📝 Original Info
- Title: PACIFIC: a framework for generating benchmarks to check Precise Automatically Checked Instruction Following In Code
- ArXiv ID: 2512.10713
- Date: 2025-12-11
- Authors: : Itay Dreyfuss, Antonio Abu Nassar, Samuel Ackerman, Axel Ben David, Eitan Farchi, Rami Katan, Orna Raz, Marcel Zalmanovici
📝 Abstract
Large Language Model (LLM)-based code assistants have emerged as a powerful application of generative AI, demonstrating impressive capabilities in code generation and comprehension. A key requirement for these systems is their ability to accurately follow user instructions. We present Precise Automatically Checked Instruction Following In Code (PACIFIC), a novel framework designed to automatically generate benchmarks that rigorously assess sequential instruction-following and code dry-running capabilities in LLMs, while allowing control over benchmark difficulty. PACIFIC produces benchmark variants with clearly defined expected outputs, enabling straightforward and reliable evaluation through simple output comparisons. In contrast to existing approaches that often rely on tool usage or agentic behavior, our work isolates and evaluates the LLM's intrinsic ability to reason through code behavior step-by-step without execution (dry running) and to follow instructions. Furthermore, our framework mitigates training data contamination by facilitating effortless generation of novel benchmark variations. We validate our framework by generating a suite of benchmarks spanning a range of difficulty levels and evaluating multiple state-of-the-art LLMs. Our results demonstrate that PACIFIC can produce increasingly challenging benchmarks that effectively differentiate instruction-following and dry running capabilities, even among advanced models. Overall, our framework offers a scalable, contamination-resilient methodology for assessing core competencies of LLMs in code-related tasks.
💡 Deep Analysis
Deep Dive into PACIFIC: a framework for generating benchmarks to check Precise Automatically Checked Instruction Following In Code.
