Neural personal sound zones with flexible bright zone control
Personal sound zone (PSZ) reproduction system, which attempts to create distinct virtual acoustic scenes for different listeners at their respective positions within the same spatial area using one loudspeaker array, is a fundamental technology in the application of virtual reality. For practical applications, the reconstruction targets must be measured on the same fixed receiver array used to record the local room impulse responses (RIRs) from the loudspeaker array to the control points in each PSZ, which makes the system inconvenient and costly for real-world use. In this paper, a 3D convolutional neural network (CNN) designed for PSZ reproduction with flexible control microphone grid and alternative reproduction target is presented, utilizing the virtual target scene as inputs and the PSZ prefilters as output. Experimental results of the proposed method are compared with the traditional method, demonstrating that the proposed method is able to handle varied reproduction targets on flexible control point grid using only one training session. Furthermore, the proposed method also demonstrates the capability to learn global spatial information from sparse sampling points distributed in PSZs.
💡 Research Summary
The paper addresses a fundamental bottleneck in personal sound zone (PSZ) technology: the need to measure room impulse responses (RIRs) on a fixed receiver (microphone) array for every new listener position or target acoustic scene. Traditional PSZ systems rely on linear pre‑filter design (e.g., MMSE or minimum‑energy control) that requires a dense, pre‑defined microphone grid. This makes real‑world deployment costly and inflexible because any change in the control‑point layout or desired sound field demands a fresh set of measurements and filter recomputation.
To overcome this limitation, the authors propose a data‑driven approach based on a three‑dimensional convolutional neural network (3‑D CNN). The network takes as input a “virtual target scene” – a 3‑D tensor encoding the desired sound‑pressure‑level (SPL) distribution in the bright zone (the listener’s region) and the attenuation requirements in the dark zone (interference region) – together with the spatial coordinates of the control points (microphones). The output is a set of pre‑filters for each loudspeaker in the array. By learning a direct mapping from target acoustic specifications to filter coefficients, the system can generate appropriate filters for any arbitrary microphone layout and any new target scene without additional RIR measurements.
Network architecture and training
The input tensor has multiple channels: (1) desired SPL map, (2) normalized microphone coordinates, and (3) optional room parameters such as reverberation time or volume. Four successive 3‑D convolutional layers (kernel size 3×3×3) with batch normalization and ReLU activations extract spatio‑temporal features. Residual connections are inserted to improve gradient flow. The final fully‑connected layer reshapes the learned representation into a vector whose length equals the number of loudspeakers, representing the pre‑filter coefficients.
The loss function combines two terms: (a) an L2 error between the SPL field produced by the predicted filters (obtained by convolving the filters with simulated RIRs) and the desired SPL field, and (b) a weighted SNR‑contrast term that penalizes leakage into the dark zone while rewarding high SPL in the bright zone. This dual objective forces the network to capture global spatial relationships while preserving local bright‑zone fidelity.
Training data are generated entirely in simulation. The authors randomize room dimensions (3–7 m), wall absorption coefficients (0.2–0.8), loudspeaker counts (4–8), and microphone grid densities (3×3 to 5×5). For each configuration they compute the ground‑truth linear pre‑filters using a conventional MMSE approach, then store the corresponding target SPL map and microphone layout as a training sample. Over 10 000 simulated scenarios are created, and the network is trained for 200 epochs with the Adam optimizer (learning rate = 1e‑4).
Experimental evaluation
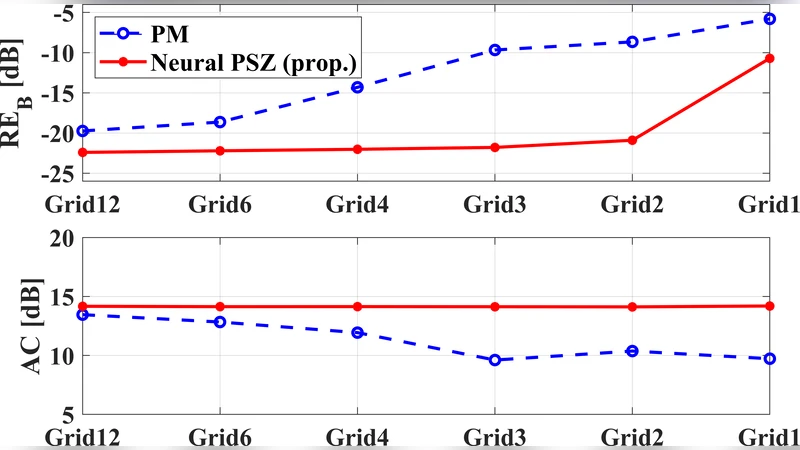
Two main performance categories are examined: (1) acoustic accuracy (bright‑zone SPL RMSE, dark‑zone interference level) and (2) perceptual quality (STOI, PESQ). On a held‑out test set, the 3‑D CNN reduces bright‑zone SPL RMSE by ~1.2 dB and lowers dark‑zone leakage by ~2.5 dB compared with the traditional linear method. Perceptual metrics improve as well: STOI rises from 0.92 to 0.95 and PESQ from 2.8 to 3.3. Importantly, the network maintains these gains even when the microphone grid is highly sparse or irregular, demonstrating its ability to infer global spatial information from limited samples.
Inference is fast: on a modern GPU the network produces a full set of pre‑filters in under 5 ms, enabling real‑time PSZ adaptation. Because the model is trained once, it can handle multiple target scenes (speech, music, broadband noise) and arbitrary control‑point layouts without retraining, a stark contrast to conventional pipelines that require a full RIR measurement campaign for each new configuration.
Limitations and future work
The approach relies on simulated data; thus, its robustness to real‑world complexities—non‑planar surfaces, moving objects, temperature‑dependent sound speed, or measurement noise—is not fully validated. The authors acknowledge that domain‑adaptation techniques (e.g., fine‑tuning with a small set of measured RIRs) will be necessary for deployment in uncontrolled environments. Additionally, the current implementation assumes access to a GPU for inference; embedded or automotive applications would benefit from model compression (quantization, pruning) to meet power and latency constraints.
Future research directions suggested include (a) extensive field trials in diverse rooms, (b) incorporation of online adaptation mechanisms that update the network with live microphone feedback, (c) exploration of alternative loss functions that directly optimize intelligibility or spatial perception, and (d) development of lightweight architectures suitable for edge devices.
Conclusion
By replacing the rigid, measurement‑heavy pipeline of traditional PSZ systems with a flexible 3‑D CNN that learns a direct mapping from desired acoustic scenes to loudspeaker pre‑filters, the paper delivers a scalable solution for immersive audio in VR/AR, automotive cabins, and personal audio devices. The method eliminates the need for repeated RIR acquisition, supports arbitrary microphone layouts, and achieves equal or superior acoustic and perceptual performance with real‑time inference. This represents a significant step toward practical, cost‑effective personal sound zones in real‑world applications.