Applying reinforcement learning (RL) to real-world tasks requires converting informal descriptions into a formal Markov decision process (MDP), implementing an executable environment, and training a policy agent. Automating this process is challenging due to modeling errors, fragile code, and misaligned objectives, which often impede policy training. We introduce an agentic large language model (LLM)-based framework for automated MDP modeling and policy generation (A-LAMP), that automatically translates free-form natural language task descriptions into an MDP formulation and trained policy. The framework decomposes modeling, coding, and training into verifiable stages, ensuring semantic alignment throughout the pipeline. Across both classic control and custom RL domains, A-LAMP consistently achieves higher policy generation capability than a single state-of-the-art LLM model. Notably, even its lightweight variant, which is built on smaller language models, approaches the performance of much larger models. Failure analysis reveals why these improvements occur. In addition, a case study also demonstrates that A-LAMP generates environments and policies that preserve the task's optimality, confirming its correctness and reliability.
Deep Dive into 자동화된 MDP 모델링과 정책 생성을 위한 에이전트형 LLM 프레임워크 A‑LAMP.
Applying reinforcement learning (RL) to real-world tasks requires converting informal descriptions into a formal Markov decision process (MDP), implementing an executable environment, and training a policy agent. Automating this process is challenging due to modeling errors, fragile code, and misaligned objectives, which often impede policy training. We introduce an agentic large language model (LLM)-based framework for automated MDP modeling and policy generation (A-LAMP), that automatically translates free-form natural language task descriptions into an MDP formulation and trained policy. The framework decomposes modeling, coding, and training into verifiable stages, ensuring semantic alignment throughout the pipeline. Across both classic control and custom RL domains, A-LAMP consistently achieves higher policy generation capability than a single state-of-the-art LLM model. Notably, even its lightweight variant, which is built on smaller language models, approaches the performance of
Reinforcement learning (RL) has emerged as a foundational paradigm for sequential decision making in dynamic and uncertain environments [Kaelbling et al., 1996, Bertsekas, 2008]. It enables agents to acquire a good policy to achieve a given goal through trial-and-error interactions with their environments, guided by appropriate reward signals [Watkins and Dayan, 1992, Sutton et al., 1999, Konda and Tsitsiklis, 1999]. Modern deep RL algorithms have shown impressive performance in various domains such as robotics, autonomous control, and strategic gameplay [Vinyals et al., 2019, Silver et al., 2018, Berner et al., 2019].
To make RL effective in real-world conditions, it is essential to establish a well-posed Markov decision process (MDP) that specifies what to optimize and how actions influence outcomes as a formal bridge between informal task descriptions and an executable environment with a training loop that generates a deployable policy. In practice, however, transitioning from such an MDP specification to a capable policy requires maintaining intact the semantics throughout training the policy using the environment: the information encoded in the state must appear in the observations, the implemented choices of the agent must match the allowable actions, the environment must realize the assumed dynamics and reward, and the training loop must optimize precisely that objective under the given constraints. Only when this end-to-end alignment is preserved and made verifiable through evaluation and traceable logs, the resulting policy can reliably reflect the target task. However, in real-world deployments for various tasks, this alignment is fragile and may pose persistent challenges.
One of the major challenges is deriving a precise MDP from real-world tasks. To this end, policy designers must decide how to abstract the target task into a mathematical form by defining informative states, identifying feasible actions, and translating the task’s objectives into reward signals that actually drive policy learning. Another challenge is implementing an environment in which to train a policy that reflects the MDP formulation of the task. This process becomes more difficult when these elements are buried in unstructured or domain-specific artifacts, such as simulator configuration files, engineering documentation, or informal natural language specifications. This makes the process manual and expertise-intensive. As a result, constructing an MDP and creating an executable environment are often time-consuming, error-prone, and dependent on human experts, creating a barrier to RL adoption in domains such as network resource scheduling, industrial automation, and supply chain optimization. [Ye et al., 2019, Luong et al., 2019].
Furthermore, this traditional RL process conducted by human experts lacks flexibility when tasks or parameters change since learned policies often cannot be reused directly [Taylor and Stone, 2009, Finn et al., 2017, Rakelly et al., 2019, Rusu et al., 2016]. Even minor modifications, such as switching the task objective from maximizing performance to minimizing energy consumption in the same wireless network, require experts to reformulate the MDP manually and retrain a new policy from scratch. This inflexibility severely limits the scalability and efficiency of RL workflows because even experienced experts must repeatedly translate vague problem semantics into coherent MDP components and reimplement similar structures across tasks with only minor variations.
