📝 Original Info
- Title: 프리필·디코드 분리형 FPGA LLM 가속기 PD Swap
- ArXiv ID: 2512.11550
- Date: 2025-12-12
- Authors: Yifan Zhang, Zhiheng Chen, Ye Qiao, Sitao Huang
📝 Abstract
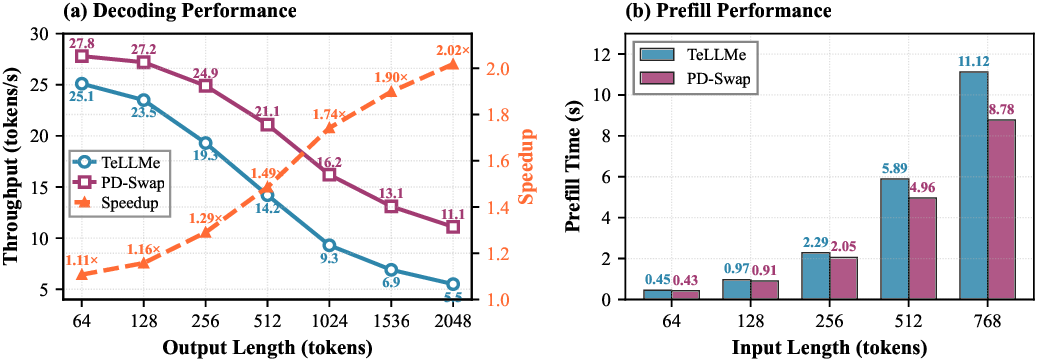
Aggressively quantized large language models (LLMs), such as BitNet-style 1.58-bit Transformers with ternary weights, make it feasible to deploy generative AI on low-power edge FPGAs. However, as prompts grow to tens of thousands of tokens, edge hardware performance drops sharply with sequence length due to quadratic prefill cost and rapidly increasing KV-cache bandwidth demands, making inference latency of longer context length a first-order system concern. Recent studies on LLMs expose a fundamental prefill-decode asymmetry: prefill is compute-bound and dominated by dense matrix-matrix operations, whereas decoding is memorybandwidth-bound and dominated by KV-cache traffic. A static accelerator must provision resources and a single dataflow for both regimes, leading to duplicated attention logic, underutilized fabric, and tight LUT/URAM limits that cap model size and usable context. We propose a prefill-decode disaggregated LLM accelerator, PD-Swap, that uses Dynamic Partial Reconfiguration (DPR) to time-multiplex the attention module on edge FPGAs. The core tablelookup ternary matrix multiplication and weight-buffering engines remain static, while the attention subsystem is a reconfigurable partition with two phase-specialized architectures: a compute-heavy, token-parallel prefill engine and a bandwidth-optimized, KV-cachecentric decoding engine. A roofline-inspired model and design space exploration jointly optimize reconfigurable-region size, parallelism under reconfiguration and routability constraints, and reconfiguration latency is hidden by computation latency. PD-Swap achieves up to 27 tokens/s decoding throughput, outperforming prior state-ofthe-art works by 1.3×-2.1× (larger gains at longer context lengths), without extra area cost.
Introduction Transformer-based large language models (LLMs) underpin many modern AI services, but their computation, memory, and bandwidth demands clash with the strict power and cost budgets of edge devices. Quantization is a key enabler for on-device LLM inference: BitNet-style 1.58-bit models show that ternary weights ({-1, 0, +1}) can approach full-precision accuracy while drastically reducing model size and replacing multiplications with low-cost operations. Combined with the reconfigurability and fine-grained parallelism of FPGAs, such models offer a promising path toward privacypreserving, low-latency LLM inference at the edge. Recent works [1, 2] have implemented end-to-end LLM accelerators with edge FPGAs, and they accelerate both prefill and autoregressive decoding on chip under tight power budgets and achieve Conference'17,
💡 Deep Analysis
Deep Dive into 프리필·디코드 분리형 FPGA LLM 가속기 PD Swap.
