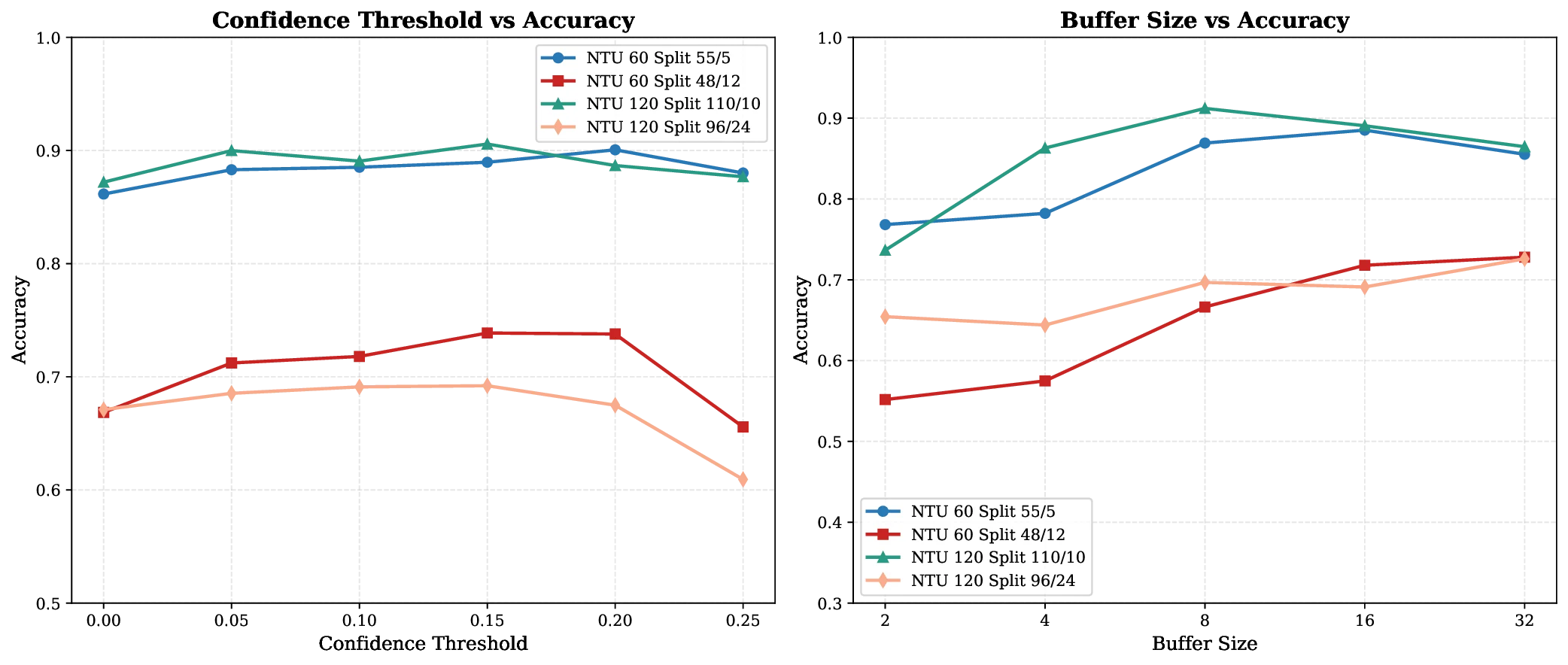
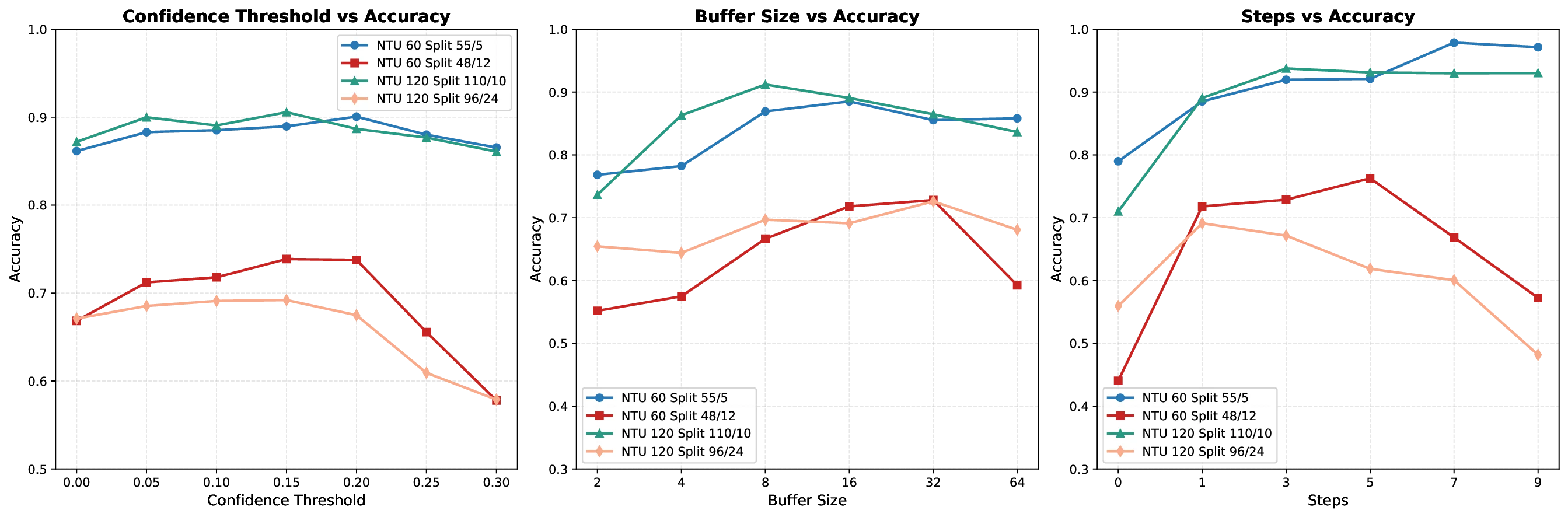
📝 Original Info
- Title: DynaPURLS: Dynamic Refinement of Part-aware Representations for Skeleton-based Zero-Shot Action Recognition
- ArXiv ID: 2512.11941
- Date: 2025-12-12
- Authors: Jingmin Zhu, Anqi Zhu, James Bailey, Jun Liu, Hossein Rahmani, Mohammed Bennamoun, Farid Boussaid, Qiuhong Ke
📝 Abstract
Zero-shot skeleton-based action recognition (ZS-SAR) is fundamentally constrained by prevailing approaches that rely on aligning skeleton features with static, class-level semantics. This coarse-grained alignment fails to bridge the domain shift between seen and unseen classes, thereby impeding the effective transfer of fine-grained visual knowledge. To address these limitations, we introduce \textbf{DynaPURLS}, a unified framework that establishes robust, multi-scale visual-semantic correspondences and dynamically refines them at inference time to enhance generalization. Our framework leverages a large language model to generate hierarchical textual descriptions that encompass both global movements and local body-part dynamics. Concurrently, an adaptive partitioning module produces fine-grained visual representations by semantically grouping skeleton joints. To fortify this fine-grained alignment against the train-test domain shift, DynaPURLS incorporates a dynamic refinement module. During inference, this module adapts textual features to the incoming visual stream via a lightweight learnable projection. This refinement process is stabilized by a confidence-aware, class-balanced memory bank, which mitigates error propagation from noisy pseudo-labels. Extensive experiments on three large-scale benchmark datasets, including NTU RGB+D 60/120 and PKU-MMD, demonstrate that DynaPURLS significantly outperforms prior art, setting new state-of-the-art records. The source code is made publicly available at https://github.com/Alchemist0754/DynaPURLS
💡 Deep Analysis
Deep Dive into DynaPURLS: Dynamic Refinement of Part-aware Representations for Skeleton-based Zero-Shot Action Recognition.
