PersonaLive! Expressive Portrait Image Animation for Live Streaming
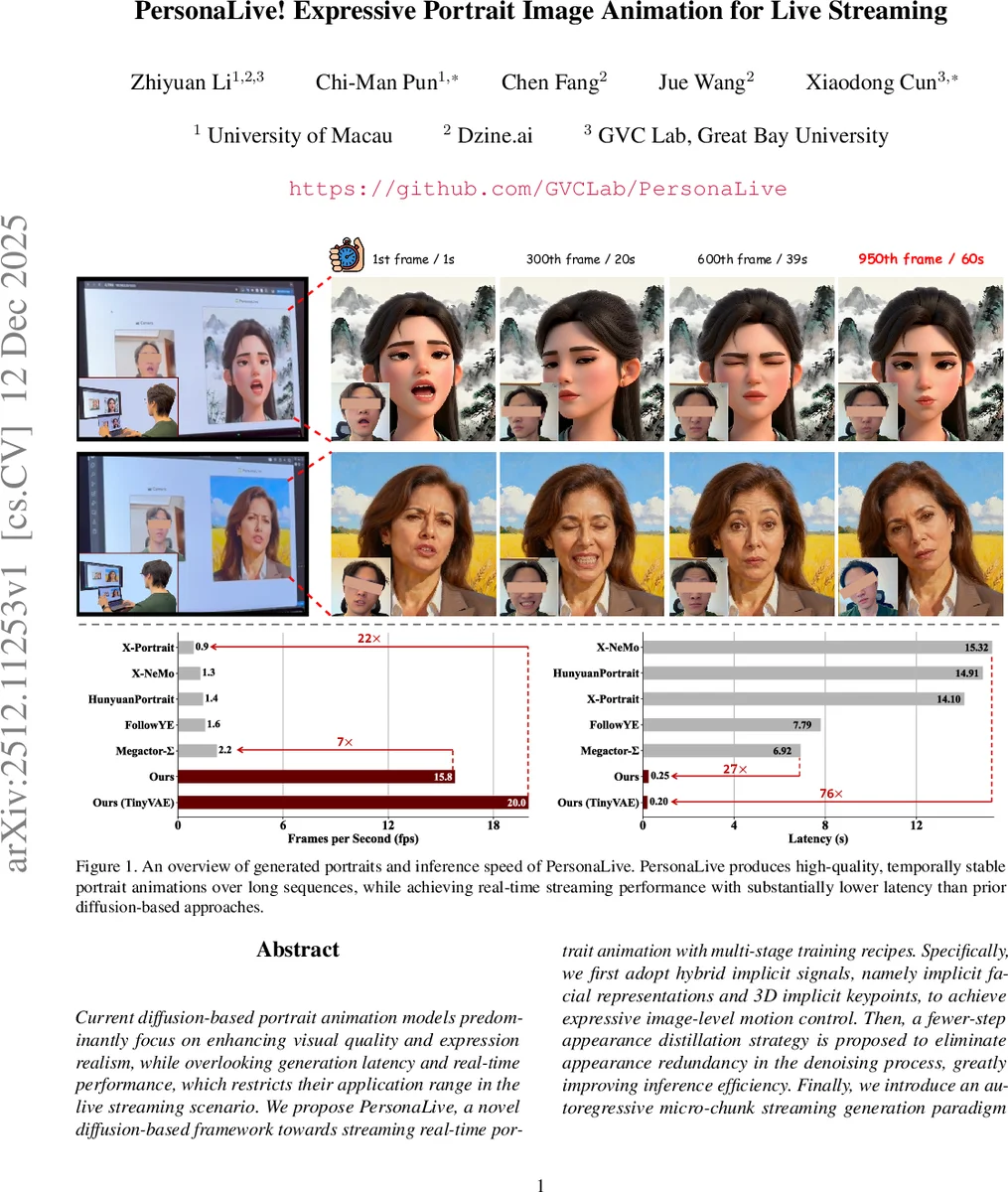
Current diffusion-based portrait animation models predominantly focus on enhancing visual quality and expression realism, while overlooking generation latency and real-time performance, which restricts their application range in the live streaming scenario. We propose PersonaLive, a novel diffusion-based framework towards streaming real-time portrait animation with multi-stage training recipes. Specifically, we first adopt hybrid implicit signals, namely implicit facial representations and 3D implicit keypoints, to achieve expressive image-level motion control. Then, a fewer-step appearance distillation strategy is proposed to eliminate appearance redundancy in the denoising process, greatly improving inference efficiency. Finally, we introduce an autoregressive micro-chunk streaming generation paradigm equipped with a sliding training strategy and a historical keyframe mechanism to enable low-latency and stable long-term video generation. Extensive experiments demonstrate that PersonaLive achieves state-of-the-art performance with up to 7-22x speedup over prior diffusion-based portrait animation models.
