Eggplant-in-container, Spoon-on-plate, Stack-blocks). Using the same Pi-0 checkpoint, BLURR-Pi-0 is compared against the original Pi-0 baseline and an Interleave-Pi-0 controller. Results demonstrate that BLURR maintains task success rates (avg. 0.71) comparable to the original controllers while achieving dramatic efficiency gains. On a single H100 GPU, it reduces per-step latency from 162.1ms (Interleave-Pi-0) to 17.1ms (a 9.5x speedup), lowers peak VRAM usage from 13.61GB to 7.20GB (0.53x), and increases effective GFLOPS to 73,525. An ablation study quantifies the incremental benefits of each component (BF16, compilation, step reduction, KV caching).
To showcase its practicality, the authors built an interactive web demo where users can toggle inference options (e.g., BF16, compilation, number of inference steps) in real-time while watching manipulation episodes. This interface allows direct observation of the trade-offs between speed, memory, and task performance. The work argues that substantial improvements in VLA responsiveness can be achieved through inference-stack engineering alone, offering a plug-and-play solution for deploying state-of-the-art VLA policies under tight compute constraints. The implementation will be released as open-source.
Comments & Academic Discussion
Loading comments...
Leave a Comment