Multi-dimensional Preference Alignment by Conditioning Reward Itself
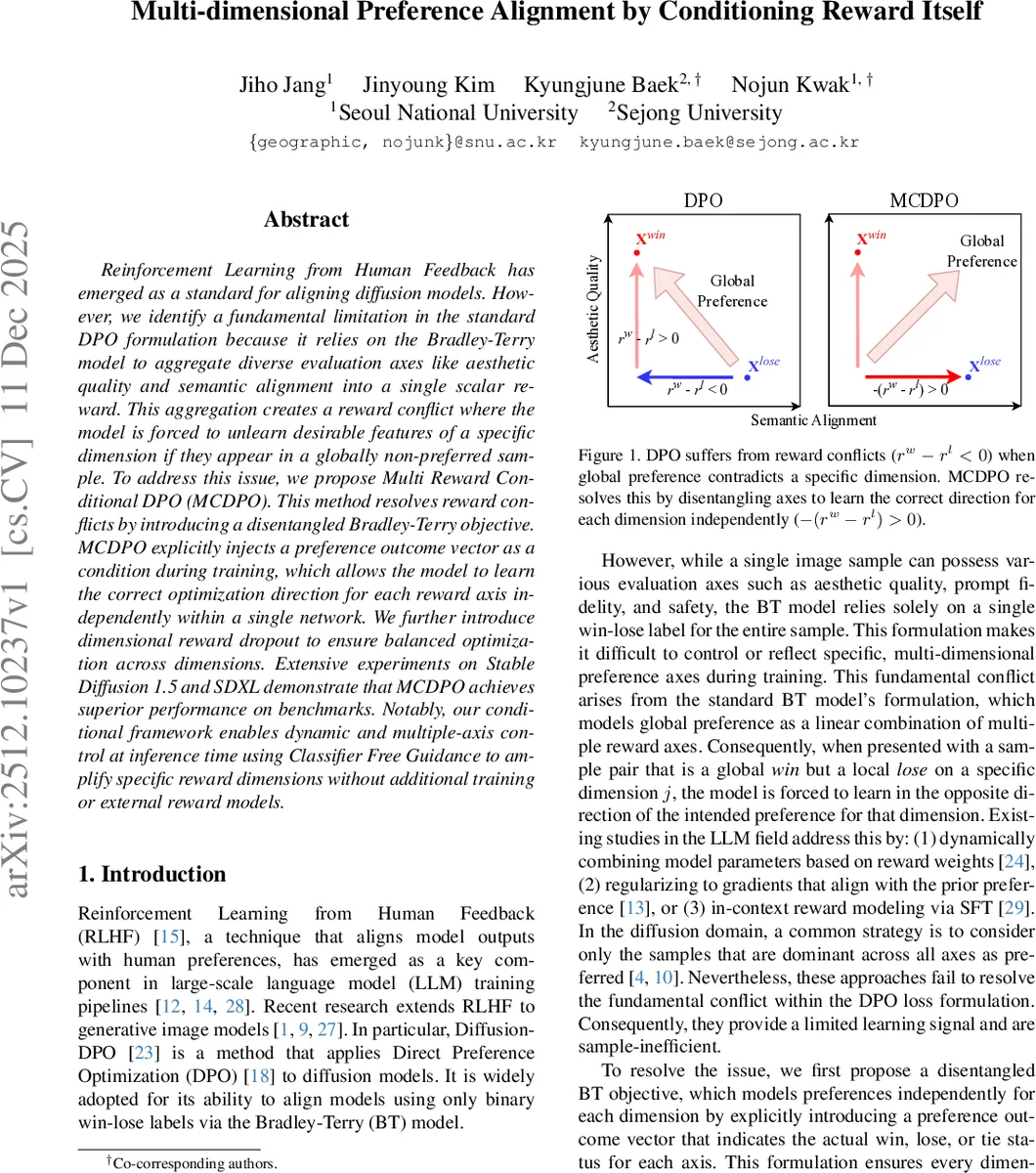
Reinforcement Learning from Human Feedback has emerged as a standard for aligning diffusion models. However, we identify a fundamental limitation in the standard DPO formulation because it relies on the Bradley-Terry model to aggregate diverse evaluation axes like aesthetic quality and semantic alignment into a single scalar reward. This aggregation creates a reward conflict where the model is forced to unlearn desirable features of a specific dimension if they appear in a globally non-preferred sample. To address this issue, we propose Multi Reward Conditional DPO (MCDPO). This method resolves reward conflicts by introducing a disentangled Bradley-Terry objective. MCDPO explicitly injects a preference outcome vector as a condition during training, which allows the model to learn the correct optimization direction for each reward axis independently within a single network. We further introduce dimensional reward dropout to ensure balanced optimization across dimensions. Extensive experiments on Stable Diffusion 1.5 and SDXL demonstrate that MCDPO achieves superior performance on benchmarks. Notably, our conditional framework enables dynamic and multiple-axis control at inference time using Classifier Free Guidance to amplify specific reward dimensions without additional training or external reward models.
💡 Research Summary
The paper addresses a critical flaw in the standard Direct Preference Optimization (DPO) framework when applied to diffusion models that are evaluated along multiple dimensions such as aesthetic quality, semantic alignment, and safety. Traditional DPO relies on the Bradley‑Terry (BT) model to collapse all these axes into a single scalar reward r(x,c)=∑_i w_i r_i(x,c). Consequently, a pair of images where the “globally preferred” sample is actually worse on a particular axis creates a “reward conflict”: the DPO loss pushes the model to improve the global win, which inadvertently degrades the under‑performing axis because its gradient points in the opposite direction.
The authors first formalize this conflict mathematically and propose a disentangled BT objective. They introduce a preference outcome vector γ∈ℝ^D, where each component γ_i∈{+1,0,−1} encodes win, tie, or loss for the i‑th axis. The modified preference probability becomes
p⊥_BT(x_w > x_l | c,γ)=σ(∑_i w_i γ_i (r_i(x_w)−r_i(x_l))).
If an axis disagrees with the global label, γ_i flips the sign of its contribution, guaranteeing that every dimension is optimized in the correct direction.
Training D separate models—one per axis—would be computationally prohibitive. To avoid this, the paper presents Multi‑Reward Conditional DPO (MCDPO), a single conditional diffusion model p(x | c,γ) that implicitly learns D reward functions. They define a conditional implicit reward
r_θ(x,c,γ)=β log(p(x | c,γ)/p_ref(x | c))
and construct a loss that leverages both orientations of each pair:
L_MC = −E log σ
Comments & Academic Discussion
Loading comments...
Leave a Comment