Large Language Model (LLM)-based code assistants have emerged as a powerful application of generative AI, demonstrating impressive capabilities in code generation and comprehension. A key requirement for these systems is their ability to accurately follow user instructions. We present Precise Automatically Checked Instruction Following In Code (PACIFIC), a novel framework designed to automatically generate benchmarks that rigorously assess sequential instruction-following and code dry-running capabilities in LLMs, while allowing control over benchmark difficulty. PACIFIC produces benchmark variants with clearly defined expected outputs, enabling straightforward and reliable evaluation through simple output comparisons. In contrast to existing approaches that often rely on tool usage or agentic behavior, our work isolates and evaluates the LLM’s intrinsic ability to reason through code behavior step-by-step without execution (dry running) and to follow instructions. Furthermore, our fra
📄 Full Content
PACIFIC: a framework for generating benchmarks to check
Precise Automatically Checked Instruction Following In Code
Itay Dreyfuss
Antonio Abu Nassar
Samuel Ackerman
Axel Ben David
Eitan Farchi
Rami Katan
Orna Raz
Marcel Zalmanovici
IBM Research
Haifa, Israel
{Itay.Dreyfuss,Antonio.Abu.Nassar,Samuel.Ackerman,Axel.Bendavid}@ibm.com
{Rami.Katan,farchi,ornar,marcel}@il.ibm.com
Abstract
Large Language Model (LLM)-based code assistants have emerged
as a powerful application of generative AI, demonstrating impres-
sive capabilities in code generation and comprehension. A key
requirement for these systems is their ability to accurately follow
user instructions. We present Precise Automatically Checked In-
struction Following In Code (PACIFIC), a novel framework designed
to automatically generate benchmarks that rigorously assess se-
quential instruction-following and code dry-running capabilities
in LLMs, while allowing control over benchmark difficulty. PA-
CIFIC produces benchmark variants with clearly defined expected
outputs, enabling straightforward and reliable evaluation through
simple output comparisons. In contrast to existing approaches that
often rely on tool usage or agentic behavior, our work isolates
and evaluates the LLM’s intrinsic ability to reason through code