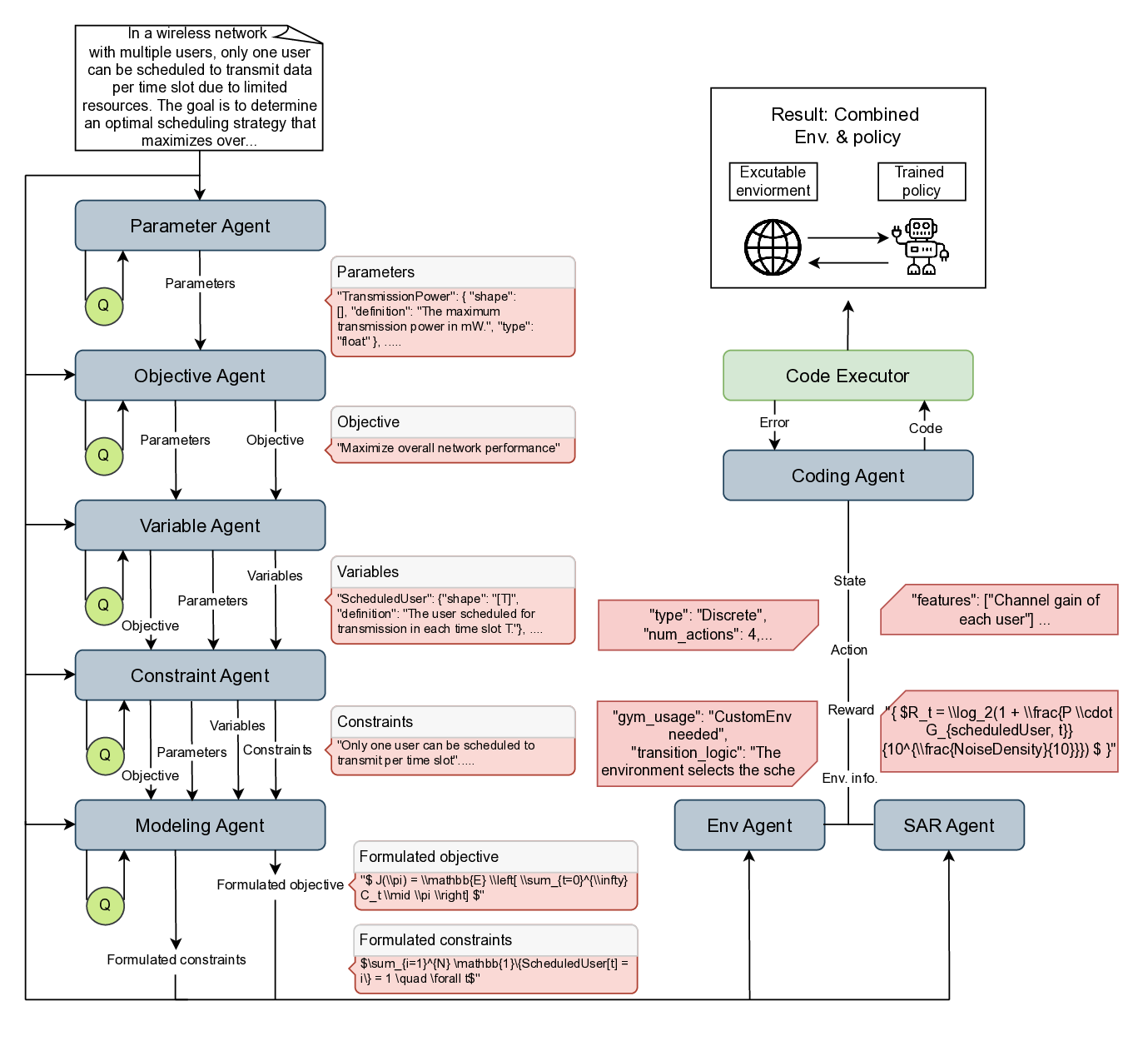
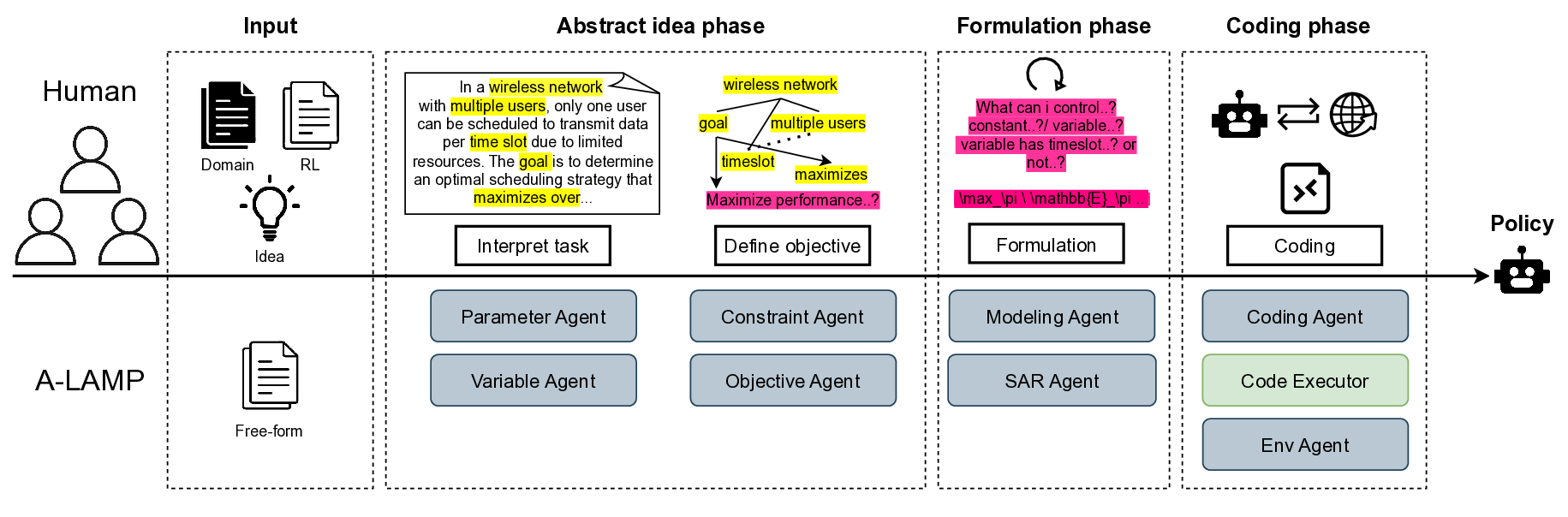
To address these challenges, we introduce an agentic large language model (LLM)-based framework for automated MDP modeling and policy generation (A-LAMP). A-LAMP is a modular multi-agent LLM framework