📝 Original Info
- Title: Confucius Code Agent: Scalable Agent Scaffolding for Real-World Codebases
- ArXiv ID: 2512.10398
- Date: 2025-12-11
- Authors: Researchers from original ArXiv paper
📝 Abstract
Real-world software engineering tasks require coding agents that can operate on massive repositories, sustain long-horizon sessions, and reliably coordinate complex toolchains at test time. Existing research-grade coding agents offer transparency but struggle when scaled to heavier, production-level workloads, while production-grade systems achieve strong practical performance but provide limited extensibility, interpretability, and controllability. We introduce the Confucius Code Agent (CCA), a software engineering agent that can operate at large-scale codebases. CCA is built on top of the Confucius SDK, an agent development platform structured around three complementary perspectives: Agent Experience (AX), User Experience (UX), and Developer Experience (DX). The SDK supports a unified orchestrator with advanced context management for long-context reasoning, a persistent note-taking system for cross-session continual learning, and a modular extension system for reliable tool use. In addition, we introduce a meta-agent that automates the construction, evaluation, and refinement of agents through a build-test-improve cycle, enabling rapid agent development on new tasks and tool stacks. Instantiated on the Confucius SDK using the meta-agent, CCA demonstrates strong performance on real-world software engineering tasks. On SWE-Bench-Pro, CCA achieves a Resolve@1 of 59%, exceeding prior research baselines as well as commercial results, under identical repositories, model backends, and tool access.
💡 Deep Analysis
Deep Dive into Confucius Code Agent: Scalable Agent Scaffolding for Real-World Codebases.
Real-world software engineering tasks require coding agents that can operate on massive repositories, sustain long-horizon sessions, and reliably coordinate complex toolchains at test time. Existing research-grade coding agents offer transparency but struggle when scaled to heavier, production-level workloads, while production-grade systems achieve strong practical performance but provide limited extensibility, interpretability, and controllability. We introduce the Confucius Code Agent (CCA), a software engineering agent that can operate at large-scale codebases. CCA is built on top of the Confucius SDK, an agent development platform structured around three complementary perspectives: Agent Experience (AX), User Experience (UX), and Developer Experience (DX). The SDK supports a unified orchestrator with advanced context management for long-context reasoning, a persistent note-taking system for cross-session continual learning, and a modular extension system for reliable tool use. In a
📄 Full Content
Confucius Code Agent: Scalable Agent Scaffolding
for Real-World Codebases
Sherman Wong1,∗, Zhenting Qi2,∗, Zhaodong Wang1,∗, Nathan Hu1,∗,
Samuel Lin1, Jun Ge1, Erwin Gao1, Wenlin Chen1, Yilun Du2, Minlan Yu1,2, Ying Zhang1
1Meta, 2Harvard
∗Core Contributors
Real-world software engineering tasks require coding agents that can operate on massive repositories,
sustain long-horizon sessions, and reliably coordinate complex toolchains at test time. Existing
research-grade coding agents offer transparency but struggle when scaled to heavier, production-level
workloads, while production-grade systems achieve strong practical performance but provide limited
extensibility, interpretability, and controllability. We introduce the Confucius Code Agent (CCA), a
software engineering agent that can operate at large-scale codebases. CCA is built on top of the
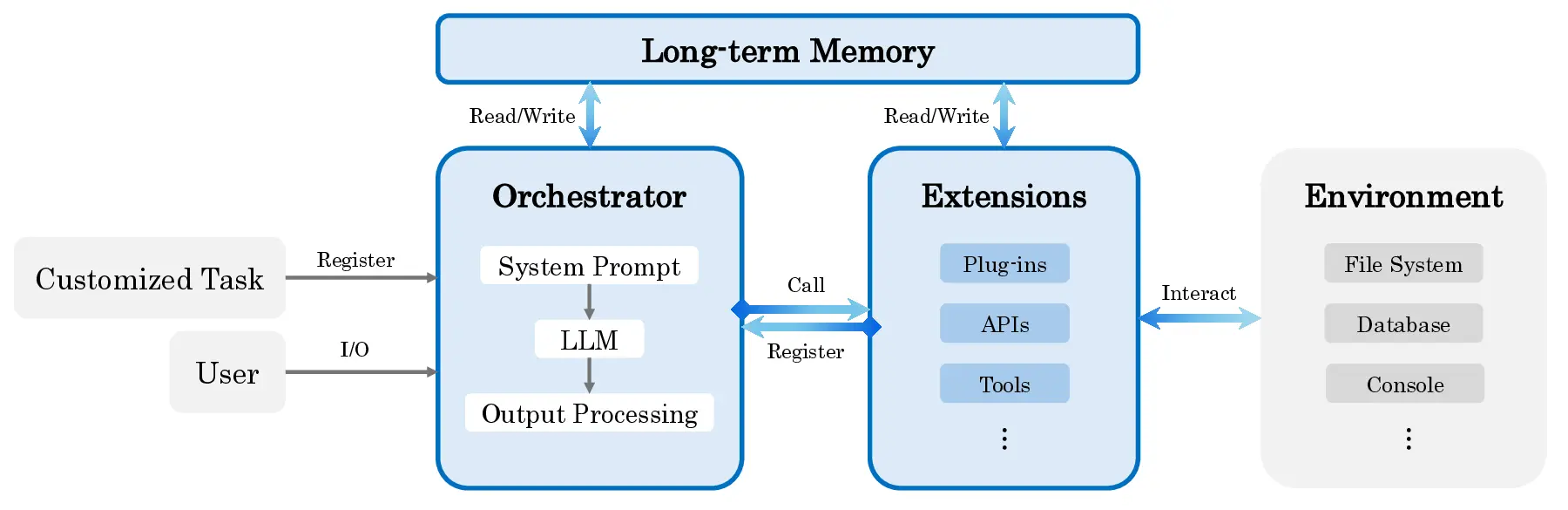
Confucius SDK, an agent development platform structured around three complementary perspectives:
Agent Experience (AX), User Experience (UX), and Developer Experience (DX). The SDK supports
