We present the Generalized Policy Gradient (GPG) Theorem, specifically designed for Transformer-based policies. Notably, we demonstrate that both standard Policy Gradient Theorem and GRPO emerge as special cases within our GPG framework. Furthermore, we explore its practical applications in training Large Language Models (LLMs), offering new insights into efficient policy optimization.
Deep Dive into 변형 트랜스포머 정책을 위한 일반화 정책 그래디언트 정리.
We present the Generalized Policy Gradient (GPG) Theorem, specifically designed for Transformer-based policies. Notably, we demonstrate that both standard Policy Gradient Theorem and GRPO emerge as special cases within our GPG framework. Furthermore, we explore its practical applications in training Large Language Models (LLMs), offering new insights into efficient policy optimization.
Proximal Policy Optimization (PPO) [24] and Group Relative Policy Optimization (GRPO) [25] rank among the most widely adopted policy gradient algorithms for training Large Language Models (LLMs), which predominantly employ the Transformer architecture [31]. However, these algorithms were initially developed for general reinforcement learning (RL) policies [28] rather than being specifically optimized for Transformer-based policies.
Given the pivotal role of LLMs in AI research, we address a critical question: Are there policy gradient methods inherently better suited for training Transformer-based LLM policies? We hypothesize that specialized algorithms could surpass generic policy gradient approaches in both theoretical alignment and empirical performance.
Our primary contribution is a Generalized Policy Gradient (GPG) Theorem tailored for Transformerbased policies. We prove that both the standard Policy Gradient Theorem and GRPO emerge as concrete implementations derived from our GPG framework. Additionally, we investigate practical applications of the GPG Theorem for LLM training, offering insights into its potential advantages over existing methods.
We consider the standard RL framework [28], in which a learning agent interacts with an environment. The state, action, and reward at each timestep t are denoted by s t , a t , and r t , respectively. The environment is characterized by the state transition probabilities P (s t+1 |s t , a t ) and the reward function r t = R(s t , a t ). The agent’s decision making procedure at each timestep is characterized by a stochastic policy π θ (s t |a t ) = P (a t |s t ; θ) ∈ [0, 1], with the objective function to maximize the long-term cumulative reward R(τ ) = H t=1 r t , where τ = ⟨s 1 , a 1 , r 1 , …, s H , a H , r H ⟩ is the decision trajectory and H is the horizon.
Define the parameterized policy π θ (a t |s t ) and its objective function J(θ) = E τ ∼π θ [R(τ )]. We use gradient acsend to find the optimal θ * that can maximize the objective:
The Policy Gradient Theorem [29] says that for any differentiable policy and any objective function, the gradient of the parameterized policy is as follows:
A general form of the Policy Gradient Theorem is:
where Φ t may be one of the following:
• H t=1 r t : total reward of the trajectory.
• A GAE(γ,λ) (s t , a t ): the generalized advantage estimator (GAE) for the advantage function.
In practice, the advantage function A π θ (s t , a t ) is a common choice because it can achieve better bias-variance trade-off [23].
TRPO [22], PPO [24] and GRPO [25] are the special implementations of the Policy Gradient Theorem. PPO and its predecessor TRPO optimize policies (i.e., getting the new policies) with guaranteed monotonic improvement by considering the trust region of old policies. In practice, this is implemented with the off-policy importance sampling strategy (i.e., using old policies π θold to sample trajectories to estimate the gradient of new policies π θ ):
where ρ θ (s t ) is the station state distribution under policy π θ . Therefore, the (unclipped) off-policy “surrogate” objective can be represented as:
However, “without a constraint, maximization of the above J(θ) would lead to an excessively large policy update” [24], hence, PPO also applies the region clip strategy to penalize changes to the policy that move the ratio r t (θ) away from 1. So the formal (clipped) objective of PPO is:
where ϵ is a small value such as 0.1.
