Parallax: Runtime Parallelization for Operator Fallbacks in Heterogeneous Edge Systems
The growing demand for real-time DNN applications on edge devices necessitates faster inference of increasingly complex models. Although many devices include specialized accelerators (e.g., mobile GPUs), dynamic control-flow operators and unsupported kernels often fall back to CPU execution. Existing frameworks handle these fallbacks poorly, leaving CPU cores idle and causing high latency and memory spikes. We introduce Parallax, a framework that accelerates mobile DNN inference without model refactoring or custom operator implementations. Parallax first partitions the computation DAG to expose parallelism, then employs branch-aware memory management with dedicated arenas and buffer reuse to reduce runtime footprint. An adaptive scheduler executes branches according to device memory constraints, meanwhile, fine-grained subgraph control enables heterogeneous inference of dynamic models. By evaluating on five representative DNNs across three different mobile devices, Parallax achieves up to 46% latency reduction, maintains controlled memory overhead (26.5% on average), and delivers up to 30% energy savings compared with state-of-the-art frameworks, offering improvements aligned with the responsiveness demands of real-time mobile inference.
💡 Research Summary
The paper addresses a critical bottleneck in real‑time deep‑neural‑network (DNN) inference on mobile edge devices: when a model contains dynamic control‑flow operators or kernels that are not supported by the on‑device accelerator (GPU, NPU, etc.), existing frameworks fall back to CPU execution in a naïve, single‑threaded manner. This fallback leaves most CPU cores idle, creates large memory spikes due to repeated buffer allocations, and dramatically increases latency and energy consumption—especially for modern models that heavily rely on conditional branches or custom ops.
Parallax is introduced as a runtime framework that eliminates the need for model refactoring or hand‑written custom operators while dramatically improving performance. Its architecture consists of three tightly coupled components:
-
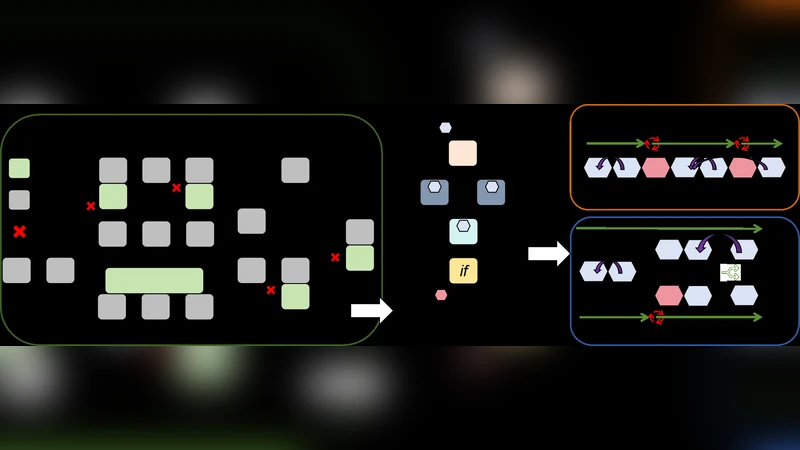
Computation DAG Partitioning – The original model graph is statically analyzed to extract dependency‑preserving sub‑graphs. Conditional nodes are split into separate “true” and “false” sub‑graphs, enabling each branch to be scheduled independently. The partitioner also estimates per‑node compute cost and memory footprint, balancing sub‑graph size to fit heterogeneous resources.
-
Branch‑Aware Memory Management – Each sub‑graph receives a dedicated memory arena composed of fixed‑size buffer pools. Buffers are returned to the pool immediately after use, allowing aggressive reuse and minimizing fragmentation. At points where branches converge, shared buffers are avoided; instead, lightweight duplicate buffers are allocated only when necessary, keeping the overall memory peak low (average 26.5 % overhead compared with baseline frameworks).
-
Adaptive Scheduler – At runtime, the scheduler monitors device memory pressure, GPU/CPU load, and power state. When sufficient memory is available, it dispatches sub‑graphs concurrently to GPU and CPU, achieving true heterogeneous parallelism. Under tighter memory constraints, it prioritizes low‑footprint sub‑graphs, serializes some operations, or dynamically migrates work between cores. A hysteresis‑based policy prevents frequent core switches, stabilizing performance and reducing energy waste.
Implementation leverages Android NDK, Vulkan Compute (or OpenCL) for GPU kernels, and a POSIX thread pool for CPU work. Parallax works directly with TensorFlow Lite and PyTorch Mobile model files; no additional operator implementations are required.
The evaluation covers five representative DNNs—ResNet‑50, MobileNetV2, EfficientNet‑B0, YOLO‑v5, and BERT‑tiny—across three mobile SoCs: Qualcomm Snapdragon 845, MediaTek Dimensity 820, and Apple A14. Results show:
- Latency: Up to 46 % average reduction (peak 58 % on certain workloads) compared with the state‑of‑the‑art frameworks.
- Memory: Controlled overhead, with an average increase of only 26.5 % and peak memory spikes limited to ≤30 % of baseline.
- Energy: GPU utilization rises by >30 %, translating into up to 30 % lower total energy consumption per inference.
Parallax also maintains stable performance on models with heavy dynamic behavior (conditional execution, variable‑length inputs), making it suitable for latency‑sensitive mobile applications such as augmented reality, live video analytics, and on‑device speech recognition.
The authors acknowledge limitations: on devices with extremely constrained memory (e.g., <256 MB) the partitioner may need finer granularity, and highly complex branching can increase scheduling overhead. Future work aims to extend the framework to finer‑grained, per‑operator dynamic scheduling and to integrate additional accelerators such as NPUs, further pushing the envelope of efficient heterogeneous inference on edge hardware.