Towards Fine-Grained Recognition with Large Visual Language Models: Benchmark and Optimization Strategies
📝 Original Info
- Title: Towards Fine-Grained Recognition with Large Visual Language Models: Benchmark and Optimization Strategies
- ArXiv ID: 2512.10384
- Date: 2025-12-11
- Authors: Researchers from original ArXiv paper
📝 Abstract
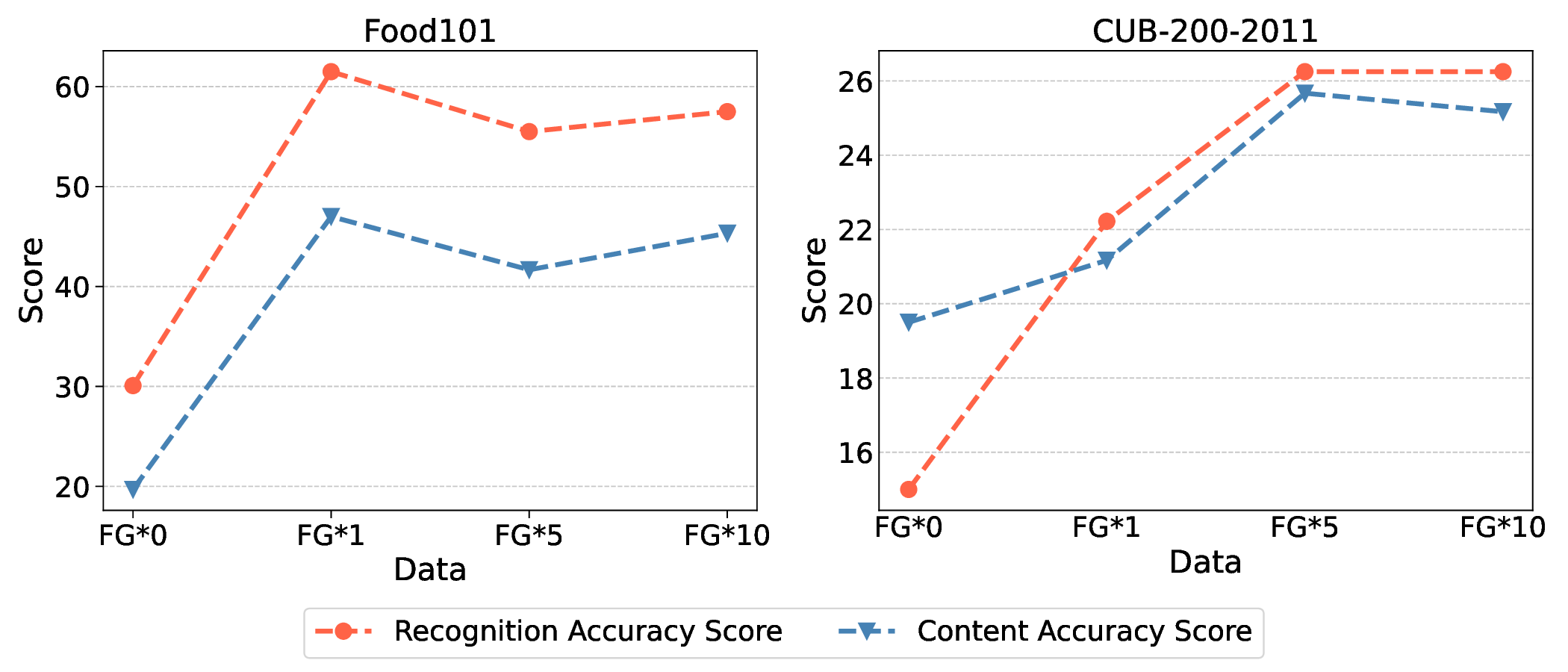
Large Vision Language Models (LVLMs) have made remarkable progress, enabling sophisticated vision-language interaction and dialogue applications. However, existing benchmarks primarily focus on reasoning tasks, often neglecting fine-grained recognition, which is crucial for practical application scenarios. To address this gap, we introduce the Fine-grained Recognition Open World (FROW) benchmark, designed for detailed evaluation of LVLMs with GPT-4o. On the basis of that, we propose a novel optimization strategy from two perspectives: data construction and training process, to improve the performance of LVLMs. Our dataset includes mosaic data, which combines multiple short-answer responses, and open-world data, generated from real-world questions and answers using GPT-4o, creating a comprehensive framework for evaluating fine-grained recognition in LVLMs. Experiments show that mosaic data improves category recognition accuracy by 1% and open-world data boosts FROW benchmark accuracy by 10%-20% and content accuracy by 6%-12%. Meanwhile, incorporating fine-grained data into the pretraining phase can improve the model's category recognition accuracy by up to 10%. The benchmark will be available at https://github.com/pc-inno/FROW.💡 Deep Analysis
Deep Dive into Towards Fine-Grained Recognition with Large Visual Language Models: Benchmark and Optimization Strategies.Large Vision Language Models (LVLMs) have made remarkable progress, enabling sophisticated vision-language interaction and dialogue applications. However, existing benchmarks primarily focus on reasoning tasks, often neglecting fine-grained recognition, which is crucial for practical application scenarios. To address this gap, we introduce the Fine-grained Recognition Open World (FROW) benchmark, designed for detailed evaluation of LVLMs with GPT-4o. On the basis of that, we propose a novel optimization strategy from two perspectives: data construction and training process, to improve the performance of LVLMs. Our dataset includes mosaic data, which combines multiple short-answer responses, and open-world data, generated from real-world questions and answers using GPT-4o, creating a comprehensive framework for evaluating fine-grained recognition in LVLMs. Experiments show that mosaic data improves category recognition accuracy by 1% and open-world data boosts FROW benchmark accuracy by
📄 Full Content
📸 Image Gallery