behavior step-by-step without execution (dry running) and to fol-
low instructions. Furthermore, our framework mitigates training
data contamination by facilitating effortless generation of novel
benchmark variations. We validate our framework by generating
a suite of benchmarks spanning a range of difficulty levels and
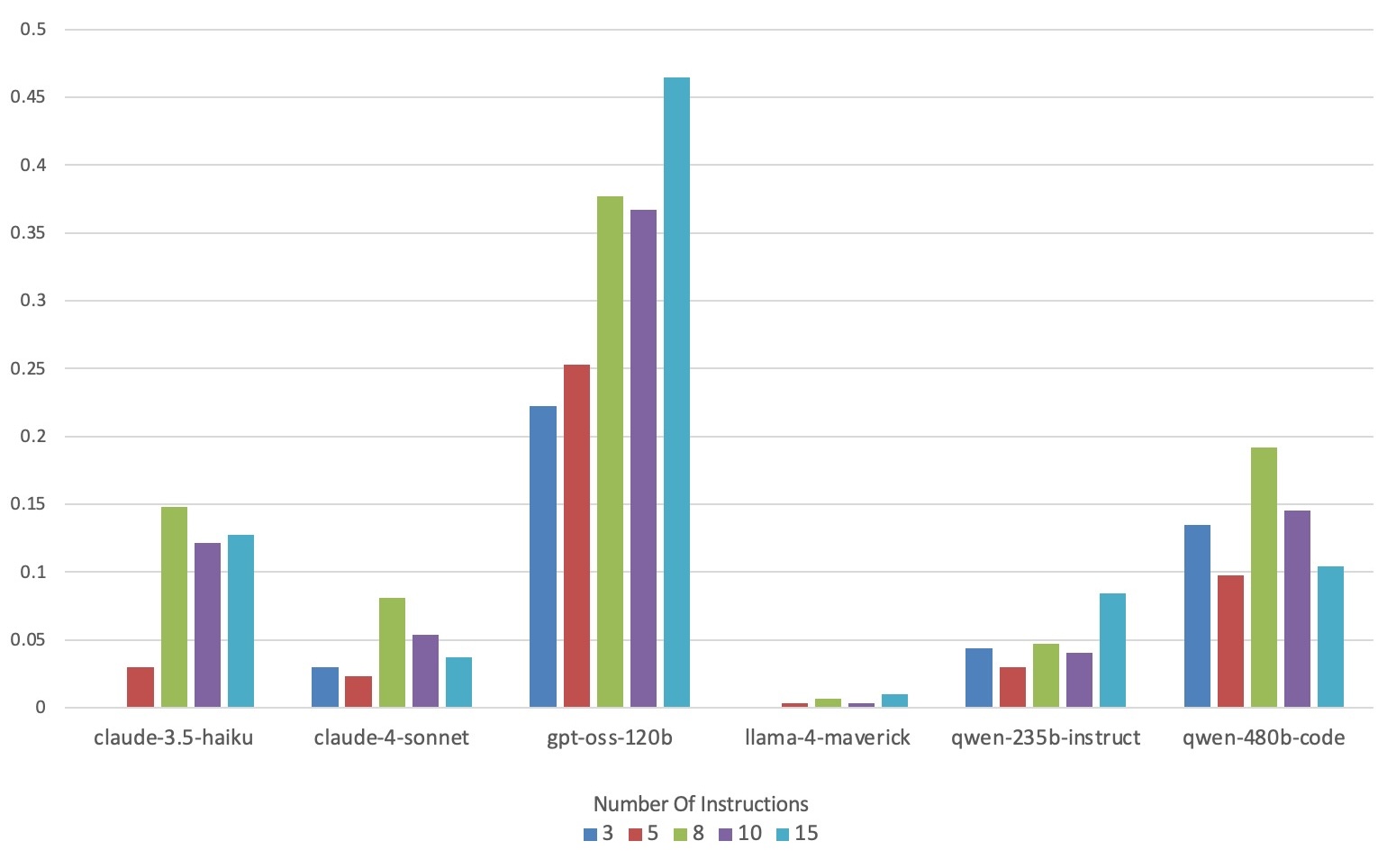
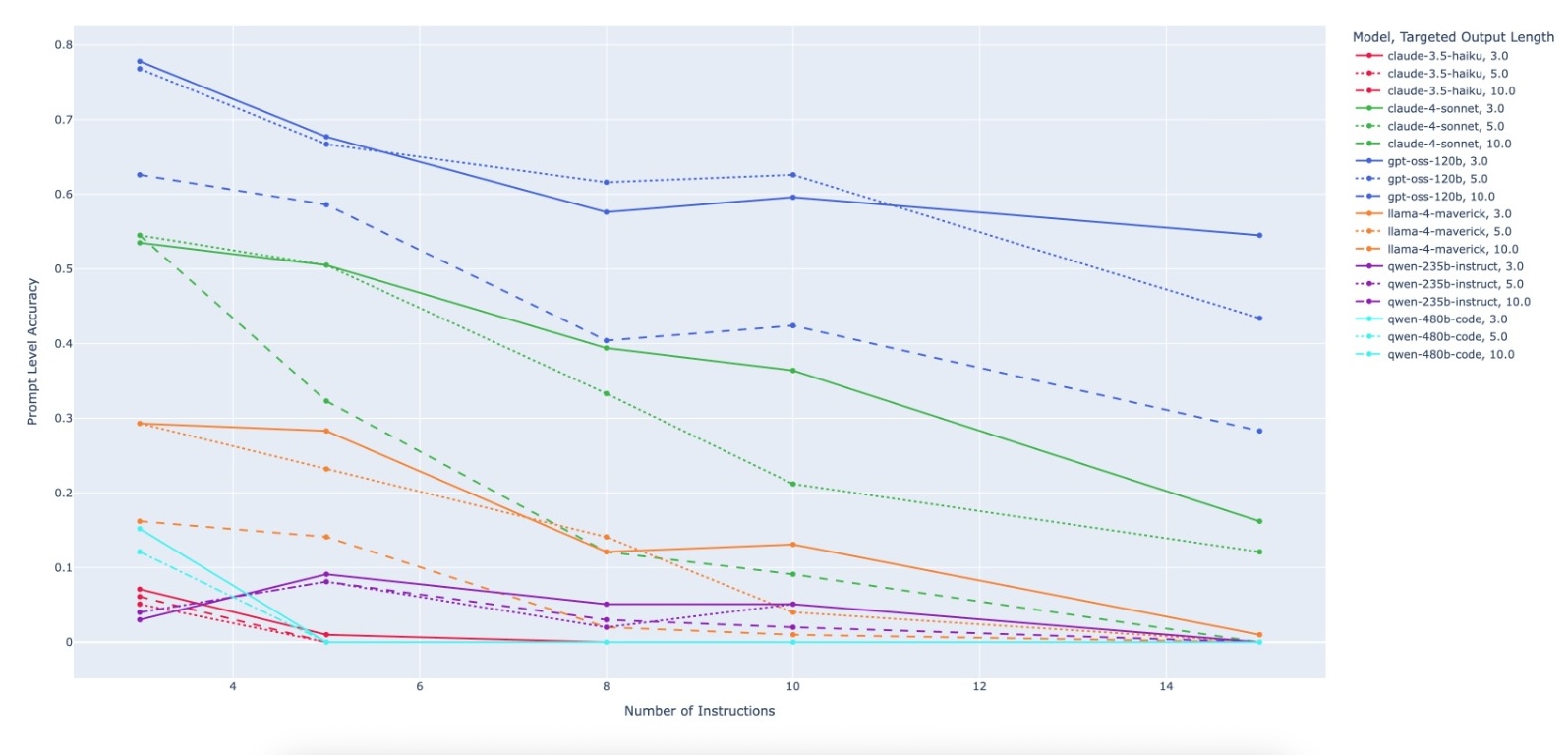
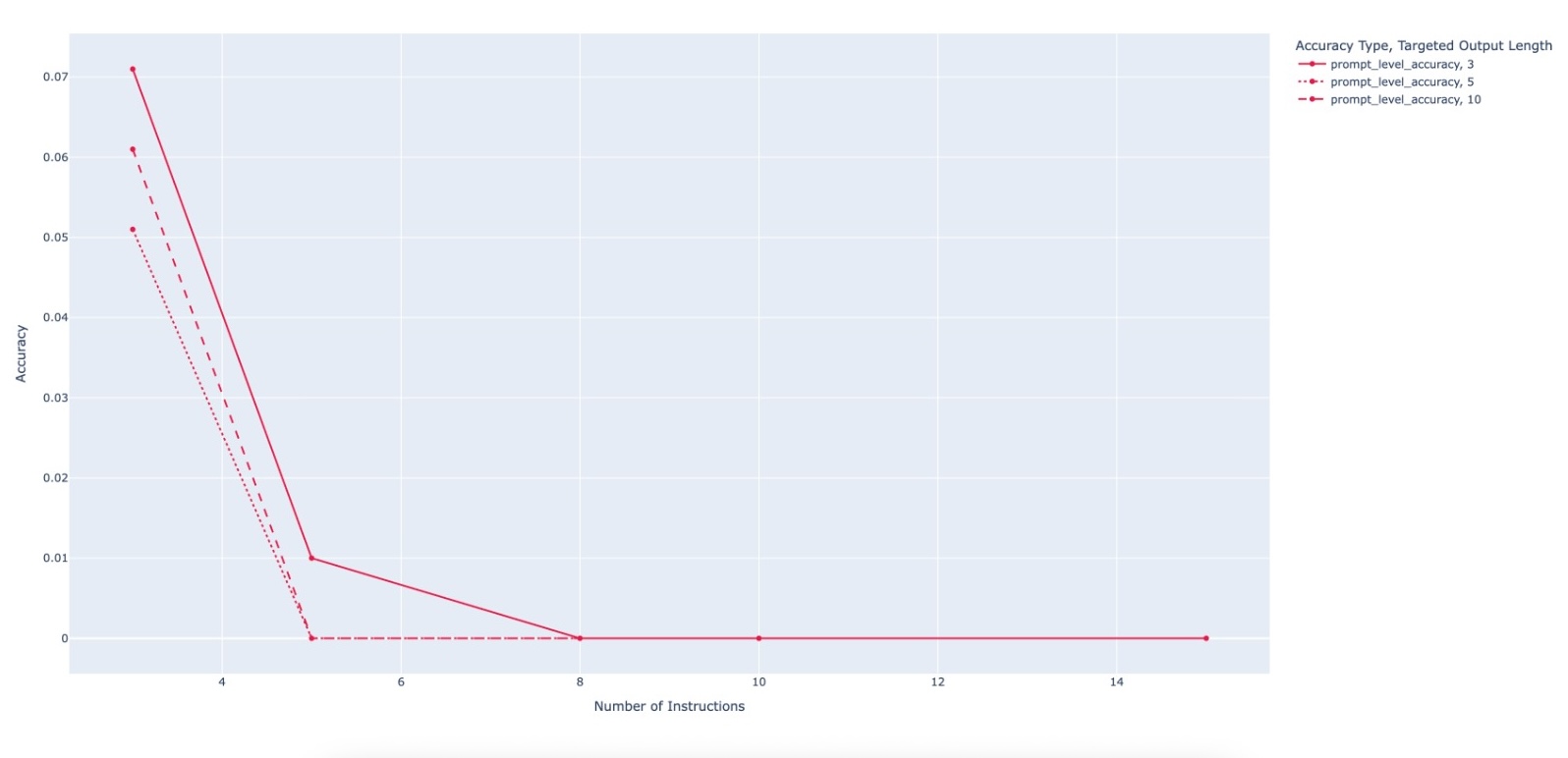
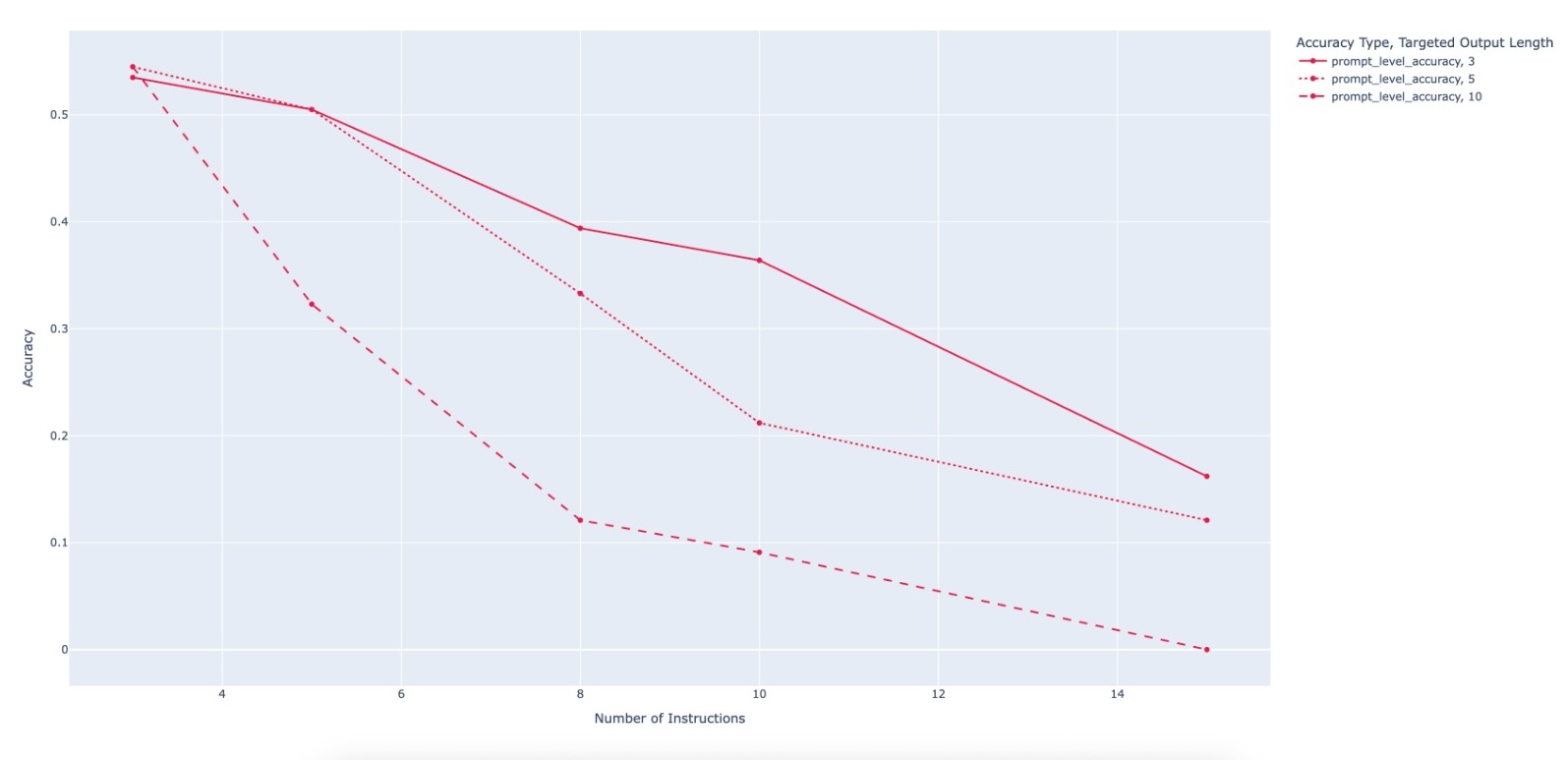
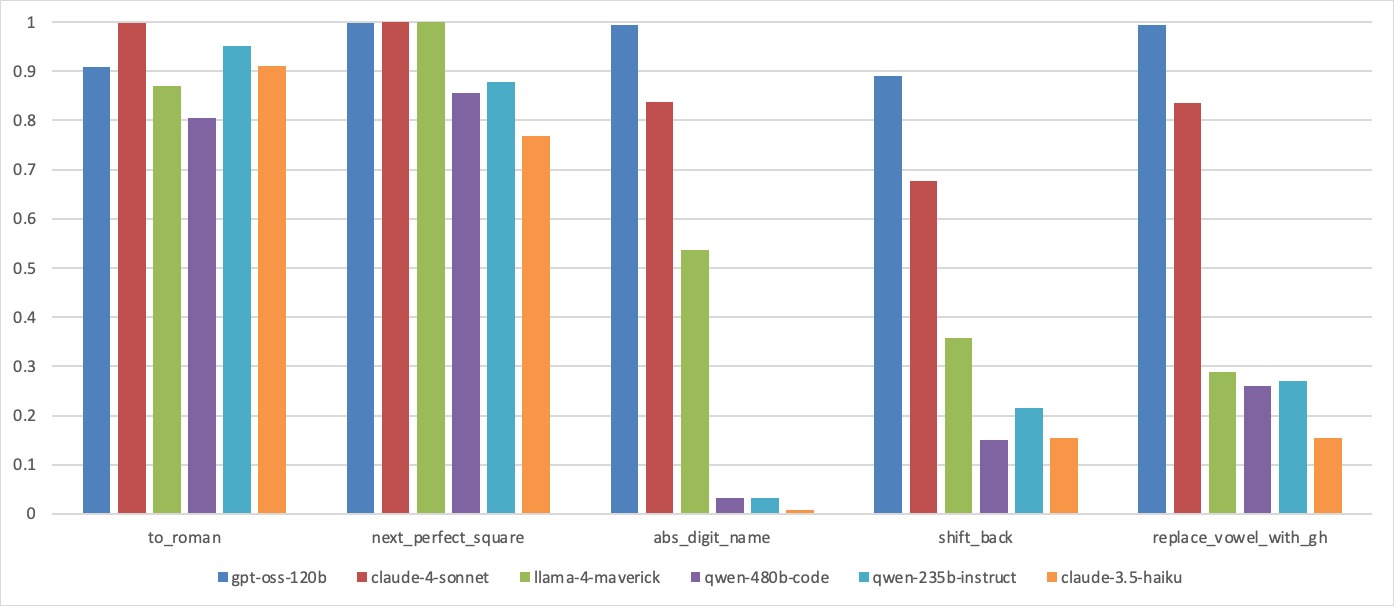
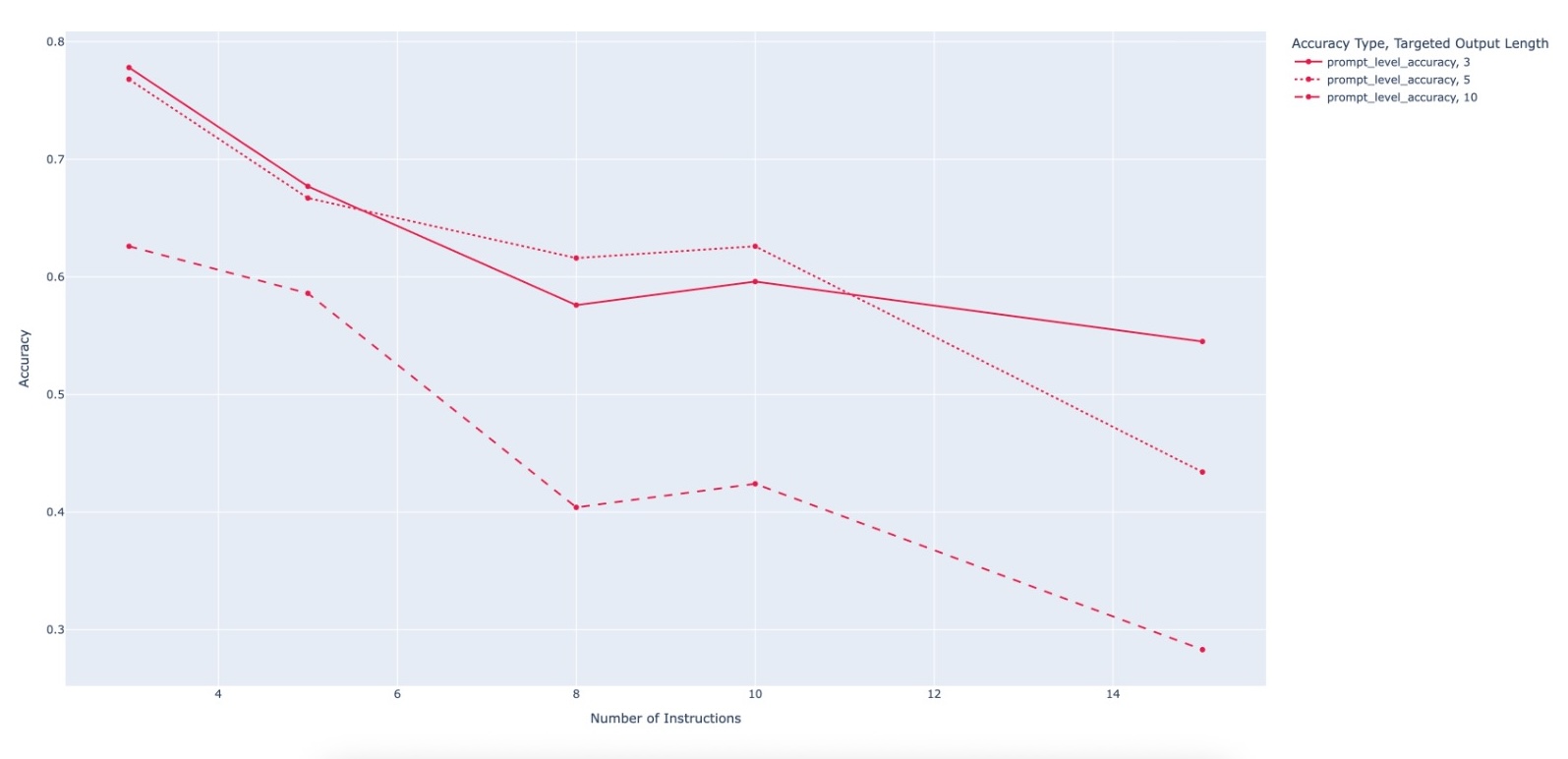
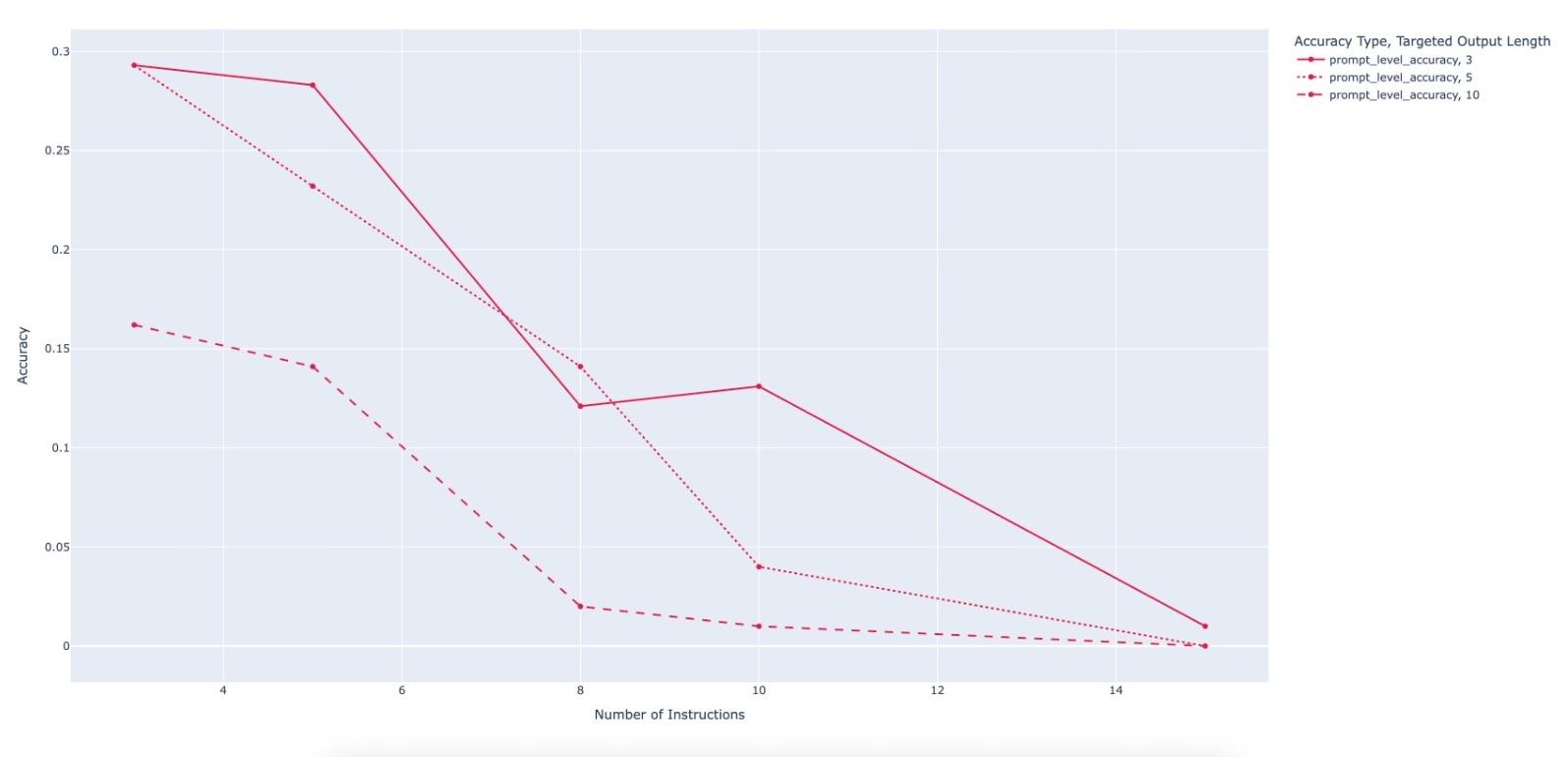
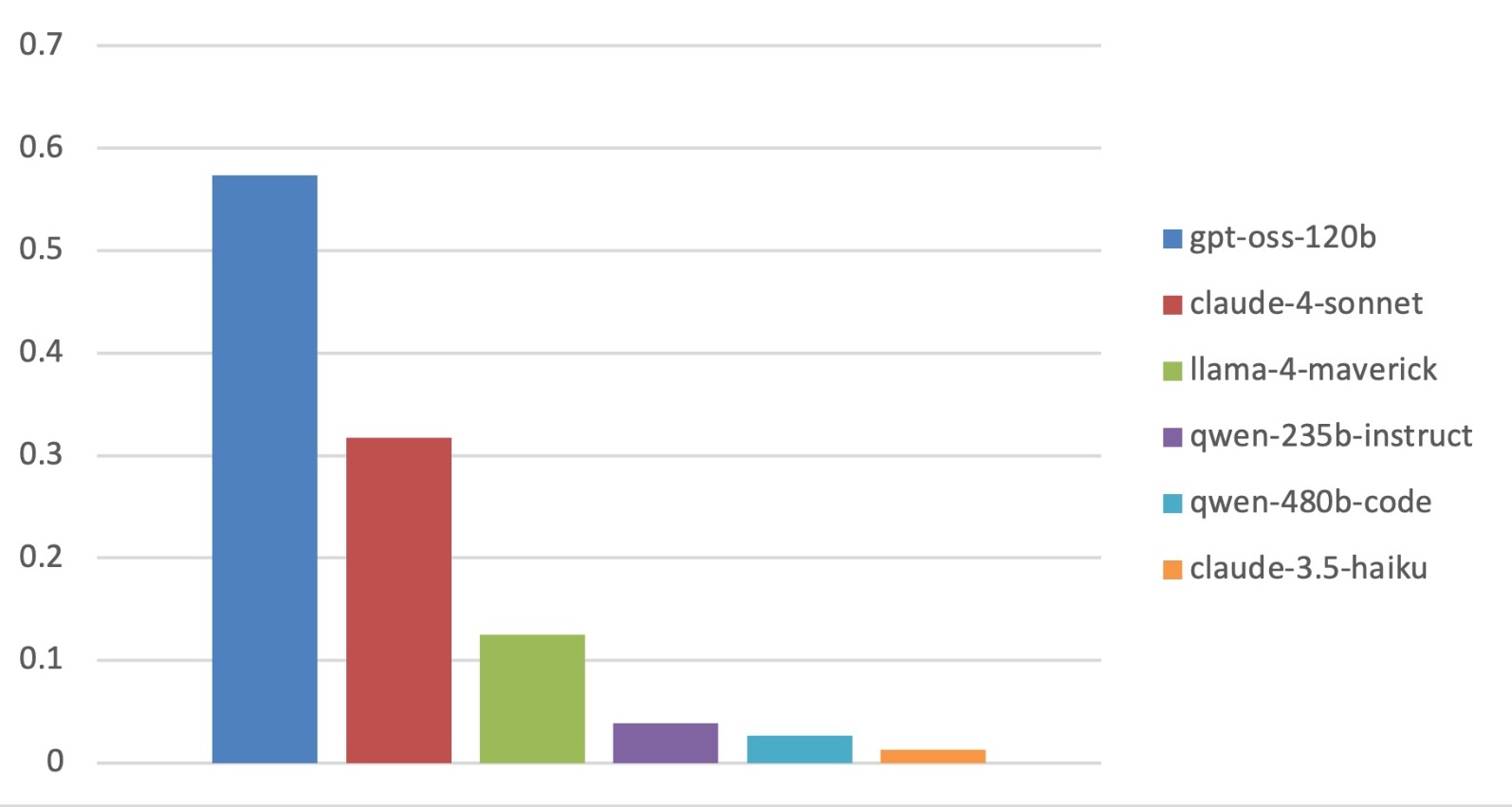
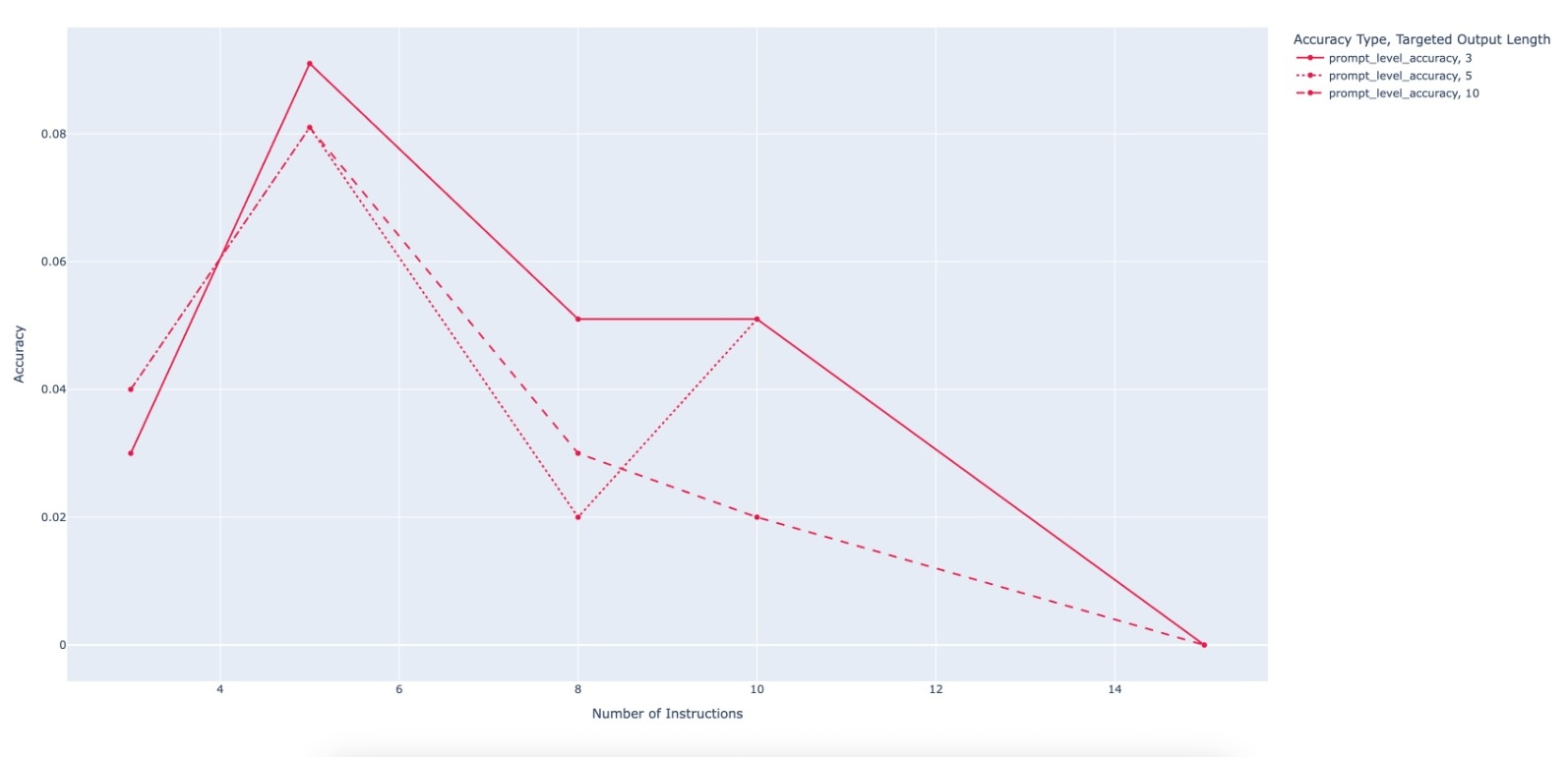
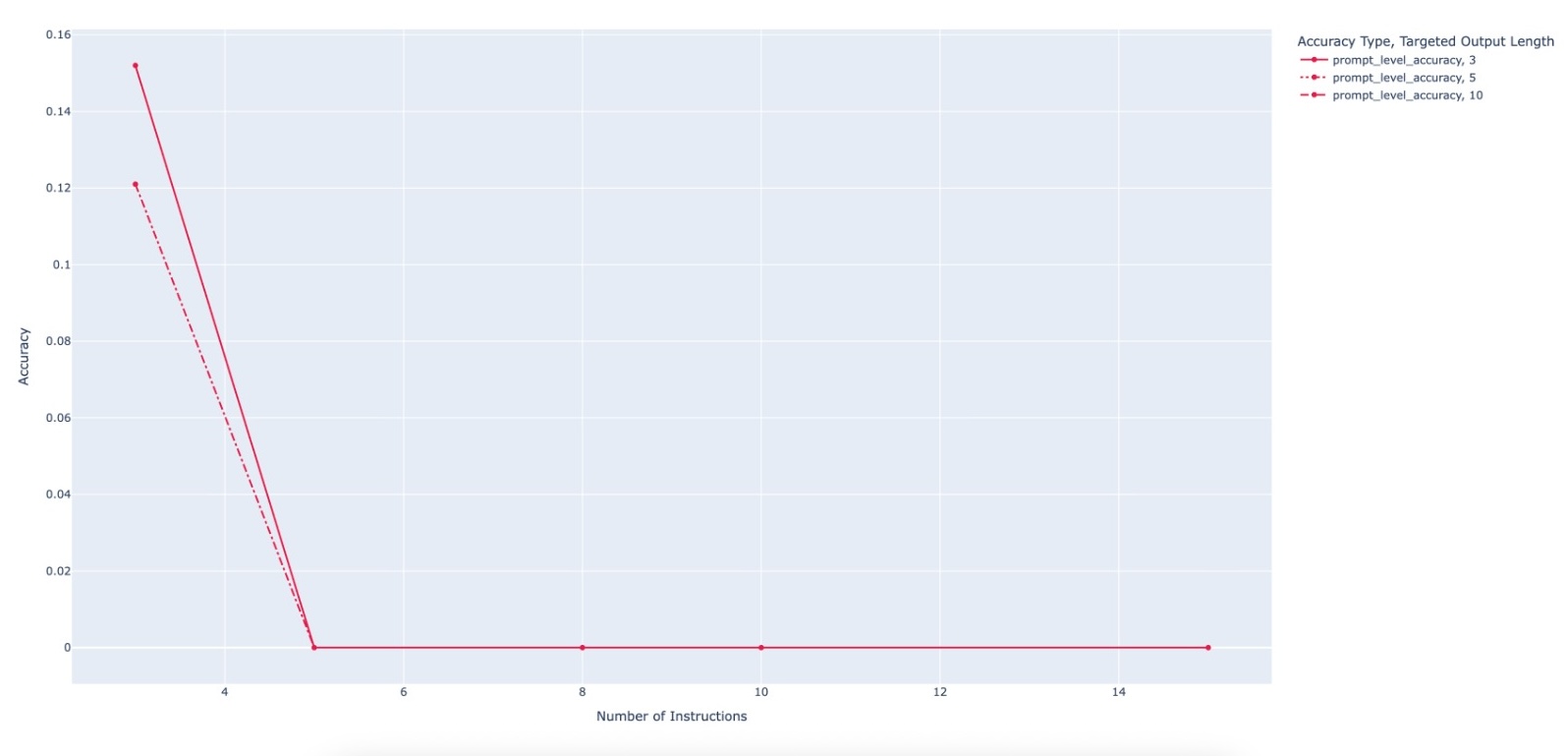
evaluating multiple state-of-the-art LLMs. Our results demonstrate
that PACIFIC can produce increasingly challenging benchmarks
that effectively differentiate instruction-following and dry running
capabilities, even among advanced models. Overall, our framework
offers a scalable, contamination-resilient methodology for assessing
core competencies of LLMs in code-related tasks.