a unified orchestrator with advanced context management for long-context reasoning, a persistent
note-taking system for cross-session continual learning, and a modular extension system for reliable
tool use. In addition, we introduce a meta-agent that automates the construction, evaluation, and
refinement of agents through a build-test-improve cycle, enabling rapid agent development on new
tasks and tool stacks. Instantiated on the Confucius SDK using the meta-agent, CCA demonstrates
strong performance on real-world software engineering tasks. On SWE-Bench-Pro, CCA achieves a
Resolve@1 of 59%, exceeding prior research baselines as well as commercial results, under identical
repositories, model backends, and tool access.
Date: February 4, 2026
Correspondence: Zhenting Qi at zhentingqi@g.harvard.edu
GitHub: https://github.com/facebookresearch/cca-swebench
30
35
40
45
50
55
60
Resolve Rate (%)
SWE-agent
GPT-5
SWE-agent
Claude Haiku 4.5
Cascade
SWE-1.5
SWE-agent
Claude Sonnet 4.5
II-Agent
GPT-5
II-Agent
Claude Sonnet 4.5
Live-SWE-agent
Claude Sonnet 4.5
SWE-agent
Claude Opus 4.5
OpenAI*
GPT-5.1
Anthropic*
Claude Opus 4.5
OpenAI*
GPT-5.2
OpenAI*
GPT-5.2-Codex
Confucius
Claude Sonnet 4
Confucius
Claude Sonnet 4.5
Confucius
Claude Opus 4.5
Confucius
GPT-5.2
36.3
39.5
40.8
43.7
43.9
45.1
45.8
45.9
50.8
52.0
55.6
56.4
45.5
52.7
54.3
59.0
Figure 1 Performance comparison on SWE-Bench-Pro benchmark. (* reported from Anthropic’s Claude Opus 4.5 system
card / OpenAI’s GPT-5.2-Codex system card.)
1
arXiv:2512.10398v6 [cs.CL] 3 Feb 2026
1
Introduction
Software engineering has rapidly emerged as a frontier application area for large language models (LLMs).
As models have grown more capable, they have progressed from simple program synthesis (Austin et al.,
2021), to automatic code completion (Chen et al., 2021), to general-purpose code generation (Li et al., 2022;
Lai et al., 2023), to understanding code execution (Gu et al., 2024), and competition-level programming
(Jain et al., 2024). Most recently, LLMs have demonstrated strong software engineering ability to tackle
real-world issue resolution in open-source repositories (Jimenez et al., 2023; Yang et al., 2024; Xia et al., 2025;
Zeng et al., 2025). To support such capabilities, more sophisticated agentic frameworks such as OpenHands
(Wang et al., 2024) scaffold LLMs with tools for search, code editing, and command execution, while agentless
prompting-based approaches (Xia et al., 2024) have shown that carefully structured prompts alone can also
perform well on multi-step software engineering tasks.
While model capabilities continue to improve, success in real-world software engineering depends not only
on the underlying LLM, but also on the agent scaffold: the orchestration, memory structures, and tool
abstractions surrounding the model. Empirically, even when the same backbone model is used, different
scaffolding strategies can lead to large performance disparities (Xia et al., 2025), suggesting that the design of
the agent’s cognitive and operational environment is a fundamental research dimension. However, existing
coding agents often rely on flat interaction histories, heuristic prompt engineering, or tightly coupled tool
pipelines, which are difficult to scale to the long-horizon, multi-file, multi-step workflows characteristic of
enterprise-level software engineering. This gap is most clearly manifested in two core challenges:
• C1: Long-context reasoning. Agents must efficiently localize relevant code within massive repositories and
perform multi-hop reasoning across dispersed modules, long tool traces, and deep execution histories.
• C2: Long-term memory. Agents should accumulate persistent knowledge across tasks and sessions, capturing
reusable patterns, failure modes, and invariants, rather than repeatedly rediscovering information or
reproducing past mistakes.
These challenges highlight that scalability in agentic software enginee
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.