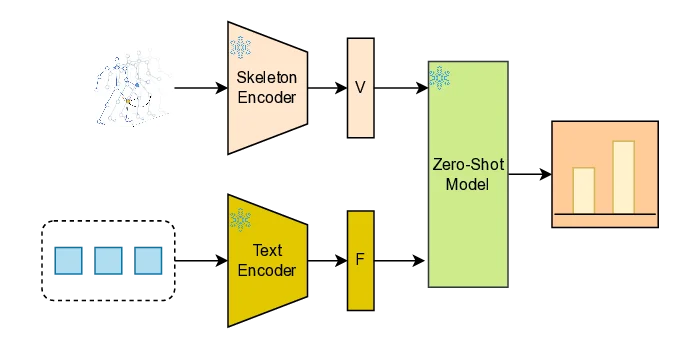
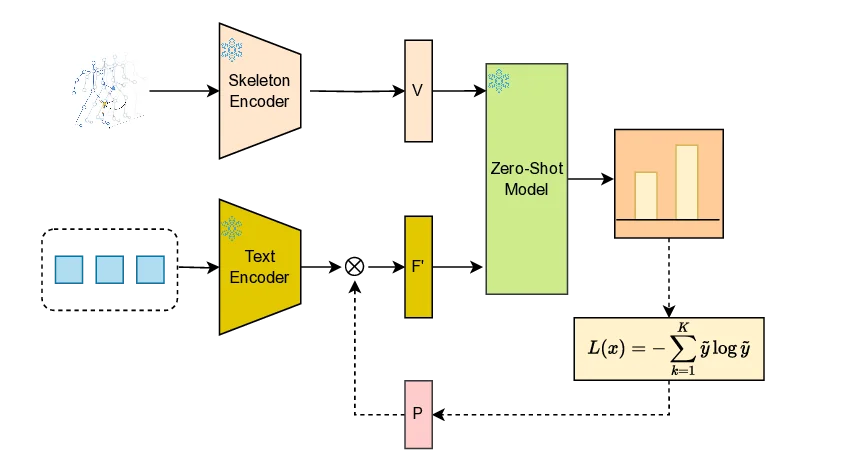
Zero-shot skeleton-based action recognition (ZS-SAR) is fundamentally constrained by prevailing approaches that rely on aligning skeleton features with static, class-level semantics. This coarse-grained alignment fails to bridge the domain shift between seen and unseen classes, thereby impeding the effective transfer of fine-grained visual knowledge. To address these limitations, we introduce \textbf{DynaPURLS}, a unified framework that establishes robust, multi-scale visual-semantic correspondences and dynamically refines them at inference time to enhance generalization. Our framework leverages a large language model to generate hierarchical textual descriptions that encompass both global movements and local body-part dynamics. Concurrently, an adaptive partitioning module produces fine-grained visual representations by semantically grouping skeleton joints. To fortify this fine-grained alignment against the train-test domain shift, DynaPURLS incorporates a dynamic refinement module.
📄 Full Content
1
DynaPURLS: Dynamic Refinement of Part-aware
Representations for Skeleton-based Zero-Shot
Action Recognition
Jingmin Zhu, Anqi Zhu, James Bailey, Jun Liu, Hossein Rahmani, Mohammed Bennamoun, Farid Boussaid,
and Qiuhong Ke∗
Index Terms—Skeleton-Based Action Recognition, Zero-Shot Learning, Dynamic Refinement, Test-Time Adaptation, Large Language Models,
Cross-Modal Alignment.