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for profit or commercial advantage and that copies bear this notice and the full citation
on the first page. Copyrights for components of this work owned by others than the
author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or
republish, to post on servers or to redistribute to lists, requires prior specific permission
and/or a fee. Request permissions from permissions@acm.org.
AI-SQE, Rio de Janeiro, Brazil
© 2025 Copyright held by the owner/author(s). Publication rights licensed to ACM.
ACM ISBN 978-x-xxxx-xxxx-x/YYYY/MM
https://doi.org/10.1145/nnnnnnn.nnnnnnn
CCS Concepts
• Software and its engineering →Empirical software valida-
tion.
Keywords
Code instruction following benchmark, automated expected results
generation, controlled level of benchmark difficulty, automated
benchmark generation
ACM Reference Format:
Itay Dreyfuss, Antonio Abu Nassar, Samuel Ackerman, Axel Ben David,
Eitan Farchi, Rami Katan, Orna Raz, and Marcel Zalmanovici. 2026. PACIFIC:
a framework for generating benchmarks to check Precise Automatically
Checked Instruction Following In Code. In Proceedings of The 1st Interna-
tional Workshop on AI for Software Quality Evaluation: Judgment, Metrics,
Benchmarks, and Beyond (AI-SQE). ACM, New York, NY, USA, 14 pages.
https://doi.org/10.1145/nnnnnnn.nnnnnnn
Accepted at AI-SQE 2026.
1
Introduction
Large Language Models (LLMs) have demonstrated remarkable ca-
pabilities in natural language understanding and generation, lead-
ing to the development of highly effective code assistants. These
systems rely heavily on their ability to follow user instructions
accurately, a trait that is central to their utility in real-world soft-
ware engineering tasks. While high-quality benchmarks exist for
evaluating instruction-following in natural language domains, such
as IFEval[21], there remains a major gap in the availability of bench-
marks tailored to code-related instruction following. Existing bench-
marks in this space often depend on complex evaluation methods,
such as using LLMs themselves as judges, and typically lack deter-
ministic metrics and a focus on code dry-running.