that formally establishes an MDP from a free-form natural language description. It also generates policy training code, including an executable RL environment, which can be used to train policies. A-LAMP reliably processes this end-to-end automation from the natural language description to policy generation while preserving interpretability for human experts by orchestrating specialized agents. As a result, it lowers the barrier to deploying RL in real-world settings. The key contributions of A-LAMP are summarized below:
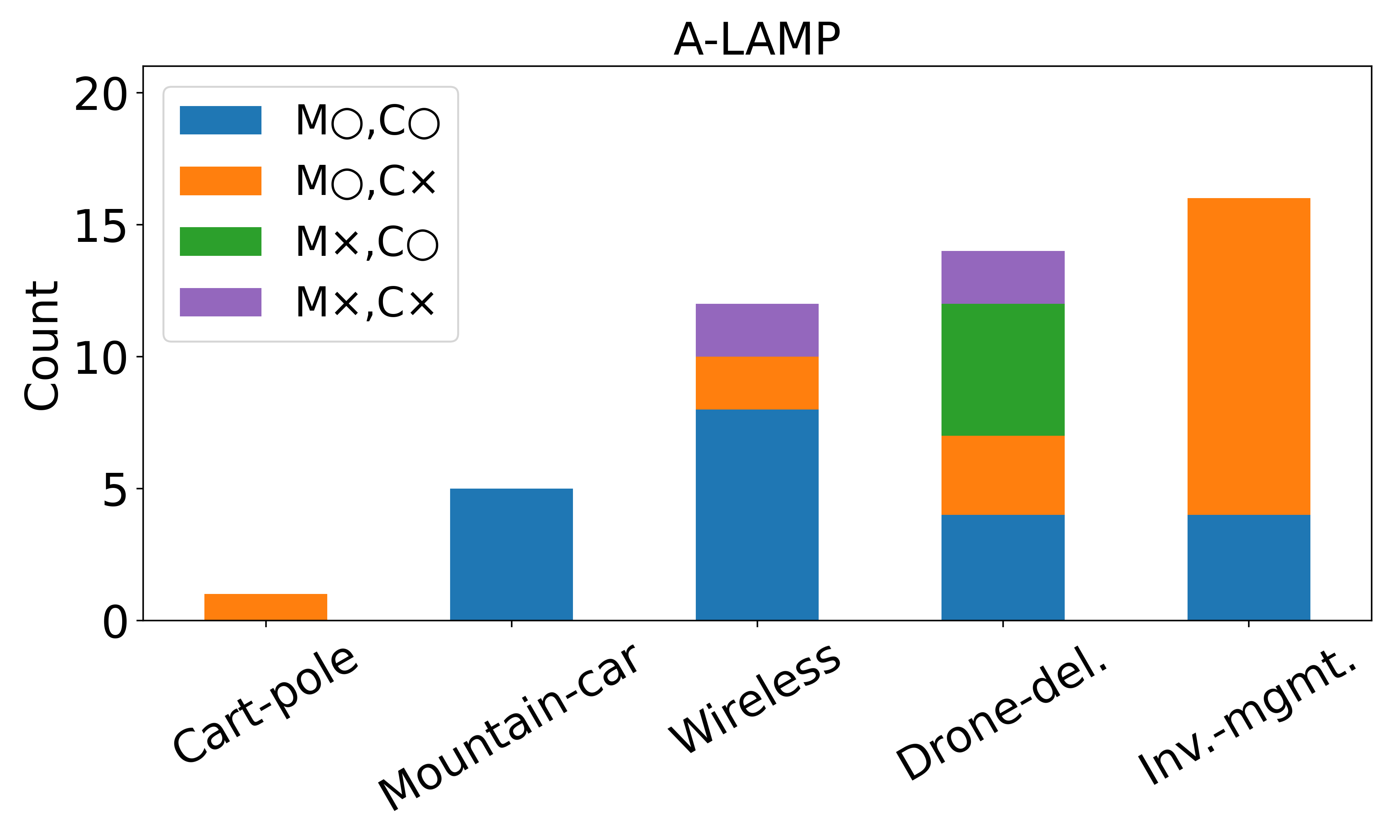