Abstract—Zero-shot skeleton-based action recognition (ZS-SAR) is fundamentally constrained by prevailing approaches that rely on
aligning skeleton features with static, class-level semantics. This coarse-grained alignment fails to bridge the domain shift between
seen and unseen classes, thereby impeding the effective transfer of fine-grained visual knowledge. To address these limitations, we
introduce DynaPURLS, a unified framework that establishes robust, multi-scale visual-semantic correspondences and dynamically
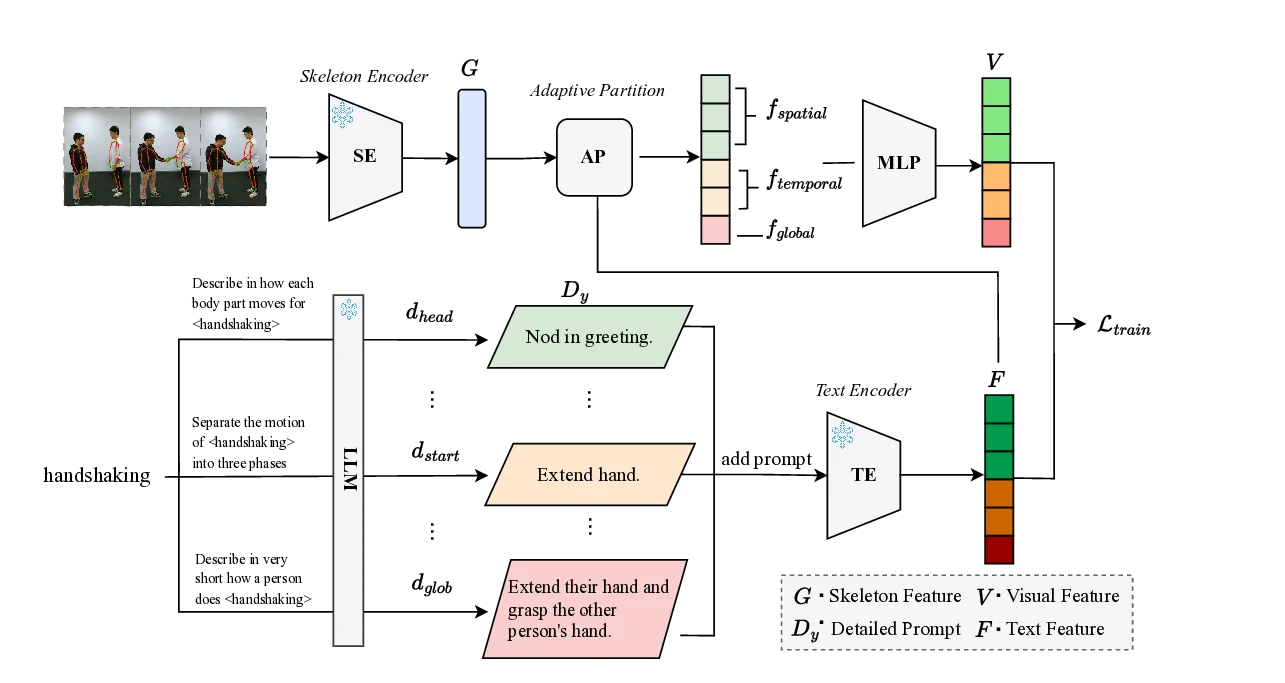
refines them at inference time to enhance generalization. Our framework leverages a large language model to generate hierarchical
textual descriptions that encompass both global movements and local body-part dynamics. Concurrently, an adaptive partitioning
module produces fine-grained visual representations by semantically grouping skeleton joints. To fortify this fine-grained alignment
against the train-test domain shift, DynaPURLS incorporates a dynamic refinement module. During inference, this module adapts textual
features to the incoming visual stream via a lightweight learnable projection. This refinement process is stabilized by a confidence-aware,
class-balanced memory bank, which mitigates error propagation from noisy pseudo-labels. Extensive experiments on three large-scale
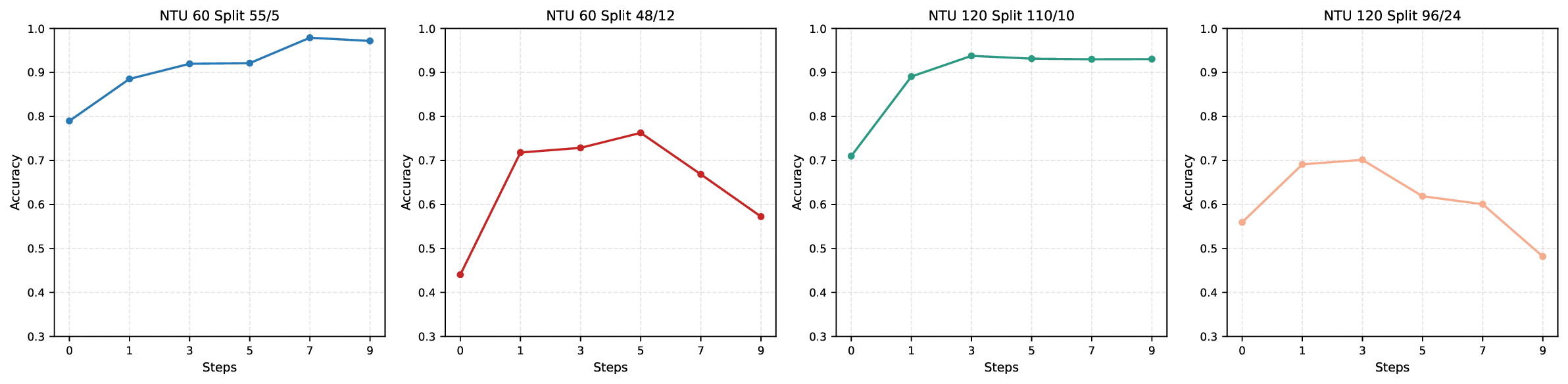
benchmark datasets, including NTU RGB+D 60/120 and PKU-MMD, demonstrate that DynaPURLS significantly outperforms prior art,
setting new state-of-the-art records. The source code is made publicly available at https://github.com/Alchemist0754/DynaPURLS
✦
1
INTRODUCTION
H
UMAN Action Recognition (HAR) has emerged as a
cornerstone technology in computer vision, enabling
machines to comprehend human behaviors from sensory
data. This capability is fundamental to transformative appli-
cations across diverse domains, including immersive virtual
reality [1], [2], intelligent transportation [3], [4], large-scale
video retrieval [5], and human-robot collaboration [6], [7].
