amc: The Automated Mission Classifier for Telescope Bibliographies
Telescope bibliographies record the pulse of astronomy research by capturing publication statistics and citation metrics for telescope facilities. Robust and scalable bibliographies ensure that we can measure the scientific impact of our facilities and archives. However, the growing rate of publications threatens to outpace our ability to manually label astronomical literature. We therefore present the Automated Mission Classifier (amc), a tool that uses large language models (LLMs) to identify and categorize telescope references by processing large quantities of paper text. A modified version of amc performs well on the TRACS Kaggle challenge, achieving a macro $F_1$ score of 0.84 on the held-out test set. amc is valuable for other telescopes beyond TRACS; we developed the initial software for identifying papers that featured scientific results by NASA missions. Additionally, we investigate how amc can also be used to interrogate historical datasets and surface potential label errors. Our work demonstrates that LLM-based applications offer powerful and scalable assistance for library sciences.
💡 Research Summary
The paper presents the Automated Mission Classifier (amc), a system that leverages large language models (LLMs) to automatically identify and categorize telescope and mission references within the astronomical literature. The motivation stems from the growing volume of publications, which outpaces the capacity of human librarians to manually curate telescope bibliographies—critical resources for measuring scientific impact, allocating funding, and guiding operational decisions for observatories and data archives.
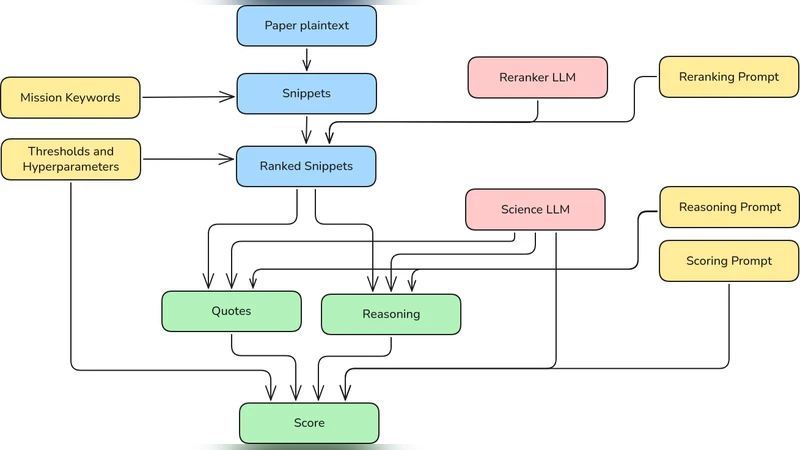
The amc pipeline consists of four main stages. First, textual content (abstracts, keywords, and selected sections of the full text) is extracted and pre‑processed to fit within the token limits of the chosen LLM. Second, a carefully engineered prompt asks the model to list all observatories or missions mentioned in the paper, effectively turning the classification task into a question‑answering problem. Third, a modest amount of labeled data (approximately 2 000 papers) is used to fine‑tune the base LLM, with techniques such as randomizing label order and applying class‑frequency weighting to mitigate label imbalance. Finally, rule‑based post‑processing normalizes observatory names and removes any impossible labels generated by the model.
The system is evaluated on the Telescope Archives and Catalogs System (TRACS) Kaggle challenge dataset, which contains over 10 000 papers annotated with more than 30 multi‑label telescope categories. The data are split into 80 % training, 10 % validation, and 10 % test sets, and performance is measured using macro‑averaged F₁. A baseline that only uses prompting without fine‑tuning achieves a macro F₁ of 0.77. By incorporating label‑order randomization, class weighting, and a brief fine‑tuning phase, amc raises the macro F₁ to 0.84 on the held‑out test set, demonstrating robust performance across both high‑profile facilities (e.g., HST, JWST, VLT) and smaller ground‑based networks.
Beyond the benchmark, the authors explore practical applications. They redeploy amc to scan recent NASA mission papers, achieving a five‑fold speed increase compared with manual curation while maintaining comparable accuracy. They also use the model to audit historical bibliographies: by flagging papers where amc’s predictions disagree with existing labels, they identified 24 genuine labeling errors out of 200 flagged items (≈12 %). This automated error‑detection dramatically reduces the workload for human curators and improves the overall reliability of the bibliography. Additionally, the system can be extended to new observatories with only a handful of example papers, illustrating its scalability.
Limitations are acknowledged. LLMs occasionally hallucinate observatory names that are not present in the source text, necessitating a post‑processing filter that eliminates impossible entries; even with this safeguard, a residual error rate of about 1 % remains. Performance also degrades for extremely rare labels, indicating that further data or specialized fine‑tuning may be required for niche facilities. The authors propose future work involving multimodal inputs (e.g., figures, tables) and domain‑specific pre‑training to further reduce hallucinations and improve rare‑label detection.
In summary, amc demonstrates that LLM‑driven automation can effectively support the creation and maintenance of telescope bibliographies. By delivering high‑accuracy multi‑label classification, rapid processing of new literature, and automated quality control of existing records, the system offers a scalable solution for library and information science in astronomy, paving the way for more data‑driven management of scientific infrastructure.