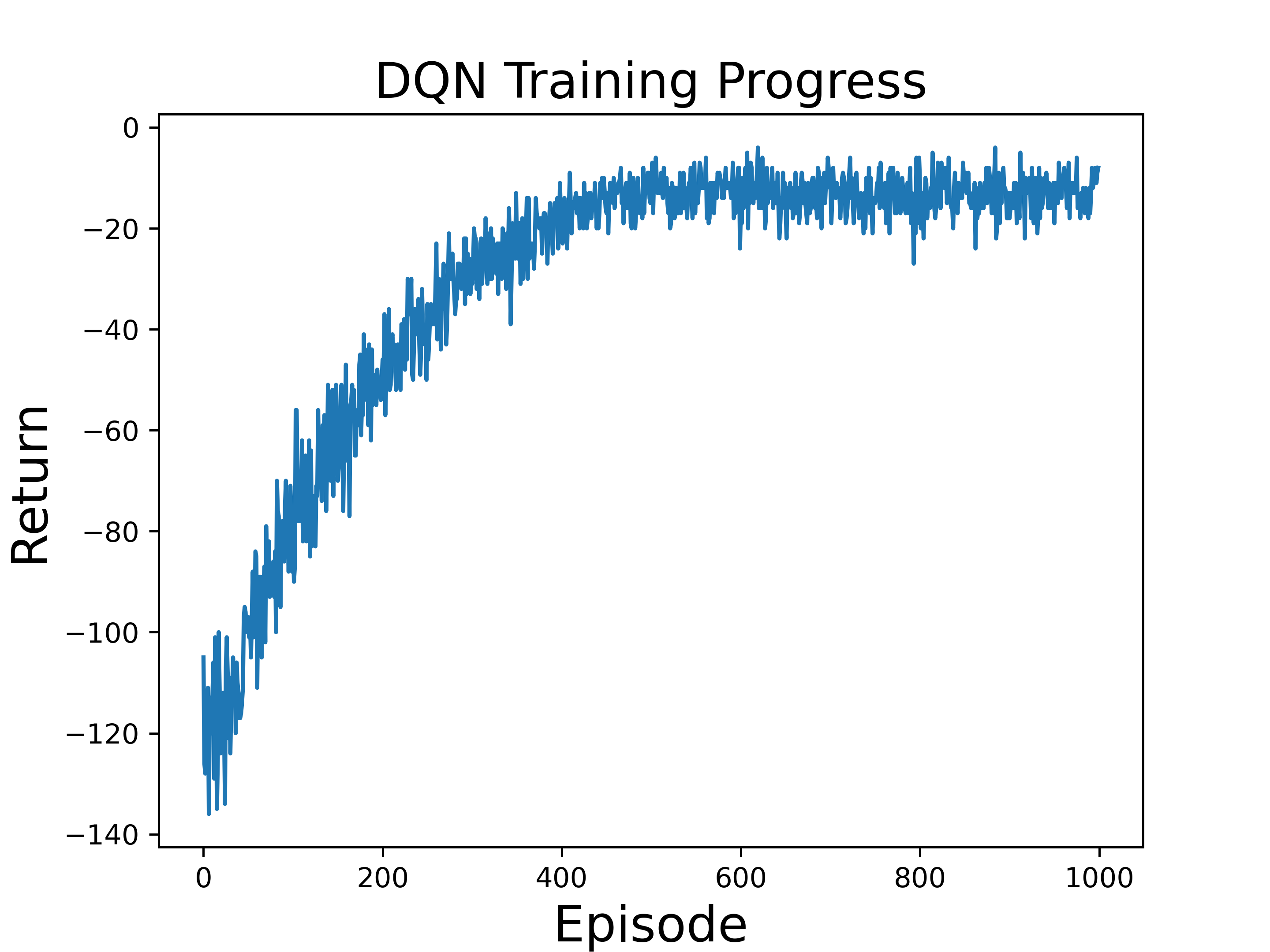
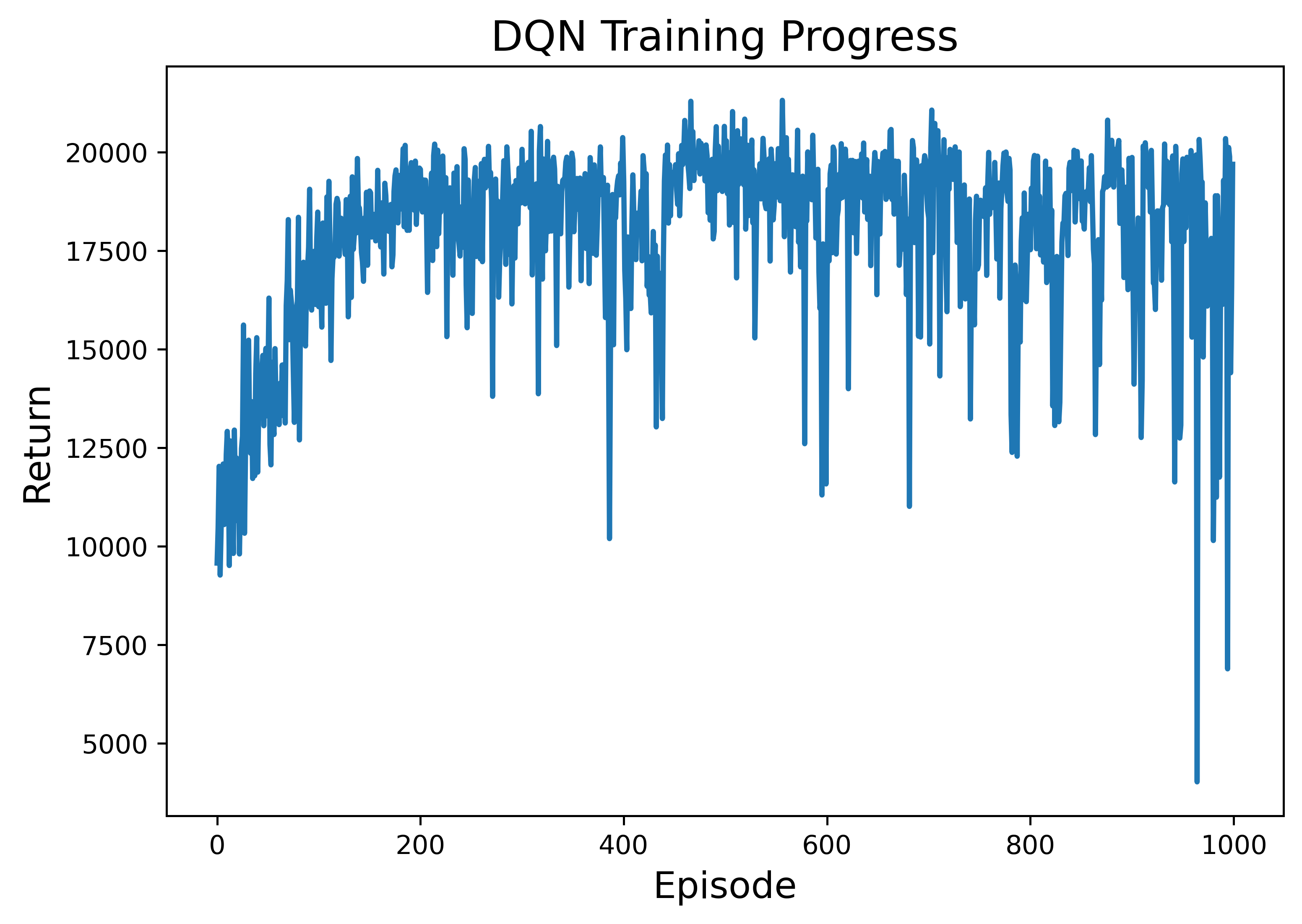
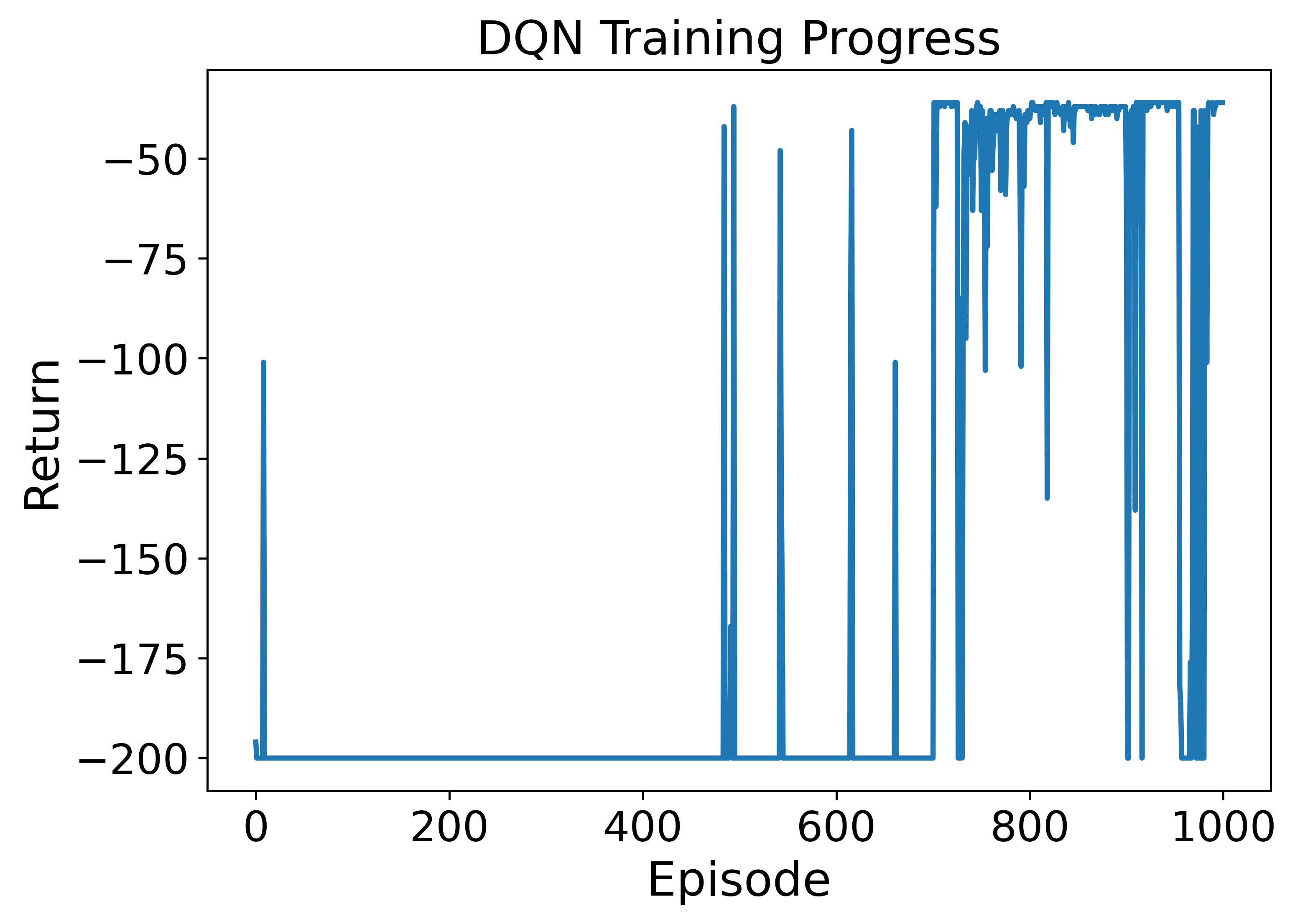
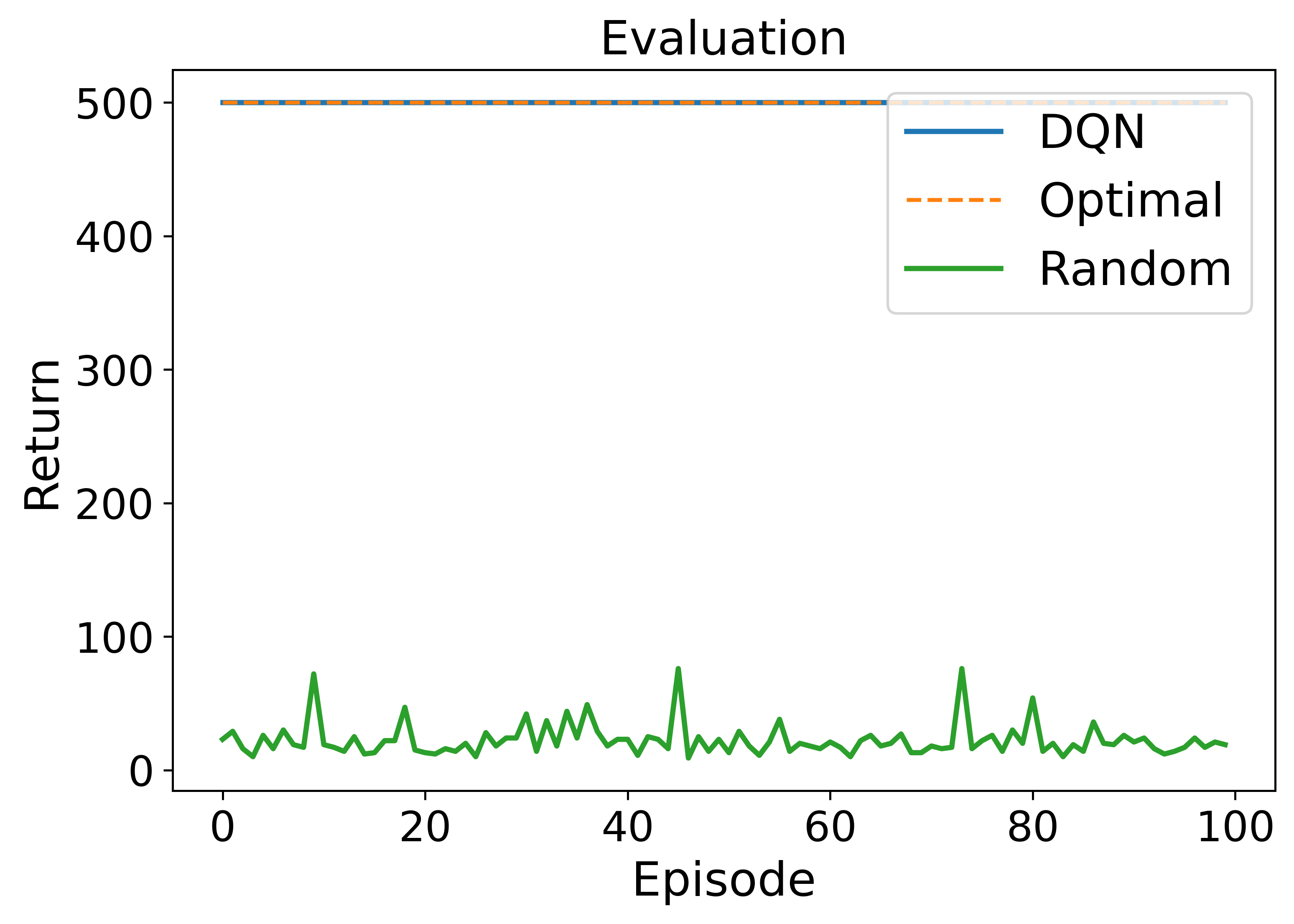
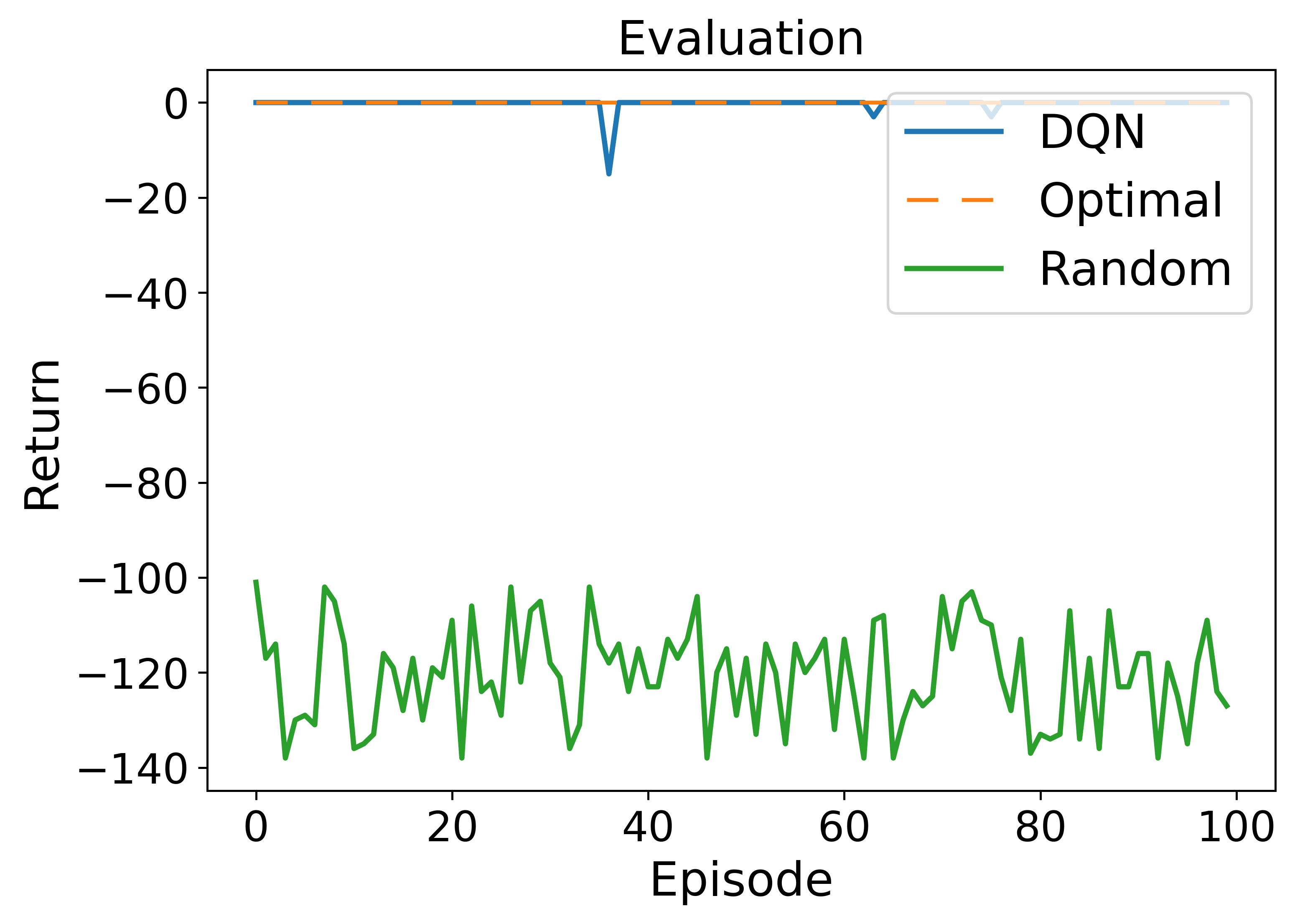
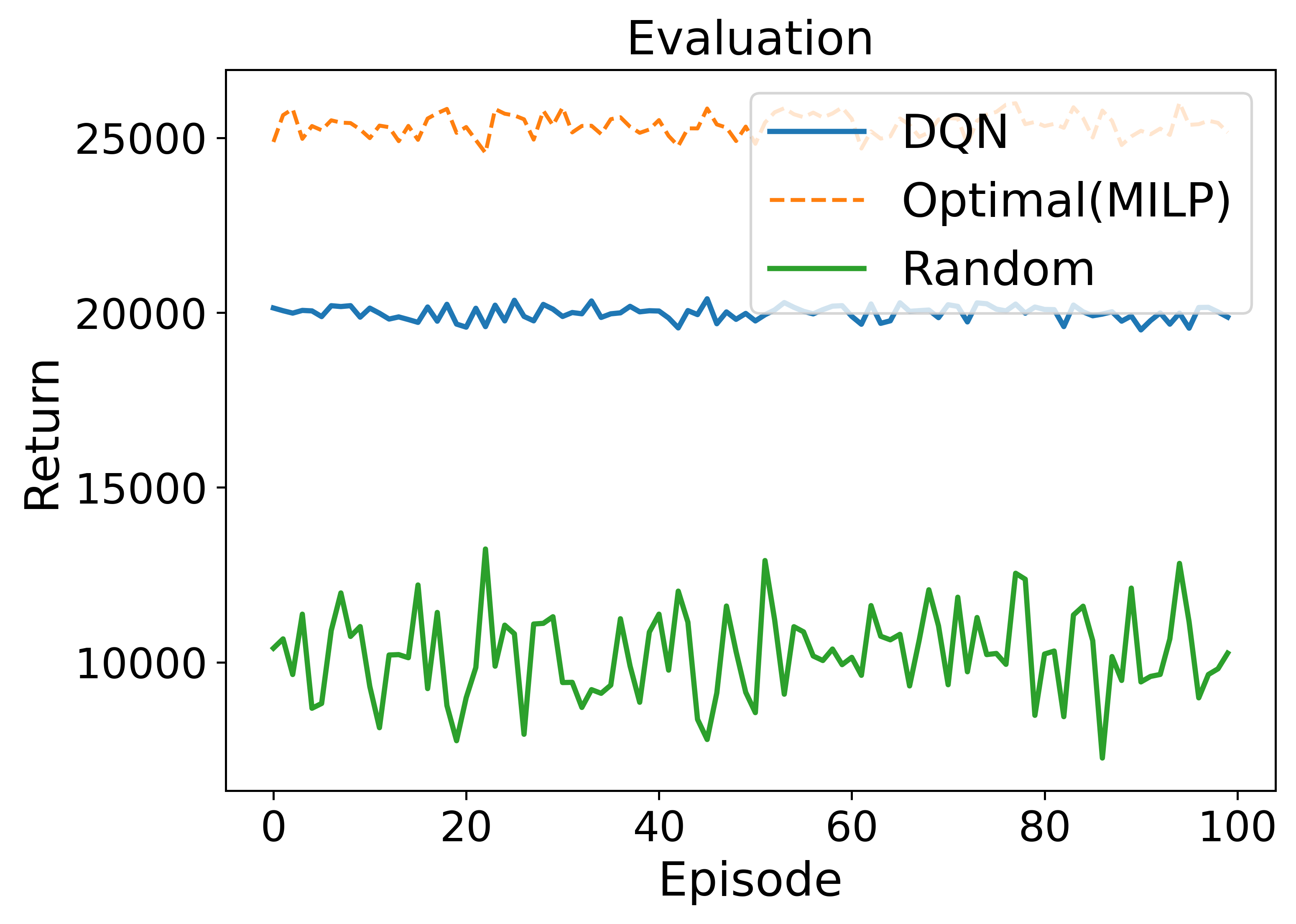
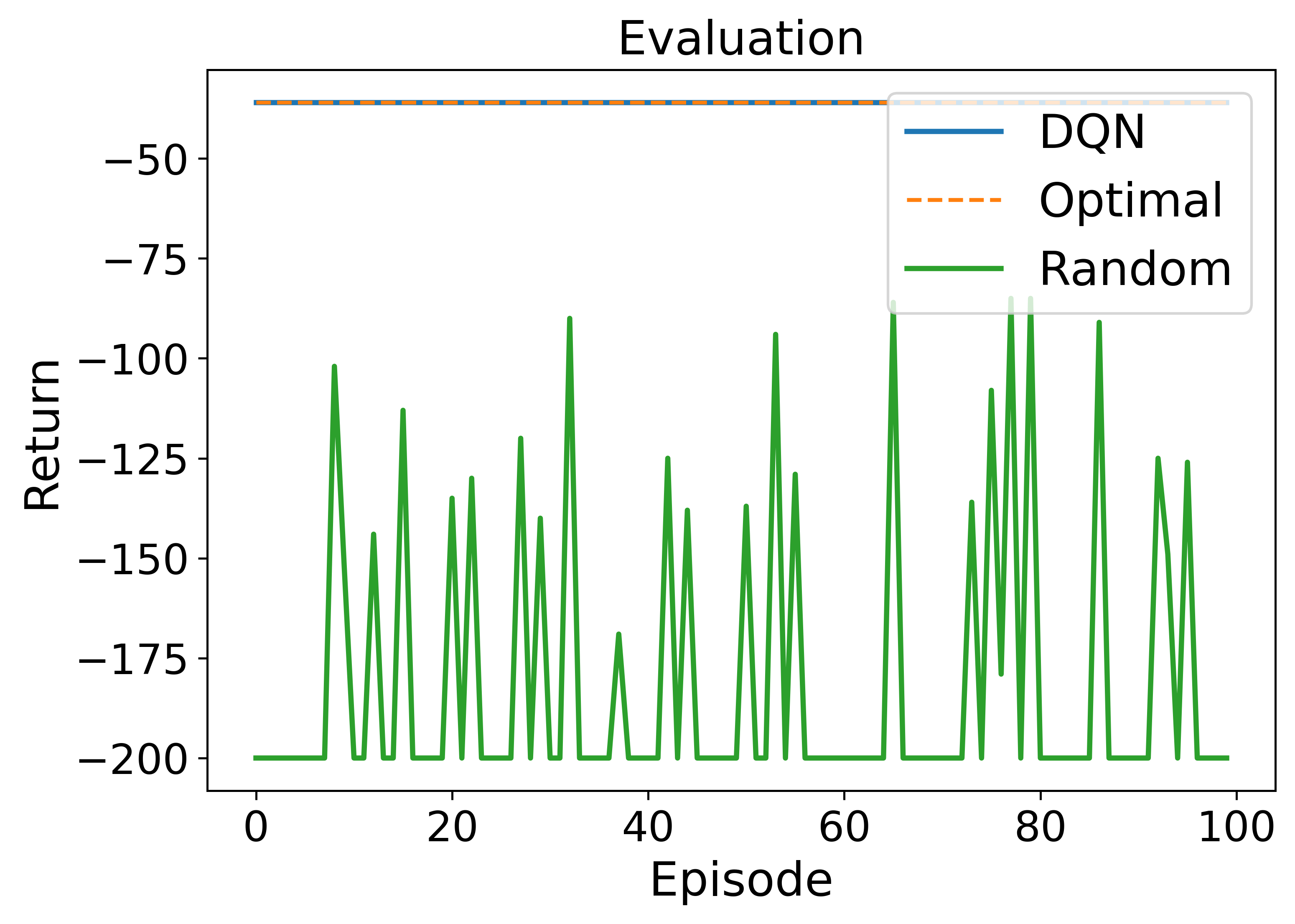
