📝 Original Info
- Title: MedAI: Evaluating TxAgent’s Therapeutic Agentic Reasoning in the NeurIPS CURE-Bench Competition
- ArXiv ID: 2512.11682
- Date: 2025-12-12
- Authors: Tim Cofala, Christian Kalfar, Jingge Xiao, Johanna Schrader, Michelle Tang, Wolfgang Nejdl
📝 Abstract
Therapeutic decision-making in clinical medicine constitutes a high-stakes domain in which AI guidance interacts with complex interactions among patient characteristics, disease processes, and pharmacological agents. Tasks such as drug recommendation, treatment planning, and adverse-effect prediction demand robust, multi-step reasoning grounded in reliable biomedical knowledge. Agentic AI methods, exemplified by TxAgent, address these challenges through iterative retrieval-augmented generation (RAG). TxAgent employs a fine-tuned Llama-3.1-8B model that dynamically generates and executes function calls to a unified biomedical tool suite (ToolUniverse), integrating FDA Drug API, OpenTargets, and Monarch resources to ensure access to current therapeutic information. In contrast to general-purpose RAG systems, medical applications impose stringent safety constraints, rendering the accuracy of both the reasoning trace and the sequence of tool invocations critical. These considerations motivate evaluation protocols treating token-level reasoning and tool-usage behaviors as explicit supervision signals. This work presents insights derived from our participation in the CURE-Bench NeurIPS 2025 Challenge, which benchmarks therapeutic-reasoning systems using metrics that assess correctness, tool utilization, and reasoning quality. We analyze how retrieval quality for function (tool) calls influences overall model performance and demonstrate performance gains achieved through improved tool-retrieval strategies. Our work was awarded the Excellence Award in Open Science. Complete information can be found at https://curebench.ai/.
💡 Deep Analysis
Deep Dive into MedAI: Evaluating TxAgent's Therapeutic Agentic Reasoning in the NeurIPS CURE-Bench Competition.
Therapeutic decision-making in clinical medicine constitutes a high-stakes domain in which AI guidance interacts with complex interactions among patient characteristics, disease processes, and pharmacological agents. Tasks such as drug recommendation, treatment planning, and adverse-effect prediction demand robust, multi-step reasoning grounded in reliable biomedical knowledge. Agentic AI methods, exemplified by TxAgent, address these challenges through iterative retrieval-augmented generation (RAG). TxAgent employs a fine-tuned Llama-3.1-8B model that dynamically generates and executes function calls to a unified biomedical tool suite (ToolUniverse), integrating FDA Drug API, OpenTargets, and Monarch resources to ensure access to current therapeutic information. In contrast to general-purpose RAG systems, medical applications impose stringent safety constraints, rendering the accuracy of both the reasoning trace and the sequence of tool invocations critical. These considerations motiv
📄 Full Content
MedAI: Evaluating TxAgent’s Therapeutic Agentic Reasoning in the
NeurIPS CURE-Bench Competition
Tim Cofala
L3S Research Center
tim.cofala@l3s.de
Christian Kalfar
L3S Research Center
christian.kalfar@l3s.de
Jingge Xiao
L3S Research Center
xiao@l3s.de
Johanna Schrader
L3S Research Center
schrader@l3s.de
Michelle Tang
L3S Research Center
tang@l3s.de
Wolfgang Nejdl
L3S Research Center
nejdl@L3S.de
Abstract
Therapeutic
decision-making
in
clinical
medicine constitutes a high-stakes domain in
which AI guidance interacts with complex
interactions among patient characteristics,
disease processes, and pharmacological agents.
Tasks such as drug recommendation, treatment
planning,
and
adverse-effect
prediction
demand robust, multi-step reasoning grounded
in reliable biomedical knowledge. Agentic AI
methods, exemplified by TxAgent, address
these challenges through iterative retrieval-
augmented
generation
(RAG).