Aggressively quantized large language models (LLMs), such as BitNet-style 1.58-bit Transformers with ternary weights, make it feasible to deploy generative AI on low-power edge FPGAs. However, as prompts grow to tens of thousands of tokens, edge hardware performance drops sharply with sequence length due to quadratic prefill cost and rapidly increasing KV-cache bandwidth demands, making inference latency of longer context length a first-order system concern. Recent studies on LLMs expose a fundamental prefill-decode asymmetry: prefill is compute-bound and dominated by dense matrix-matrix operations, whereas decoding is memorybandwidth-bound and dominated by KV-cache traffic. A static accelerator must provision resources and a single dataflow for both regimes, leading to duplicated attention logic, underutilized fabric, and tight LUT/URAM limits that cap model size and usable context. We propose a prefill-decode disaggregated LLM accelerator, PD-Swap, that uses Dynamic Partial Reconfigu
📄 Full Content
PD-Swap: Prefill–Decode Logic Swapping for End-to-End LLM
Inference on Edge FPGAs via Dynamic Partial Reconfiguration
Yifan Zhang, Zhiheng Chen, Ye Qiao, and Sitao Huang
{yifanz58,zhihenc5,yeq6,sitaoh}@uci.edu
University of California, Irvine
Irvine, California, USA
Abstract
Aggressively quantized large language models (LLMs), such as
BitNet-style 1.58-bit Transformers with ternary weights, make it
feasible to deploy generative AI on low-power edge FPGAs. How-
ever, as prompts grow to tens of thousands of tokens, edge hardware
performance drops sharply with sequence length due to quadratic
prefill cost and rapidly increasing KV-cache bandwidth demands,
making inference latency of longer context length a first-order
system concern. Recent studies on LLMs expose a fundamental
prefill–decode asymmetry: prefill is compute-bound and dominated
by dense matrix–matrix operations, whereas decoding is memory-
bandwidth-bound and dominated by KV-cache traffic. A static ac-
celerator must provision resources and a single dataflow for both
regimes, leading to duplicated attention logic, underutilized fab-
ric, and tight LUT/URAM limits that cap model size and usable
context. We propose a prefill–decode disaggregated LLM accelera-
tor, PD-Swap, that uses Dynamic Partial Reconfiguration (DPR) to
time-multiplex the attention module on edge FPGAs. The core table-
lookup ternary matrix multiplication and weight-buffering engines
remain static, while the attention subsystem is a reconfigurable par-
tition with two phase-specialized architectures: a compute-heavy,
token-parallel prefill engine and a bandwidth-optimized, KV-cache-
centric decoding engine. A roofline-inspired model and design space
exploration jointly optimize reconfigurable-region size, parallelism
under reconfiguration and routability constraints, and reconfigura-
tion latency is hidden by computation latency. PD-Swap achieves up
to 27 tokens/s decoding throughput, outperforming prior state-of-
the-art works by 1.3×–2.1× (larger gains at longer context lengths),
without extra area cost.
1
Introduction
Transformer-based large language models (LLMs) underpin many
modern AI services, but their computation, memory, and bandwidth
demands clash with the strict power and cost budgets of edge
devices. Quantization is a key enabler for on-device LLM inference:
BitNet-style 1.58-bit models show that ternary weights ({−1, 0, +1})
can approach full-precision accuracy while drastically reducing
model size and replacing multiplications with low-cost operations.
Combined with the reconfigurability and fine-grained parallelism
of FPGAs, such models offer a promising path toward privacy-
preserving, low-latency LLM inference at the edge.
Recent works [1, 2] have implemented end-to-end LLM acceler-
ators with edge FPGAs, and they accelerate both prefill and autore-
gressive decoding on chip under tight power budgets and achieve
Conference’17, Washington, DC, USA
2025. ACM ISBN 978-x-xxxx-xxxx-x/YYYY/MM
https://doi.org/10.1145/nnnnnnn.nnnnnnn
competitive tokens/s compared to INT8 and FP16 designs. However,
study on these end-to-end accelerators with both prefill and decode
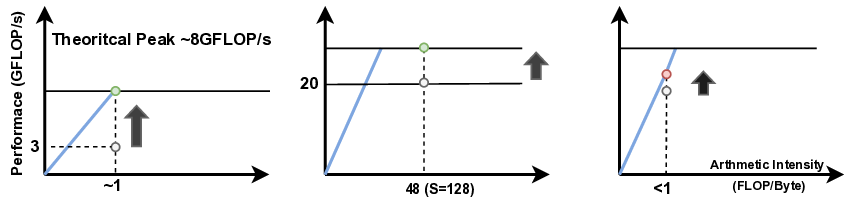
reveals a fundamental prefill-decode asymmetry. Prefill processes
the entire prompt in parallel and is dominated by matrix-matrix op-
erations, making it compute-bound and constrained by LUT/URAM
budget and timing closure. Decoding generates one token at a time,
repeatedly accessing the KV cache and weights; its arithmetic inten-
sity drops sharply and performance becomes dominated by DDR
bandwidth, which is quickly saturated even with 4-bit quantization.
A static edge accelerator must therefore provision hardware and a
single dataflow for both regimes, duplicating attention logic, con-
trol, and buffering and limiting model size, frequency, and usable
context length.
