📝 Original Info
- Title: Beyond Pixels: A Training-Free, Text-to-Text Framework for Remote Sensing Image Retrieval
- ArXiv ID: 2512.10596
- Date: 2025-12-11
- Authors: Researchers from original ArXiv paper
📝 Abstract
Semantic retrieval of remote sensing (RS) images is a critical task fundamentally challenged by the "semantic gap", the discrepancy between a model's low-level visual features and high-level human concepts. While large Vision-Language Models (VLMs) offer a promising path to bridge this gap, existing methods often rely on costly, domain-specific training, and there is a lack of benchmarks to evaluate the practical utility of VLM-generated text in a zero-shot retrieval context. To address this research gap, we introduce the Remote Sensing Rich Text (RSRT) dataset, a new benchmark featuring multiple structured captions per image. Based on this dataset, we propose a fully training-free, text-only retrieval reference called TRSLLaVA. Our methodology reformulates cross-modal retrieval as a text-to-text (T2T) matching problem, leveraging rich text descriptions as queries against a database of VLM-generated captions within a unified textual embedding space. This approach completely bypasses model training or fine-tuning. Experiments on the RSITMD and RSICD benchmarks show our training-free method is highly competitive with stateof-the-art supervised models. For instance, on RSITMD, our method achieves a mean Recall of 42.62%, nearly doubling the 23.86% of the standard zero-shot CLIP baseline and surpassing several top supervised models. This validates that high-quality semantic representation through structured text provides a powerful and costeffective paradigm for remote sensing image retrieval.
💡 Deep Analysis
Deep Dive into Beyond Pixels: A Training-Free, Text-to-Text Framework for Remote Sensing Image Retrieval.
Semantic retrieval of remote sensing (RS) images is a critical task fundamentally challenged by the “semantic gap”, the discrepancy between a model’s low-level visual features and high-level human concepts. While large Vision-Language Models (VLMs) offer a promising path to bridge this gap, existing methods often rely on costly, domain-specific training, and there is a lack of benchmarks to evaluate the practical utility of VLM-generated text in a zero-shot retrieval context. To address this research gap, we introduce the Remote Sensing Rich Text (RSRT) dataset, a new benchmark featuring multiple structured captions per image. Based on this dataset, we propose a fully training-free, text-only retrieval reference called TRSLLaVA. Our methodology reformulates cross-modal retrieval as a text-to-text (T2T) matching problem, leveraging rich text descriptions as queries against a database of VLM-generated captions within a unified textual embedding space. This approach completely bypasses mo
📄 Full Content
Beyond Pixels: A Training-Free, Text-to-Text
Framework for Remote Sensing Image Retrieval
Jinghao Xiao
School of Computer Science
Faculty of Engineering and Information Technology
University of Technology Sydney
Sydney, Australia
Jinghao.Xiao@student.uts.edu.au
Yiheng Guo
School of Computer Science
Faculty of Engineering and Information Technology
University of Technology Sydney
Sydney, Australia
Yiheng.Guo@student.uts.edu.au
Xing Zi
School of Computer Science
Faculty of Engineering and Information Technology
University of Technology Sydney
Sydney, Australia
Xing.Zi-1@uts.edu.au
Karthick Thiyagarajan
Smart Sensing and Robotics Laboratory (SensR Lab)
Centre for Advanced Manufacturing Technology
Western Sydney University
Sydney, Australia
K.Thiyagarajan@westernsydney.edu.au
Catarina Moreira
The Data Science Institute
Faculty of Engineering and Information Technology
University of Technology Sydney
Sydney, Australia
Catarina.PintoMoreira@uts.edu.au
Mukesh Prasad
School of Computer Science
Faculty of Engineering and Information Technology
University of Technology Sydney
Sydney, Australia
Mukesh.Prasad@uts.edu.au
Abstract— Semantic retrieval of remote sensing (RS)
images is a critical task fundamentally challenged by
the “semantic gap”, the discrepancy between a model’s
low-level visual features and high-level human concepts.
While large Vision-Language Models (VLMs) offer a
promising path to bridge this gap, existing methods often
rely on costly, domain-specific training, and there is
a lack of benchmarks to evaluate the practical utility
of VLM-generated text in a zero-shot retrieval context.
To address this research gap, we introduce the Remote
Sensing Rich Text (RSRT) dataset, a new benchmark
featuring multiple structured captions per image. Based
on this dataset, we propose a fully training-free, text-only
retrieval reference called TRSLLaVA. Our methodology
reformulates cross-modal retrieval as a text-to-text (T2T)
matching problem, leveraging rich text descriptions as
queries against a database of VLM-generated captions
within a unified textual embedding space. This approach
completely bypasses model training or fine-tuning. Ex-
periments on the RSITMD and RSICD benchmarks show
our training-free method is highly competitive with state-
of-the-art supervised models. For instance, on RSITMD,
our method achieves a mean Recall of 42.62%, nearly
doubling the 23.86% of the standard zero-shot CLIP
baseline and surpassing several top supervised models.
This validates that high-quality semantic representation
through structured text provides a powerful and cost-
effective paradigm for remote sensing image retrieval.
Keywords— Remote sensing image retrieval, rich-text
captions, vision–language models, cross-modal alignment,
structured semantic representation, retrieval evaluation
I. Introduction
With the rapid advancements in satellite technologies and
sensor capabilities, Earth observation has entered an era of
unprecedented data explosion [1]–[3]. Remote sensing image
archives are expanding at an extraordinary pace, presenting
tremendous opportunities for applications such as military
reconnaissance, environmental monitoring, and urban plan-
ning [1], [2]. However, this explosive growth also poses
significant challenges in data management, particularly in
information discovery. The ever-growing repositories create
an urgent need for efficient and accurate retrieval of relevant
content. To address this, Remote Sensing Image Retrieval
(RSIR) has emerged, with its core task being to search
and return semantically relevant images from large-scale
databases [1], [4].