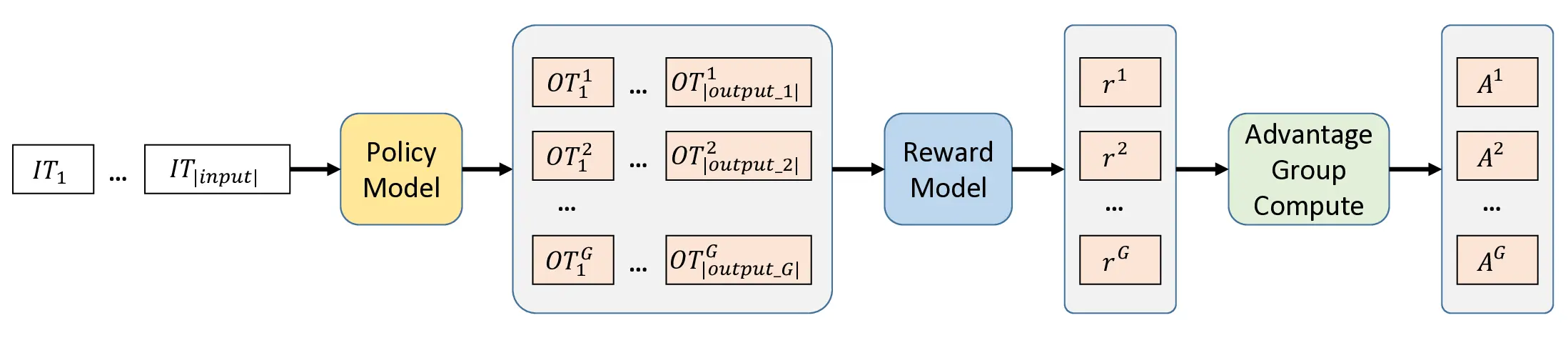
GRPO shares the same objective as PPO, but uses a group of G output trajectories to compute the advantage A π θ old (s, a) as shown in Figure 1. This is especially useful for scenarios (e.g., math and coding) where the partial trajectory is not verifiable, but