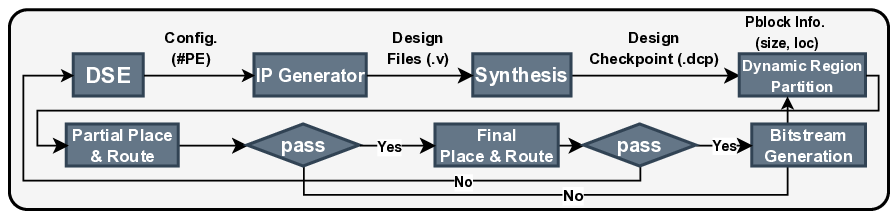
Modern FPGAs, including AMD Zynq and Versal families, sup-
port Dynamic Function Exchange (DFX), a vendor-integrated form
of dynamic and partial reconfiguration that allows part of the fabric
to be reprogrammed while the rest continues to operate. In the
DFX flow, the design is split into a static region and one or more re-
configurable partitions (RPs) that can host multiple reconfigurable
modules (RMs) loaded via partial bitstreams. For modest RP sizes,
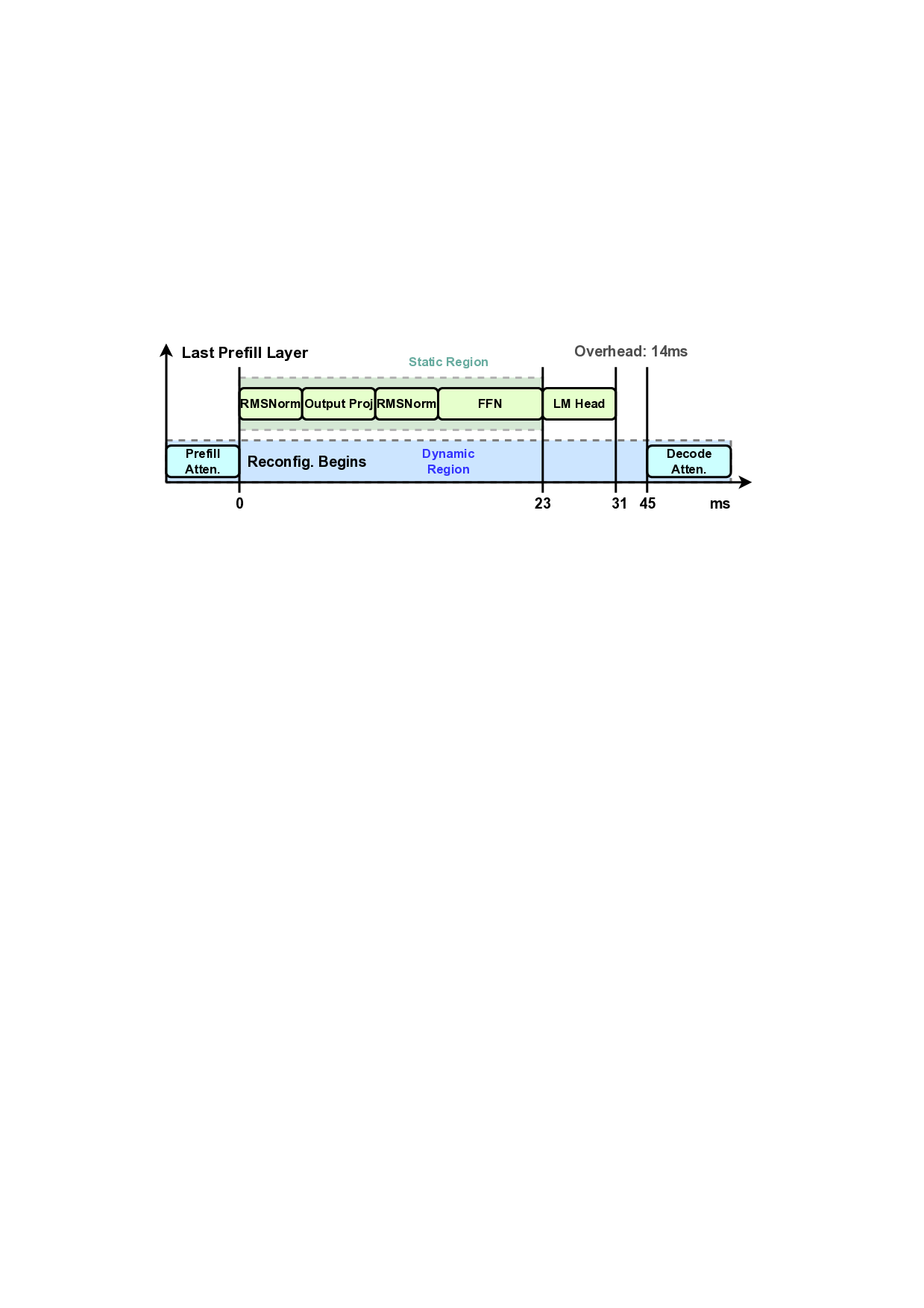
reconfiguration can complete in milliseconds. Recent works have
explored DPR-based FPGA accelerators for CNNs and small-scale
neural networks on edge devices [3–5]. However, these designs
mainly target vision workloads with static computation patterns,
and do not address the highly asymmetric and dynamic compute
and memory characteristics in autoregressive LLM inference.