TxAgent
employs a fine-tuned Llama-3.1-8B model
that dynamically generates and executes
function calls to a unified biomedical tool suite
(ToolUniverse), integrating FDA Drug API,
OpenTargets, and Monarch resources to ensure
access to current therapeutic information. In
contrast to general-purpose RAG systems,
medical applications impose stringent safety
constraints, rendering the accuracy of both
the reasoning trace and the sequence of tool
invocations critical.
These considerations
motivate evaluation protocols treating token-
level reasoning and tool-usage behaviors
as explicit supervision signals.
This work
presents insights derived from our participation
in the CURE-Bench NeurIPS 2025 Challenge,
which
benchmarks
therapeutic-reasoning
systems using metrics that assess correctness,
tool utilization, and reasoning quality.
We
analyze how retrieval quality for function (tool)
calls influences overall model performance
and demonstrate performance gains achieved
through improved tool-retrieval strategies. Our
work was awarded the Excellence Award in
Open Science. Complete information can be
found at curebench.ai.
1
Introduction
Therapeutic decision-making in clinical medicine
presents a demanding environment for artificial
intelligence. Clinicians routinely integrate hetero-
geneous information on patient characteristics, dis-
ease pathophysiology, comorbid conditions and the
pharmacological properties of candidate treatments.
AI systems intended to support such decisions must
therefore demonstrate not only competent predic-
tion capabilities but also the capacity to reason
through multi-step therapeutic processes in a man-
ner that is grounded in reliable biomedical knowl-
edge.
Recent advances in agentic AI (Tang et al., 2024;
Bran et al., 2024; Yao et al., 2023) and retrieval-
augmented generation (RAG) (Wei et al., 2025; Sun
et al., 2025; Wang et al., 2025) have introduced
new opportunities for building systems that can
navigate complex biomedical toolchains. Rather
than relying solely on parametric knowledge, agen-
tic approaches iteratively retrieve, evaluate, and
integrate external information sources through or-
chestrated tool use. These methods are promising
for therapeutic applications, where accurate access
to up-to-date drug and disease information is nec-
essary for safe model operation (Gao et al., 2025a).
However, general-purpose agentic frameworks are
not by themselves sufficient: medical contexts im-
pose stringent constraints on verifiability and errors
in either the reasoning trace or the sequence of tool
calls can propagate to clinically significant mis-
takes (Gorenshtein et al., 2025; Asgari et al., 2025;
Singhal et al., 2022; Thirunavukarasu et al., 2023).
As a result, evaluating therapeutic-reasoning sys-
tems requires protocols that directly assess reason-
ing quality, tool utilization, and the correctness of
answers and intermediate steps.
The Agentic Tool-Augmented Reasoning track
of the CURE-Bench NeurIPS 2025 Challenge es-
tablishes a rigorous framework for evaluating these
capabilities. By combining metrics for answer ac-
curacy, tool utilization, and reasoning validity with
expert human review, the challenge ensures that
agentic systems for therapeutic reasoning are as-
sessed with the necessary precision and care.
arXiv:2512.11682v1 [cs.AI] 12 Dec 2025
Building on the framework of this challenge, our
effort focused on enhancing TxAgent (Gao et al.,
2025a), an agentic therapeutic-reasoning system
built on a fine-tuned Llama-3.1-8B model equipped
with the ToolUniverse (Gao et al., 2025b), a uni-
fied suite of biomedical resources integrating FDA
drug data, OpenTargets associations, and Monarch
ontologies.