While RGB-based solutions have historically dominated HAR
research, buoyed by massive annotated datasets [8], [9], the
maturation of human pose estimation [10] and depth-sensing
hardware [11], [12] has positioned 3D skeleton sequences
as a compelling alternative. Skeleton data offers distinct
advantages: it is computationally efficient, inherently privacy-
preserving, and robust to environmental variations such as
background clutter and lighting changes [13], [14], [15].
Despite remarkable progress in fully supervised skeleton-
based HAR [16], [17], [18], [19], [20], [21], these approaches
are constrained by their reliance on exhaustive annotations
for all action classes. This paradigm falters when confronted
with real-world scenarios involving rare, hazardous, or
•
J. Zhu and A. Zhu are with Monash University.
E-mail: jingmin.zhu1@monash.edu, maggie.zhu@monash.edu
•
J. Bailey is with University of Melbourne.
E-mail: baileyj@unimelb.edu.au
•
H. Rahmani and J. Liu are with Lancaster University.
E-mail: h.rahmani@lancaster.ac.uk, j.liu81@lancaster.ac.uk
•
M. Bennamoun and F. Boussaid are with University of Western Australia.
E-mail: mohammed.bennamoun@uwa.edu.au, farid.boussaid@uwa.edu.au
•
Q. Ke is with Monash University.
E-mail: Qiuhong.Ke@monash.edu
•
∗Corresponding author.
Fig. 1: An example illustrating the limitations of global-only alignment.
A seen class (“Hit another person with something”) and an unseen class
(“Shoot at the basket”) from NTU-RGB+D 120 [12] exhibit different
overall motions but share similar local hand movements. Effective
knowledge transfer in ZSL requires capturing such fine-grained, part-
level similarities.
expensive-to-collect actions, creating a critical deployment
bottleneck. Zero-Shot Learning (ZSL) offers a compelling
path forward by transferring knowledge from seen to unseen
categories through a shared semantic space, enabling the
recognition of novel actions without direct training examples.