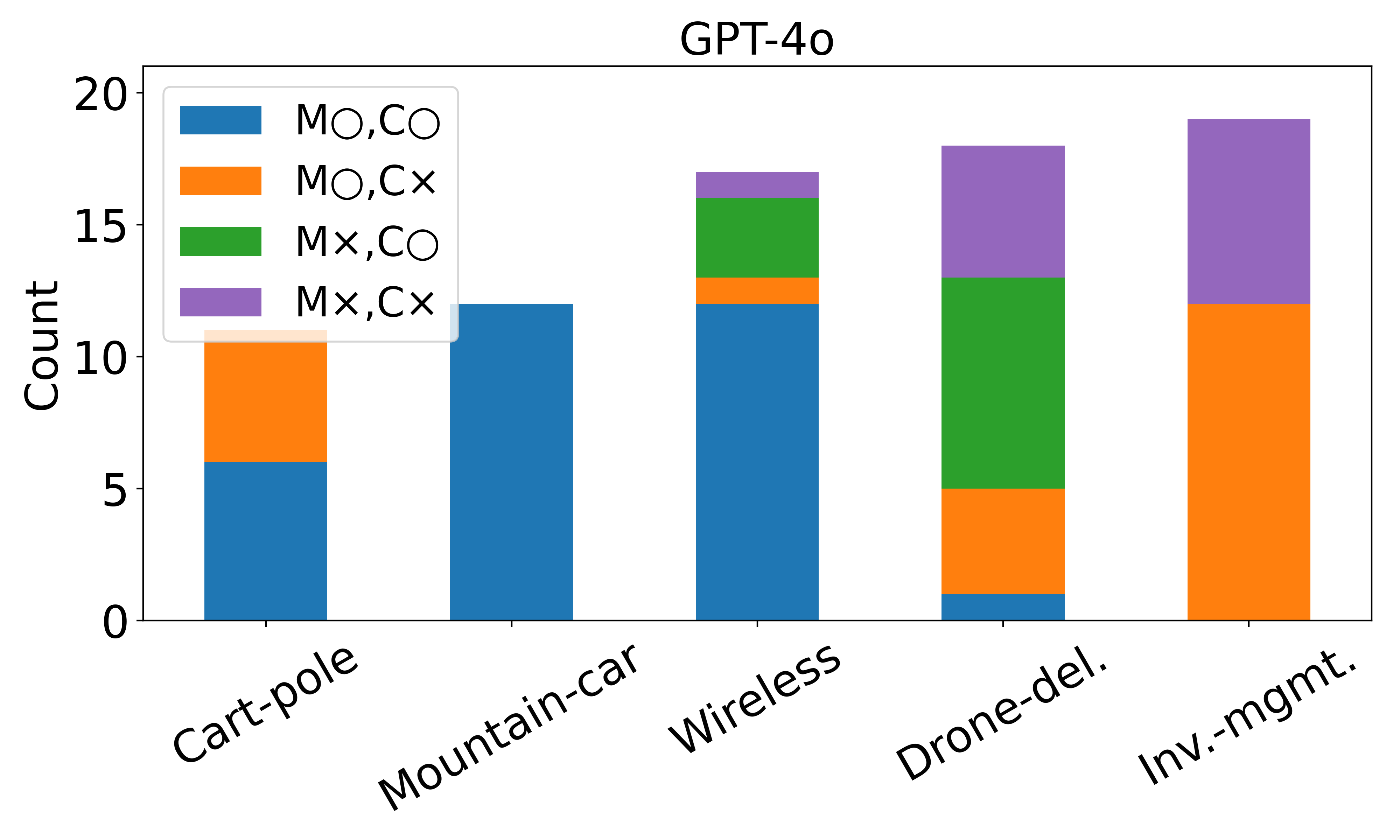
• Enhanced capability in MDP modeling and policy generation: A-LAMP decomposes the MDP formulation and policy generation process into specialized LLM agents, constructing precise mathematical representations and corresponding policy structures. This approach yields more reliable and consistent policies than a single large LLM (e.g., GPT-4o).
• Transparency and interpretability: Each component of the MDP-such as inferred objectives, decision variables, and constraints-is modularized in A-LAMP, producing either a human-readable description or an equation-level formulation. This design allows experts to inspect, validate, and refine the modeling process at any stage.
• Adaptability across tasks and environments: A-LAMP aut
…(Full text truncated)…
This content is AI-processed based on ArXiv data.