Initially, RSIR systems relied on Content-Based Image
Retrieval (CBIR), which matched images based on low-level
visual features like color, texture, and shape [1], [5], [6].
These methods were fundamentally limited by the “semantic
gap” which is the discrepancy between pixel level appearance
arXiv:2512.10596v1 [cs.CV] 11 Dec 2025
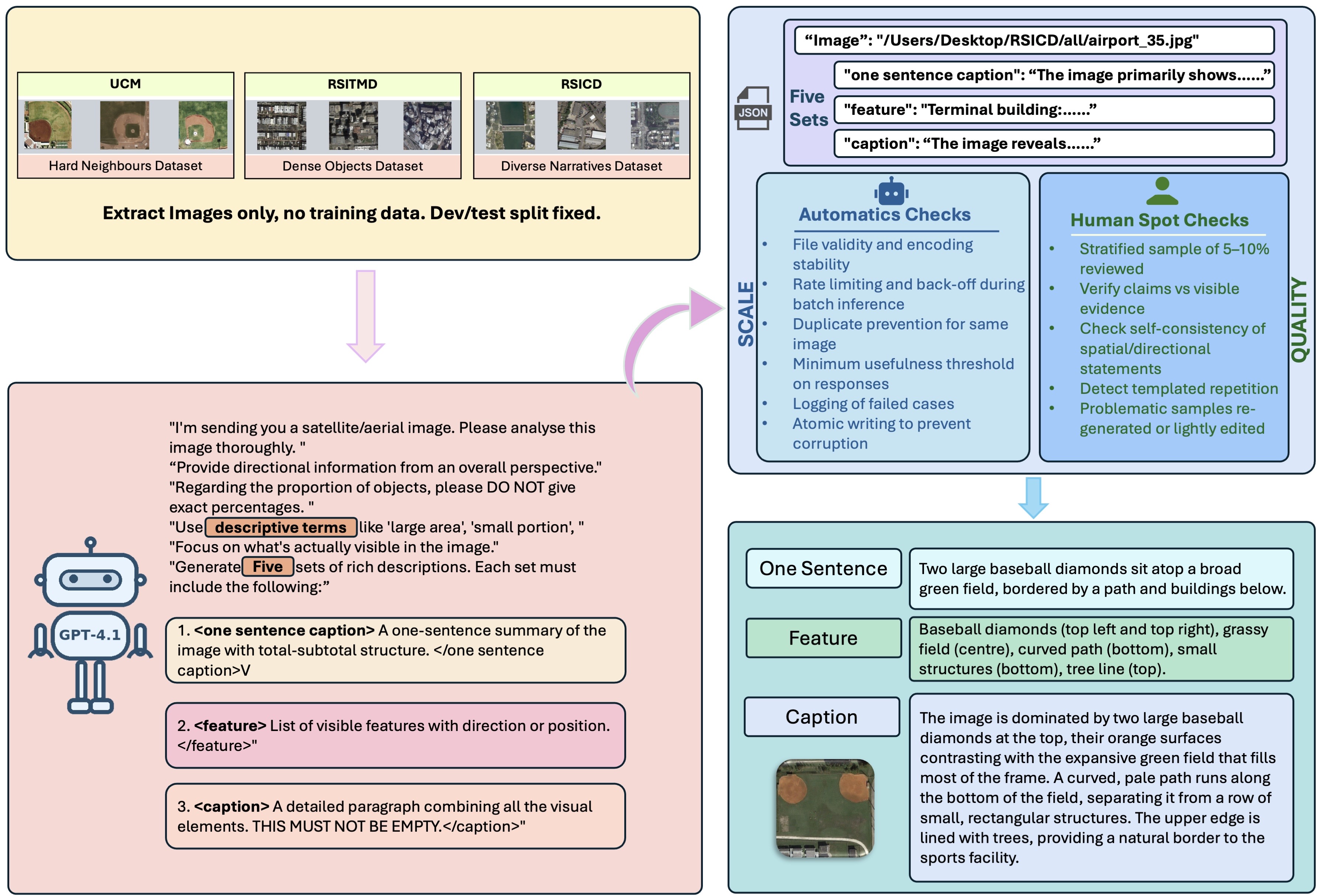
Fig. 1. Overview of the RSRT dataset construction pipeline.
and high level human concepts [1]. To bridge this gap, modern
approaches have shifted towards Vision-Language Models
(VLMs) like CLIP, which learn to map images and text
into a shared semantic space, enabling powerful cross modal
retrieval [2], [7]. Despite their success in general domains,
directly applying these VLMs to remote sensing reveals a
distinct set of challenges rooted in the data’s unique nature [2],
[8], [9].
Meanwhile, the community has developed image–text
benchmarks in RS to facilitate cross-modal research, such as
RSICD [10], RSITMD [11], and UCM [12], which are widely
used for remote sensing captioning and retrieval. Recent
RS-tailored VLM efforts (e.g., RemoteCLIP) further adapt
contrastive language–image pretraining to satellite imagery
and inspire training paradigms for zero-shot or low-shot trans-
fer [8], [9], [13]. However, this dominant paradigm of fine-
tuning large models on domain-specific datasets introduces
its own fundamental limitations
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.