High-Performance DBMSs with io_uring: When and How to use it
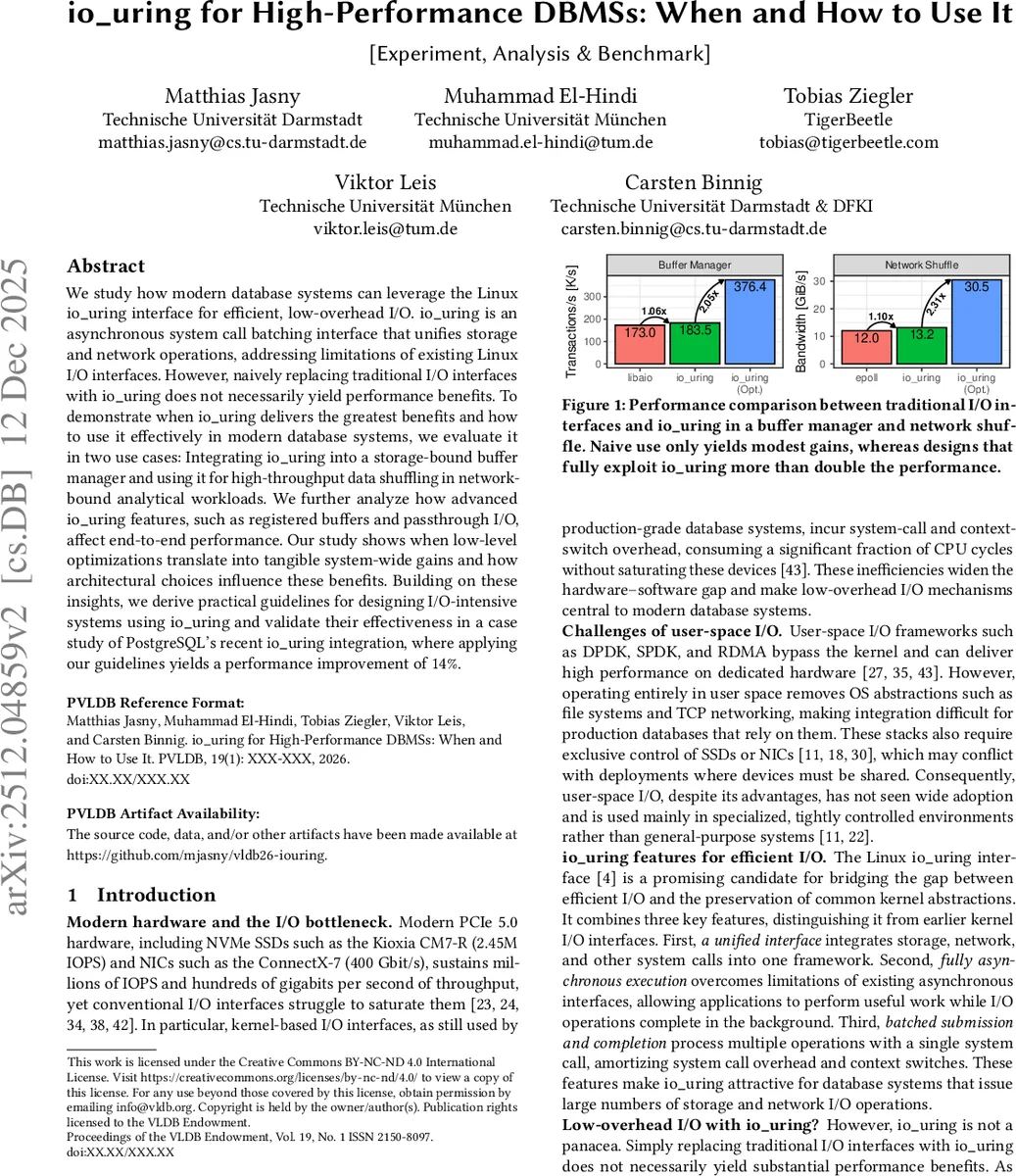
We study how modern database systems can leverage the Linux io_uring interface for efficient, low-overhead I/O. io_uring is an asynchronous system call batching interface that unifies storage and network operations, addressing limitations of existing Linux I/O interfaces. However, naively replacing traditional I/O interfaces with io_uring does not necessarily yield performance benefits. To demonstrate when io_uring delivers the greatest benefits and how to use it effectively in modern database systems, we evaluate it in two use cases: Integrating io_uring into a storage-bound buffer manager and using it for high-throughput data shuffling in network-bound analytical workloads. We further analyze how advanced io_uring features, such as registered buffers and passthrough I/O, affect end-to-end performance. Our study shows when low-level optimizations translate into tangible system-wide gains and how architectural choices influence these benefits. Building on these insights, we derive practical guidelines for designing I/O-intensive systems using io_uring and validate their effectiveness in a case study of PostgreSQL’s recent io_uring integration, where applying our guidelines yields a performance improvement of 14%.