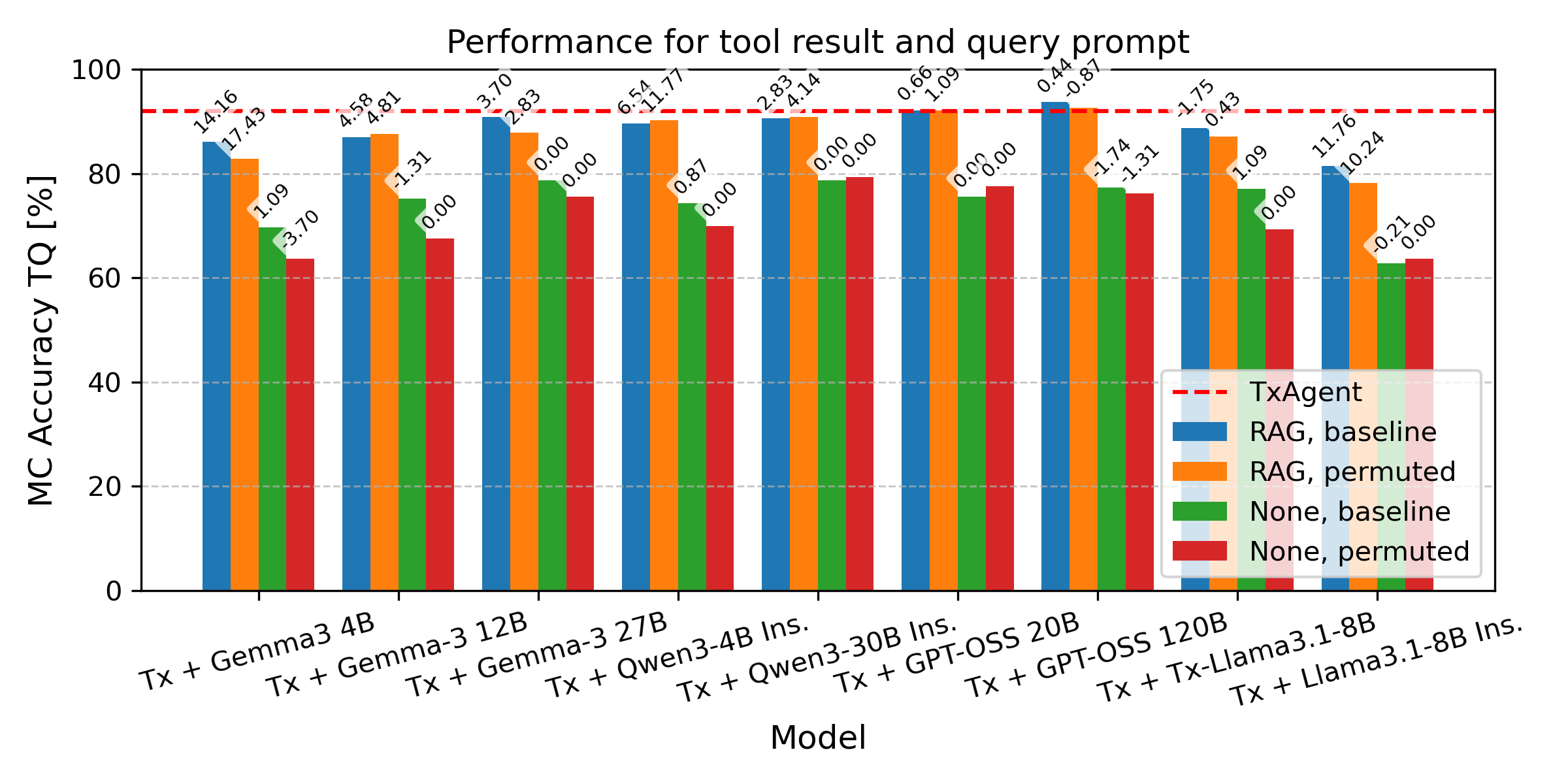
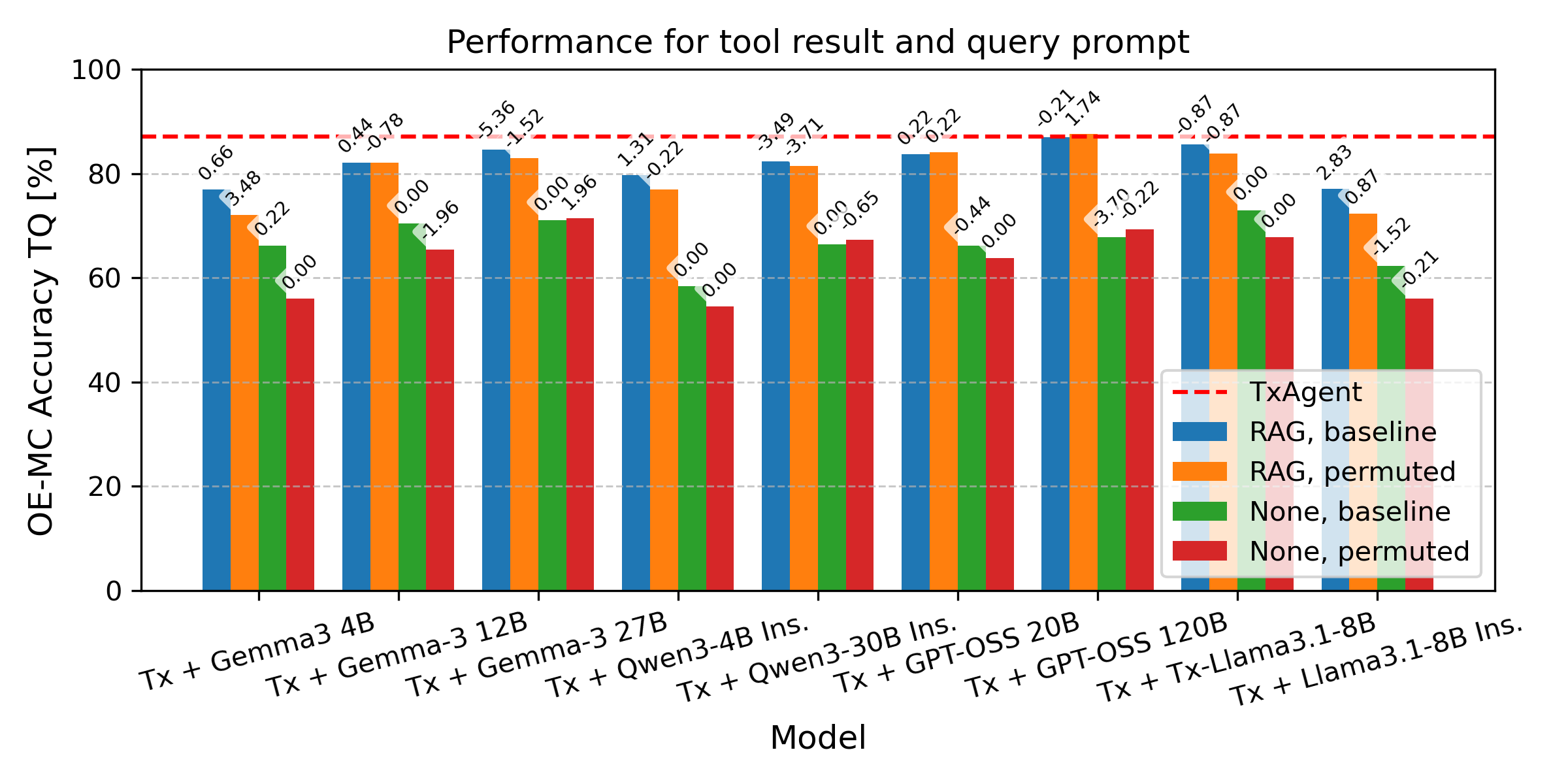
We conducted a detailed analysis of TxAgent’s
performance on the CURE-Bench challenge, with
a particular focus on retrieval quality for function
(tool) calls, as retrieval failures were frequently
responsible for downstream reasoning errors.
To address these issues, we investigated ap-
proaches to improve the system by:
1. Integrating DailyMed to access up-to-date
drug label info
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.