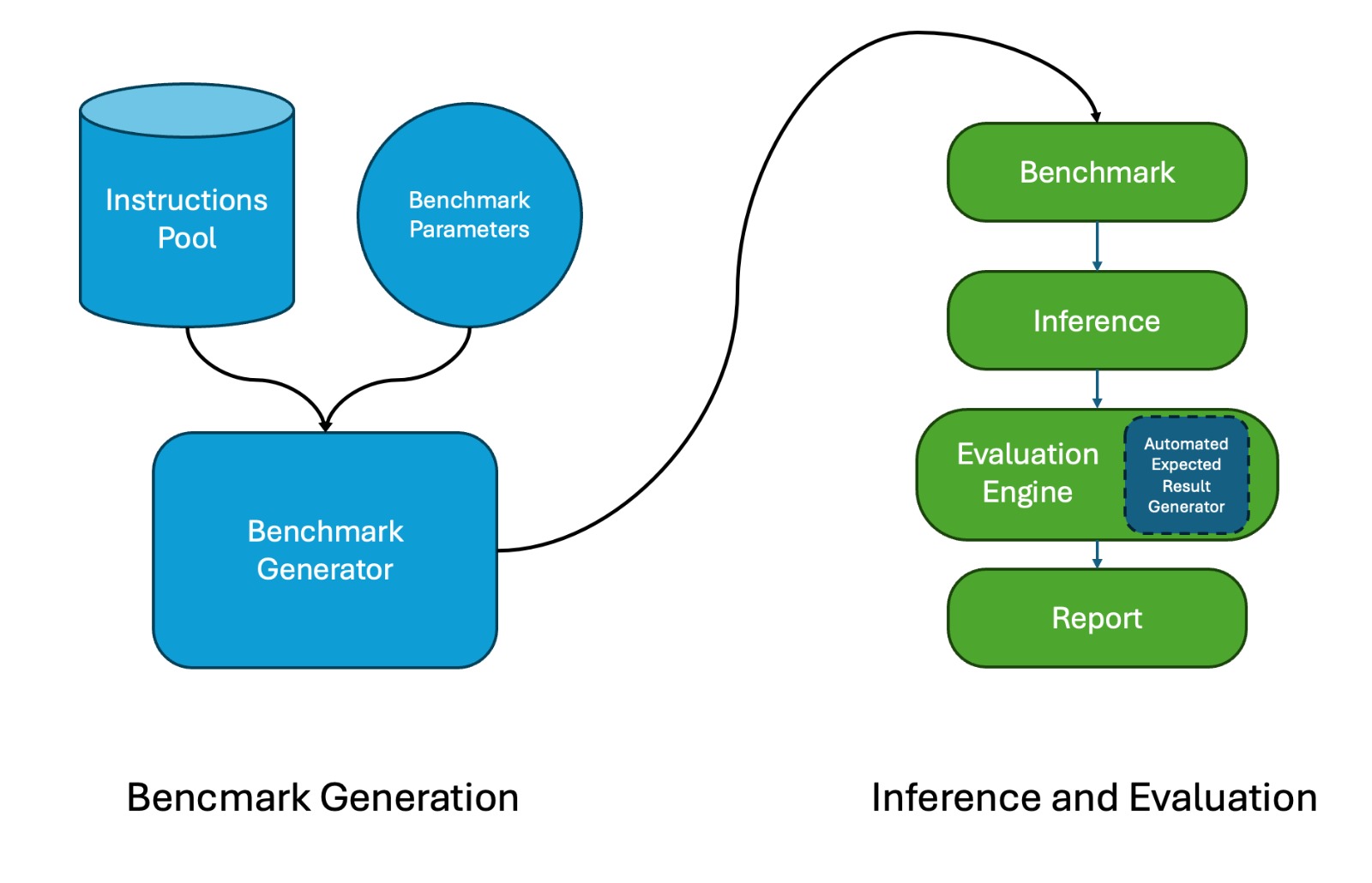
To address these limitations, we present PACIFIC, a framework
designed to automatically generate benchmarks that evaluate both
sequential instruction-following and code dry-running capabilities
of LLMs. The framework emphasizes the ability of LLMs to simulate
arXiv:2512.10713v2 [cs.SE] 22 Dec 2025
AI-SQE, April 14, 2026, Rio de Janeiro, Brazil
Dreyfuss, et al.
code execution (i.e. dry-running) without relying on external tools
or agentic mechanisms.
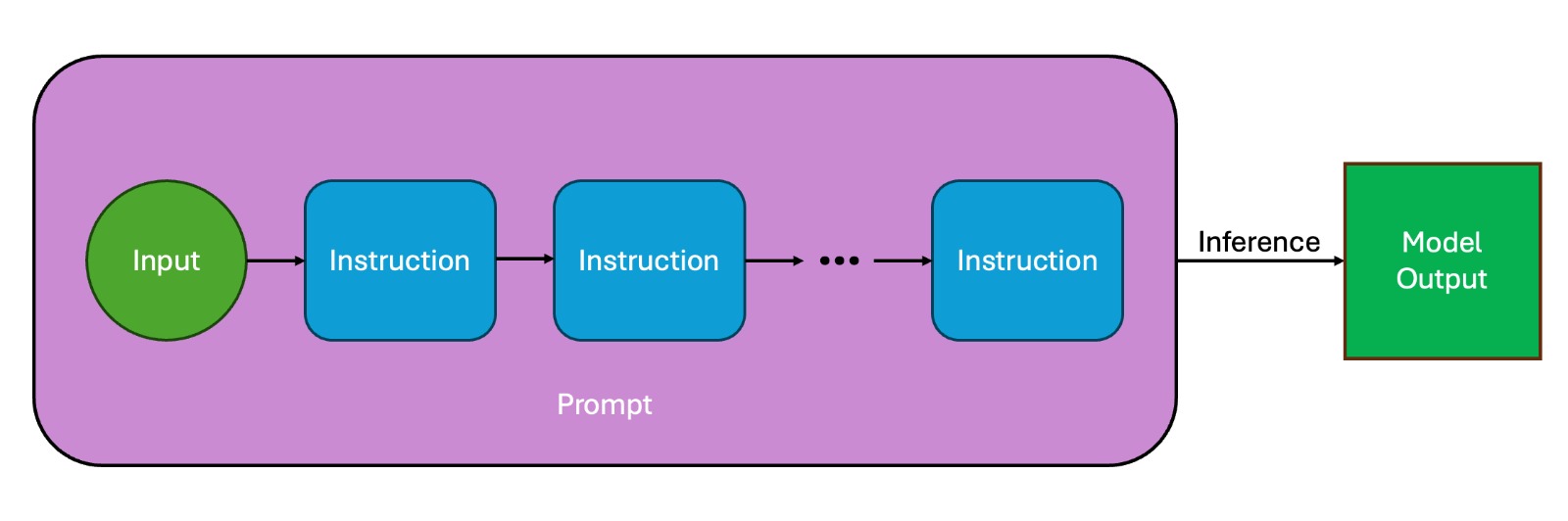
The framework operates on a set of instructions that are used as
building blocks. Each instruction describes actions to perform on
the output of a given algorithm when dry-running it with a given
input. Below are a couple of
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.