the whole trajectories can be evaluated with verified rewards.
The chain rule of probability theory states that for any joint probability distribution P (x 1 , x 2 , …, x n ), the following decomposition holds:
Similarly, for any conditional joint probability distribution P (x 1 , x 2 , …, x n |y 1 , y 2 , …, y m ), the chain rule yields the following decomposition:
3 Generalized Policy Gradient Theorem
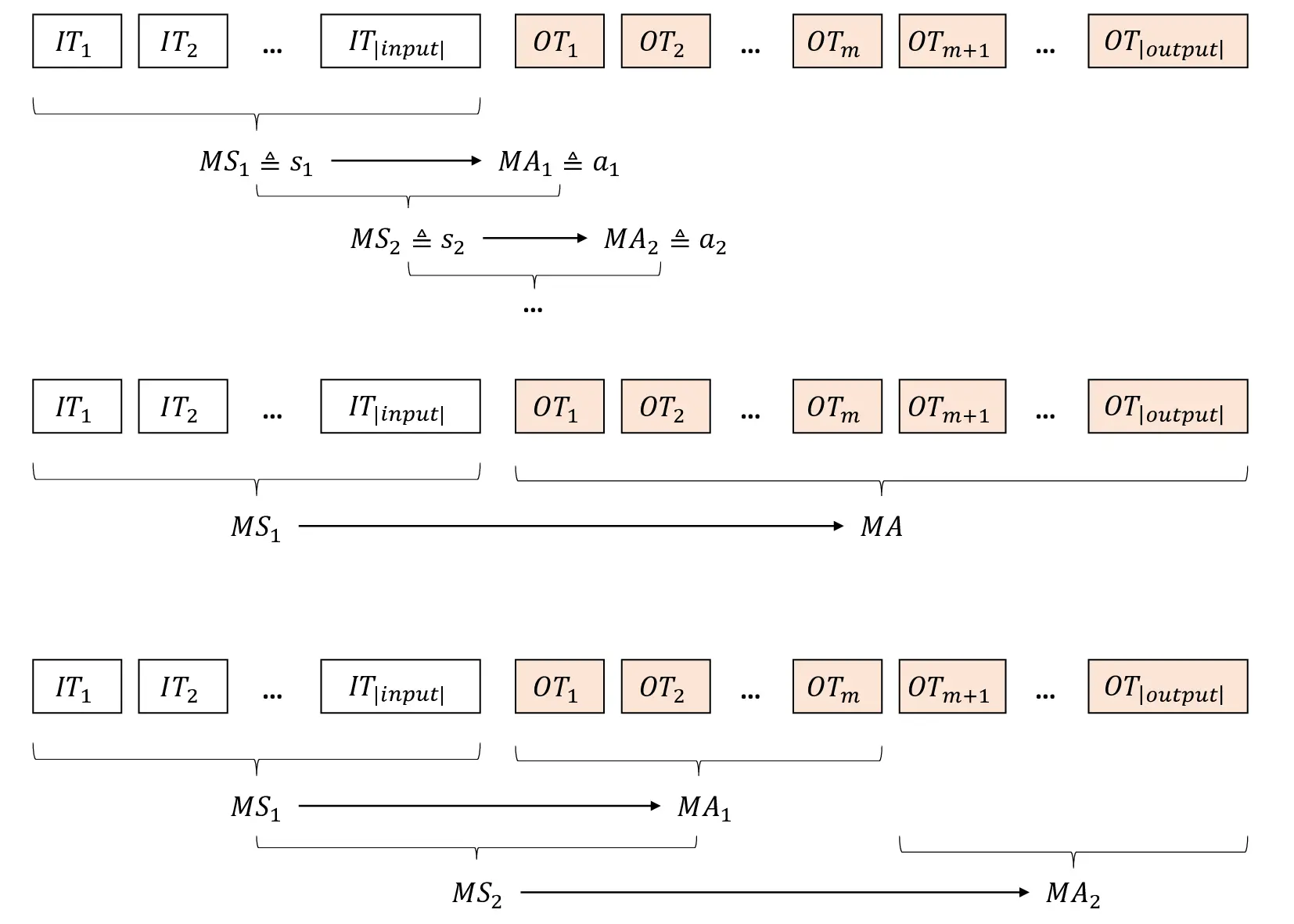
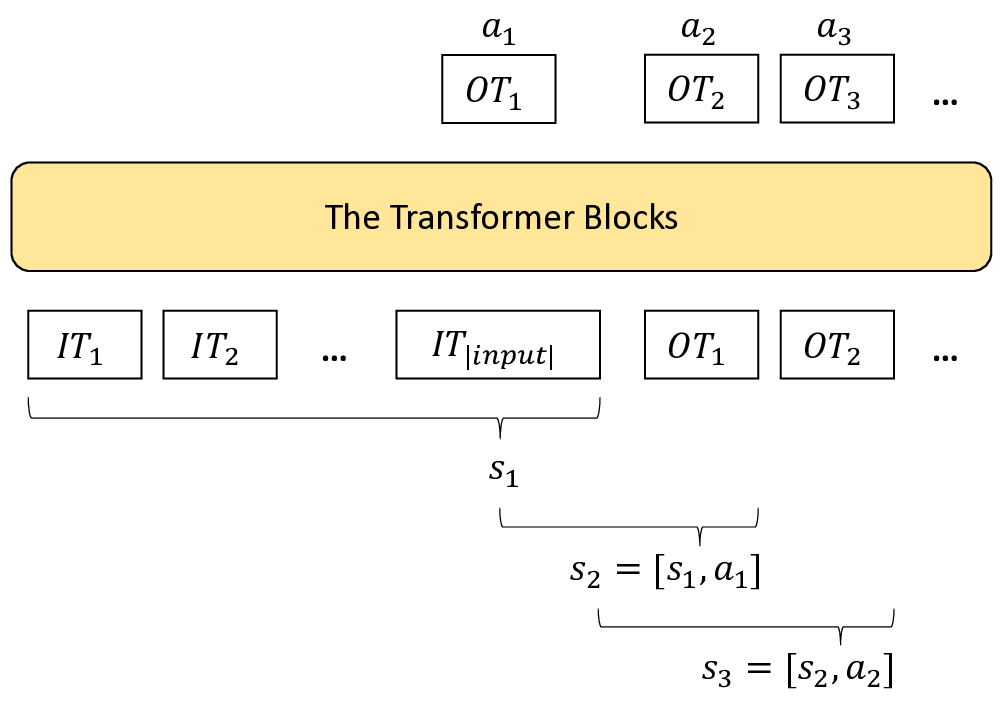
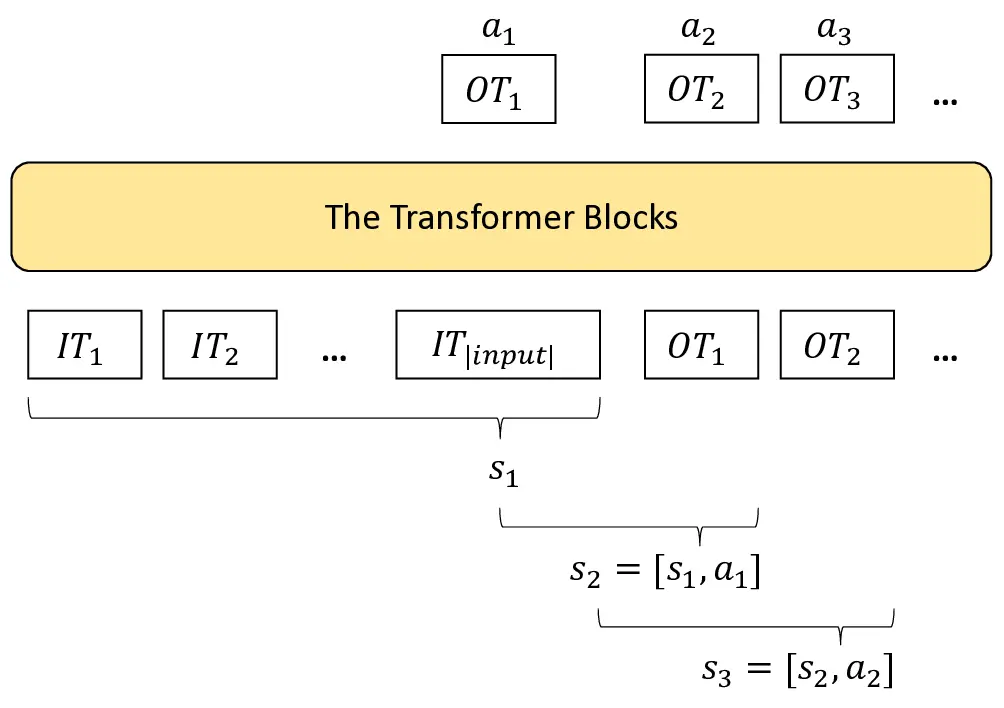
The Transformer Blocks
where T represents the macro timestep.