💡 Research Summary
PersonaLive tackles the long‑standing gap between high‑quality diffusion‑based portrait animation and the low‑latency demands of live streaming. Existing methods achieve impressive visual fidelity by using many denoising steps (often >20) and by processing long videos as independent fixed‑length chunks. This design leads to high computational cost, large inference latency, and error accumulation across chunk boundaries—issues that make them unsuitable for real‑time broadcast scenarios.
The paper introduces a three‑stage pipeline that directly addresses these problems.
Stage 1 – Image‑level Hybrid Motion Training. Instead of relying solely on 2‑D landmarks or raw motion frames, PersonaLive fuses two implicit motion signals: (1) a 1‑D facial embedding extracted by an implicit facial representation network, which captures fine‑grained expression dynamics, and (2) 3‑D implicit keypoints (rotation, translation, scale) obtained from a pretrained 3‑D pose estimator. The facial embedding is injected into the diffusion UNet via cross‑attention, while the 3‑D keypoints are projected to pixel space and fed through a PoseGuider module. This hybrid control enables simultaneous manipulation of local facial expressions and global head pose, offering richer and more controllable motion than prior ControlNet‑based approaches.
Stage 2 – Fewer‑step Appearance Distillation. The authors observe that the structural layout and motion of a portrait are largely settled within the first few denoising steps; later steps mainly refine texture, lighting, and subtle details. To eliminate this redundancy, they train a distilled diffusion model that operates with a compact sampling schedule (as few as 4–6 steps). During training, a random denoising step n is sampled, the model runs n iterations, and the resulting latent is decoded to an image. A hybrid loss (L2 + LPIPS + adversarial) supervises the output, while gradients are back‑propagated only through the final step to keep memory usage low. Stochastic step sampling ensures that every intermediate timestep receives supervision over the course of training. This distillation yields a 7–22× speedup with negligible loss in visual quality.
Stage 3 – Micro‑chunk Streaming Video Generation. To generate long video streams, PersonaLive abandons uniform‑noise chunk processing. It partitions each denoising window into N micro‑chunks, each assigned a progressively higher noise level. After each denoising step the first micro‑chunk becomes clean and is emitted, the window slides forward by one chunk, and a fresh noisy chunk is appended. This autoregressive micro‑chunk paradigm produces frames continuously without overlapping regions, dramatically reducing latency. However, autoregressive generation suffers from exposure bias (training‑inference mismatch) and error accumulation. The paper mitigates these issues with two mechanisms: (i) a Sliding Training Strategy that simulates the streaming process during training, feeding the model its own noisy predictions rather than only ground‑truth frames; and (ii) a Historical Keyframe Mechanism that selects stable past frames as auxiliary references, reinforcing temporal coherence over long sequences.
Extensive experiments on diverse streaming datasets demonstrate that PersonaLive matches or exceeds state‑of‑the‑art diffusion models on quantitative metrics (FID, LPIPS, PSNR) while achieving real‑time frame rates (up to 30 FPS on a single RTX 3090). Ablation studies confirm that each component—hybrid motion signals, appearance distillation, micro‑chunk streaming, sliding training, and historical keyframes—contributes significantly to the final performance.
In summary, PersonaLive delivers a practical solution for real‑time, high‑quality portrait animation in live‑streaming contexts. By integrating hybrid implicit motion control, aggressive step reduction through distillation, and a novel micro‑chunk streaming architecture with training‑time bias correction, the system bridges the gap between diffusion‑based generative power and the stringent latency constraints of broadcast‑grade applications. Future work may extend the framework to multi‑person scenes, higher resolutions, and interactive user‑driven motion editing.
Comments & Academic Discussion
Loading comments...
Leave a Comment