💡 Research Summary
The paper investigates how modern database management systems (DBMSs) can exploit the Linux io_uring interface to close the performance gap between high‑speed hardware (PCIe 5.0 NVMe SSDs delivering millions of IOPS and 400 Gbps NICs) and traditional I/O stacks that are limited by system‑call and context‑switch overhead. The authors argue that a naïve swap of read/write, epoll, or libaio with io_uring yields only marginal gains, because the real benefits of io_uring stem from its three core capabilities: a unified asynchronous API, true non‑blocking execution, and batched submission/completion via shared ring buffers (SQ and CQ).
To answer three research questions—when to use io_uring, how to integrate it, and how to tune it—the study presents two complementary use cases that represent the two dominant bottlenecks in DBMS workloads: (1) a storage‑bound buffer manager that handles page faults, evictions, and write‑backs on an NVMe SSD, and (2) a network‑bound data‑shuffling component in a distributed analytical engine that streams data over a 400 Gbps fabric. For each case the authors first implement a baseline that simply replaces the existing I/O calls with io_uring, then progressively apply optimizations that fully exploit io_uring’s design.
In the buffer‑manager case, the baseline improves throughput by only 1.06×. By batching reads and writes (e.g., 16‑64 operations per io_uring_enter), registering buffers with io_uring_register, pinning them in memory, and using the DEFER_TASKRUN flag to avoid unwanted kernel‑user preemptions, the authors achieve a 2.05× increase in overall transaction throughput. Micro‑benchmarks show that a batch of 16 operations reduces per‑operation CPU cycles by roughly five‑to‑six times compared with single‑syscall submissions, and that registered buffers eliminate the extra memcpy and page‑fault costs that dominate NVMe access latency.
In the network‑shuffling case, the naïve replacement of epoll with io_uring yields a modest 1.10× speedup. The authors then enable SQPoll mode (eliminating submission syscalls), employ multishot and passthrough I/O to coalesce a stream of socket reads/writes into a single request, and tune the batch size to match the NIC’s completion queue depth. This redesign more than doubles effective bandwidth, delivering a 2.31× improvement and reducing end‑to‑end latency by over 30 % on a 400 Gbps link.
The paper also delves into io_uring’s internal execution paths. Inline execution handles operations that can complete immediately (e.g., data already in the socket buffer), non‑blocking execution installs internal event handlers for operations that become ready later, and blocking operations fall back to worker threads (io_worker). The authors measure that forcing operations onto worker threads adds ~7 µs of overhead per request, underscoring the importance of keeping critical DBMS paths on the inline or non‑blocking paths. They also discuss the impact of task‑work handling: the default COOP_TASKRUN mode may trigger inter‑processor interrupts (IPIs) on any kernel‑user transition, harming cache locality, whereas DEFER_TASKRUN confines task work to explicit io_uring_enter calls, giving the application full control and eliminating spurious preemptions.
From these experiments the authors derive practical guidelines for DBMS designers:
- Target high‑intensity I/O scenarios (millions of IOPS or hundreds of Gbps) where the amortization of syscalls and context switches matters.
- Design around batching – issue groups of reads/writes that naturally arise (e.g., buffer‑pool eviction, group commits, shuffle blocks) and tune batch size to balance latency and throughput.
- Register and pin buffers to avoid per‑operation memory copies and page‑fault overhead, especially for large sequential I/O on NVMe devices.
- Prefer inline or non‑blocking execution; avoid forcing operations onto worker threads unless unavoidable (e.g., fsync).
- Use SQPoll for ultra‑low‑latency submission when the workload can tolerate a dedicated kernel poll thread, and pair it with DEFER_TASKRUN to prevent unwanted task‑work preemptions.
- Leverage advanced features such as multishot, passthrough I/O, and request linking for network‑heavy workloads.
To validate the generality of these guidelines, the authors apply them to PostgreSQL’s recent io_uring backend. The baseline io_uring integration already gave ~10 % improvement over the traditional libaio path; after incorporating the derived optimizations (larger batches, buffer registration, DEFER_TASKRUN, and SQPoll where appropriate) PostgreSQL achieved an additional 14 % speedup in OLTP benchmarks, confirming that the principles scale to production‑grade systems.
In conclusion, the study demonstrates that io_uring is not a silver bullet; its performance benefits materialize only when DBMS architects redesign critical I/O components to align with io_uring’s asynchronous, batched execution model and exploit its advanced features. The paper provides a thorough empirical foundation and actionable design patterns that enable database systems to fully harness modern storage and networking hardware through io_uring.
Comments & Academic Discussion
Loading comments...
Leave a Comment