Given the macro states M S i and macro actions M A i as defined above, we establish the following Generalized Policy Gradient (GPG) Theorem for Transformer-based policies:
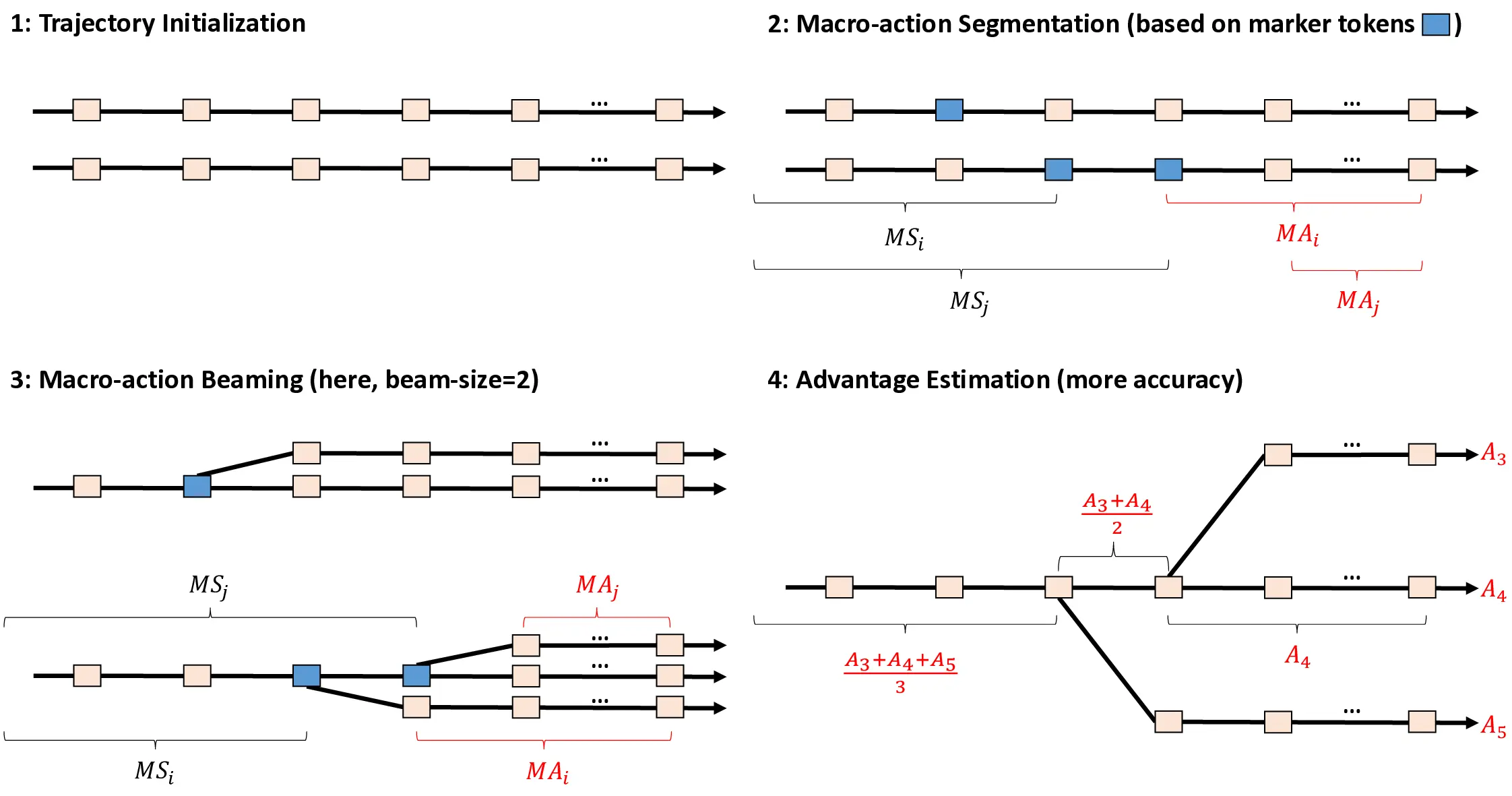
A principal advantage of the GPG Theorem lies in its accommodation of macro-action segments with arbitrary length. This flexible formulation yields significant practical benefits: notably, it naturally supports trajectory segmentation using special tokens (e.g.
). We elaborate on these applications and implementation considerations in Section 4.
We now present the formal derivation of the Generalized Policy Gradient (GPG) Theorem:
The key steps in the proof are as follows:
- The equality between Equations ( 20) and ( 21) follows from the deterministic state transition in Transforme
…(Full text truncated)…
This content is AI-processed based on ArXiv data.