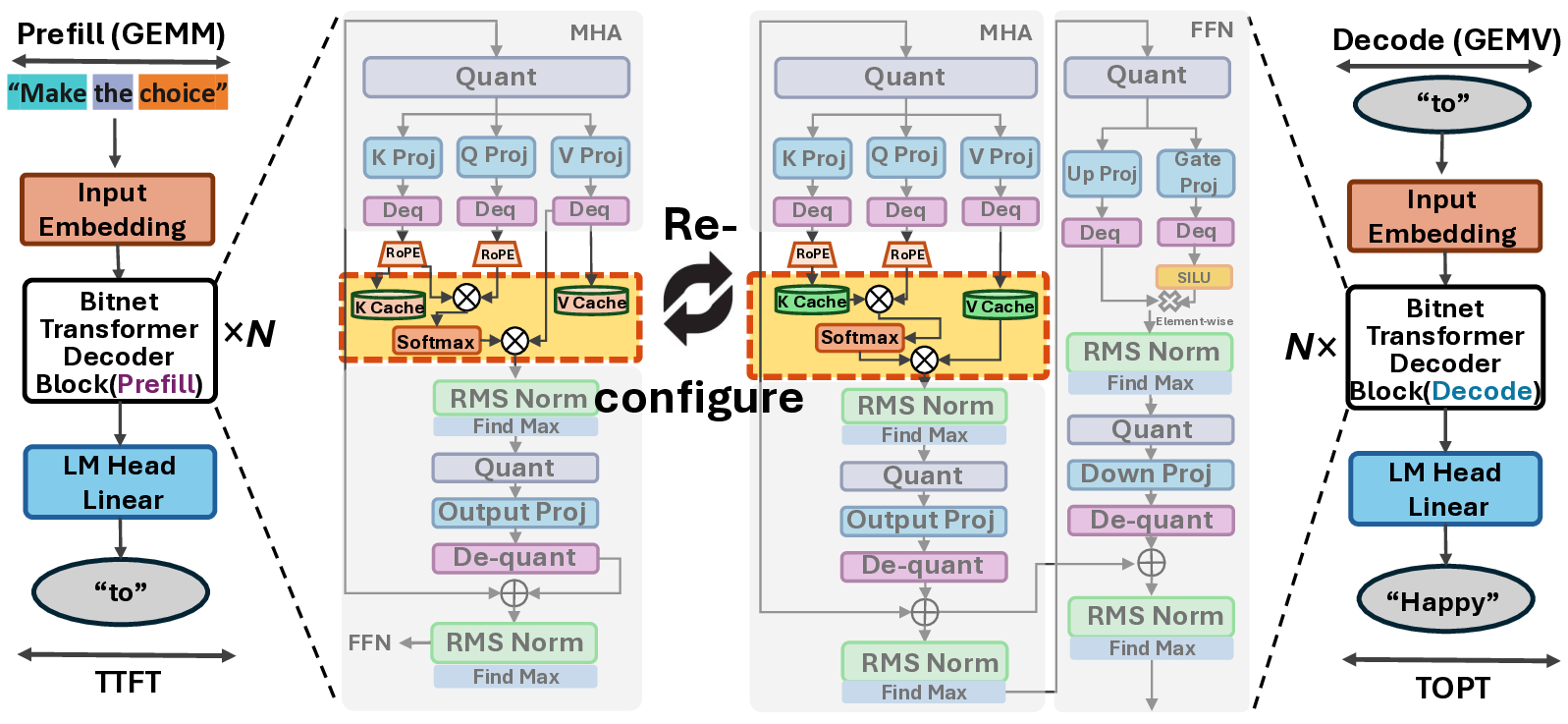
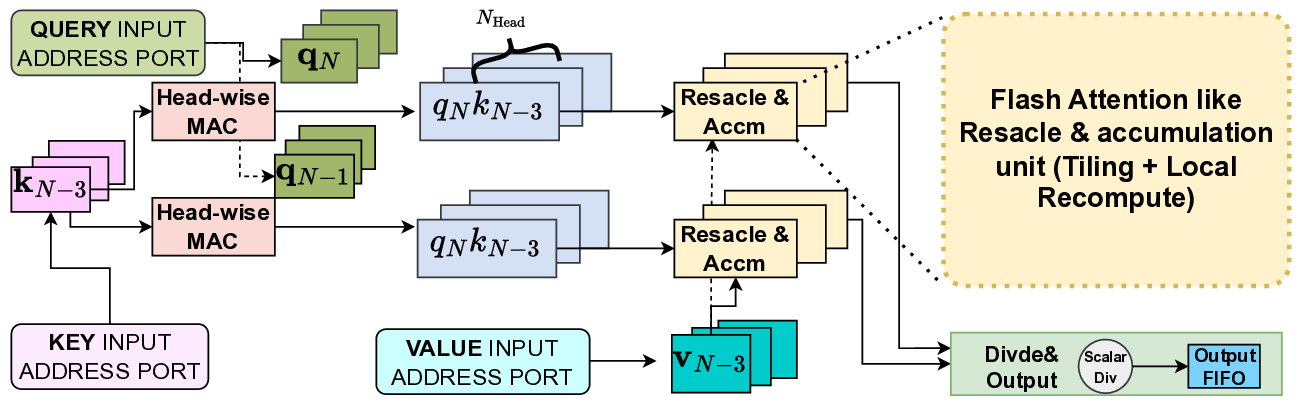
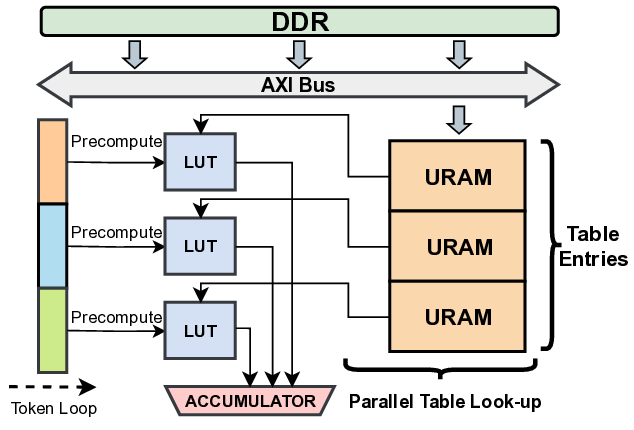
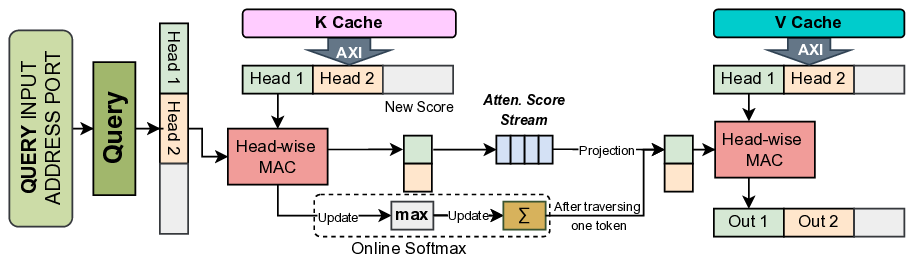
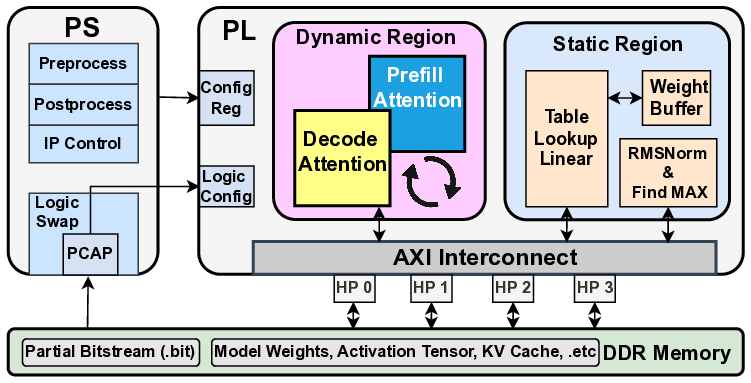
The prefill-decode asymmetry in LLM inference is a natural fit
for logic swapping on edge FPGAs. In our design, the ternary table-
lookup MatMul and weight-buffering engines, which are shared
by both phases, reside in the static region, while the attention sub-
system is implemented as a reconfigurable partition with two RMs:
a
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.