However, existing skeleton-based ZSL methods [23], [24],
[25] predominantly depend on aligning a single, global
motion feature with a corresponding class-level semantic
embedding. This coarse alignment strategy is insufficient for
the nuanced demands of action recognition. As illustrated
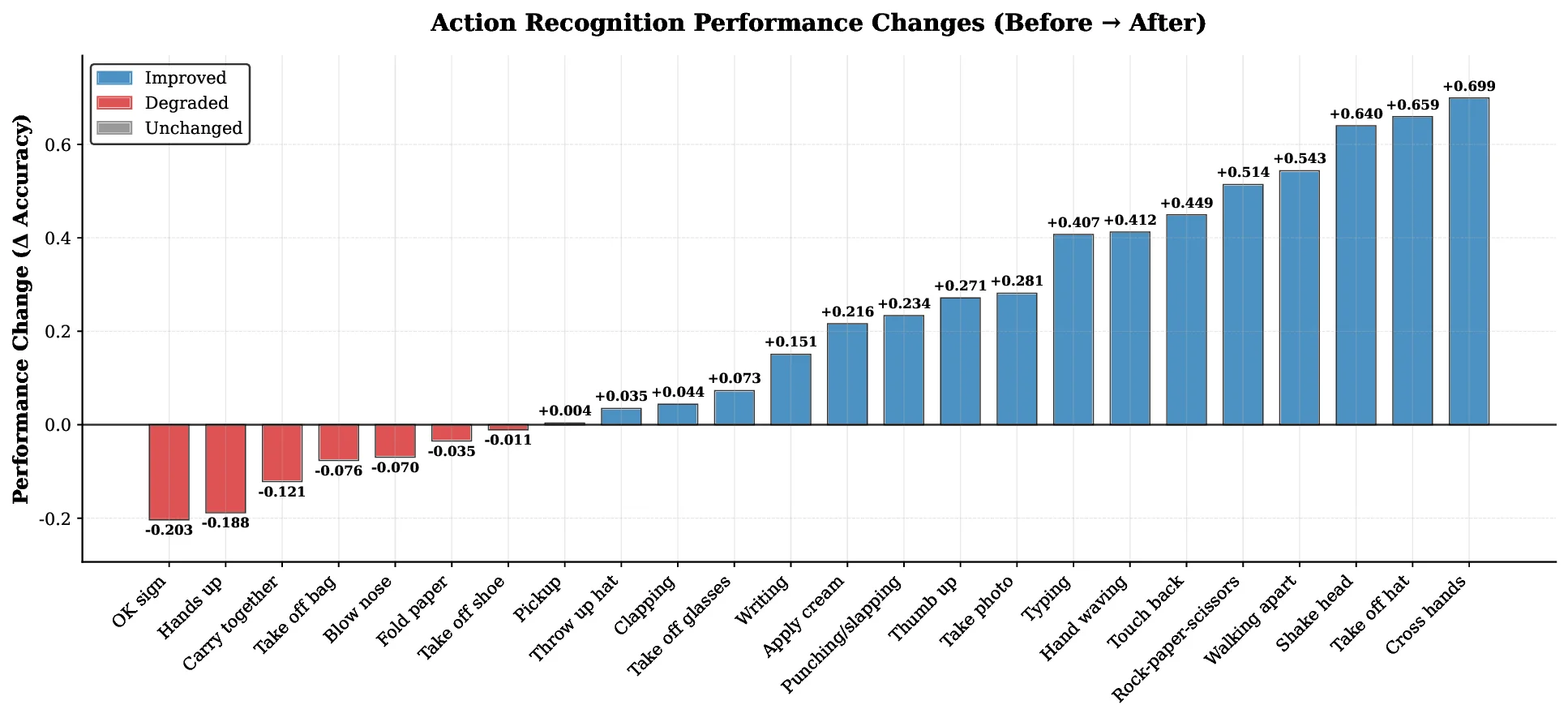
in Figure 1, actions with disparate global patterns (e.g.,
“Hit another person with something” vs. “Shoot at the
basket”) may share remarkably similar fine-grained motions
arXiv:2512.11941v1 [cs.CV] 12 Dec 2025
2
(a) Pre-adaptation (55/5 split)
(b) Post-adaptation (55/5 split)
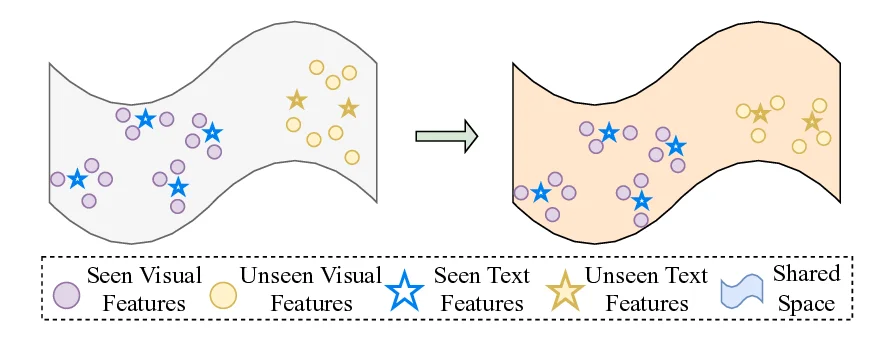
Fig. 2: t-SNE visualization of feature distributions before and after test-
time feature refinement. Sub
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.