📝 Original Info
- Title: What matters for Representation Alignment: Global Information or Spatial Structure?
- ArXiv ID: 2512.10794
- Date: 2025-12-11
- Authors: Researchers from original ArXiv paper
📝 Abstract
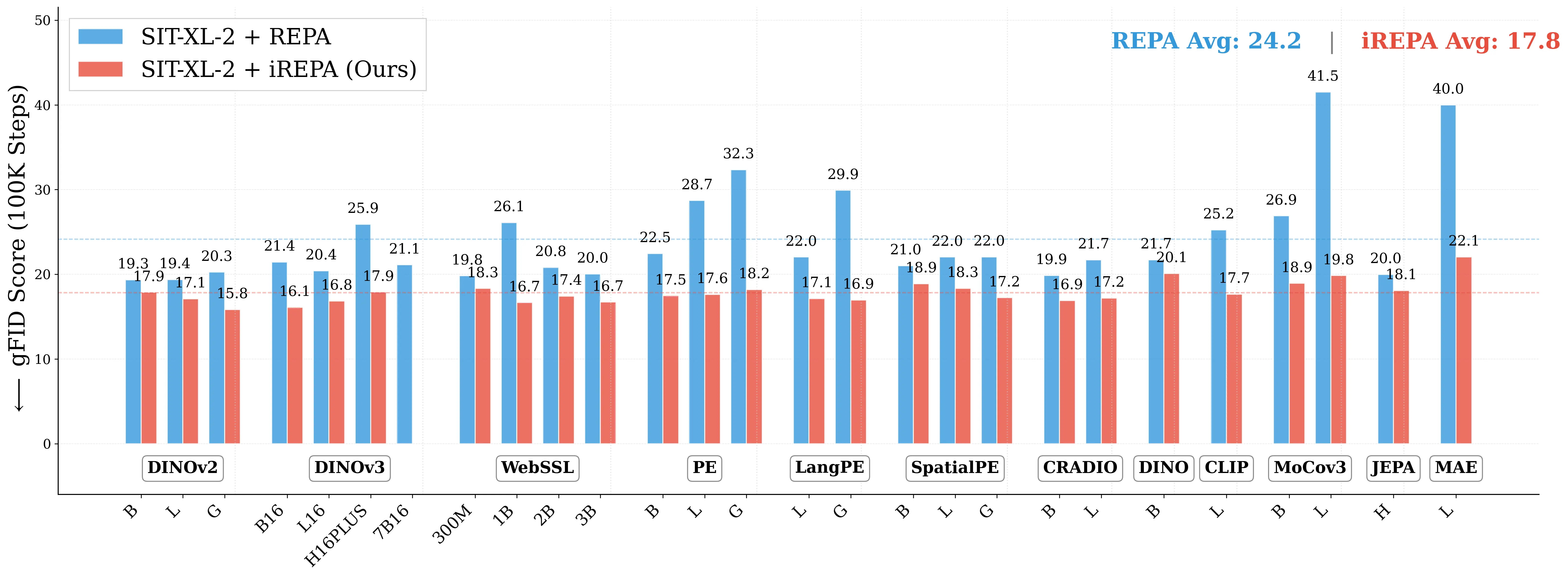
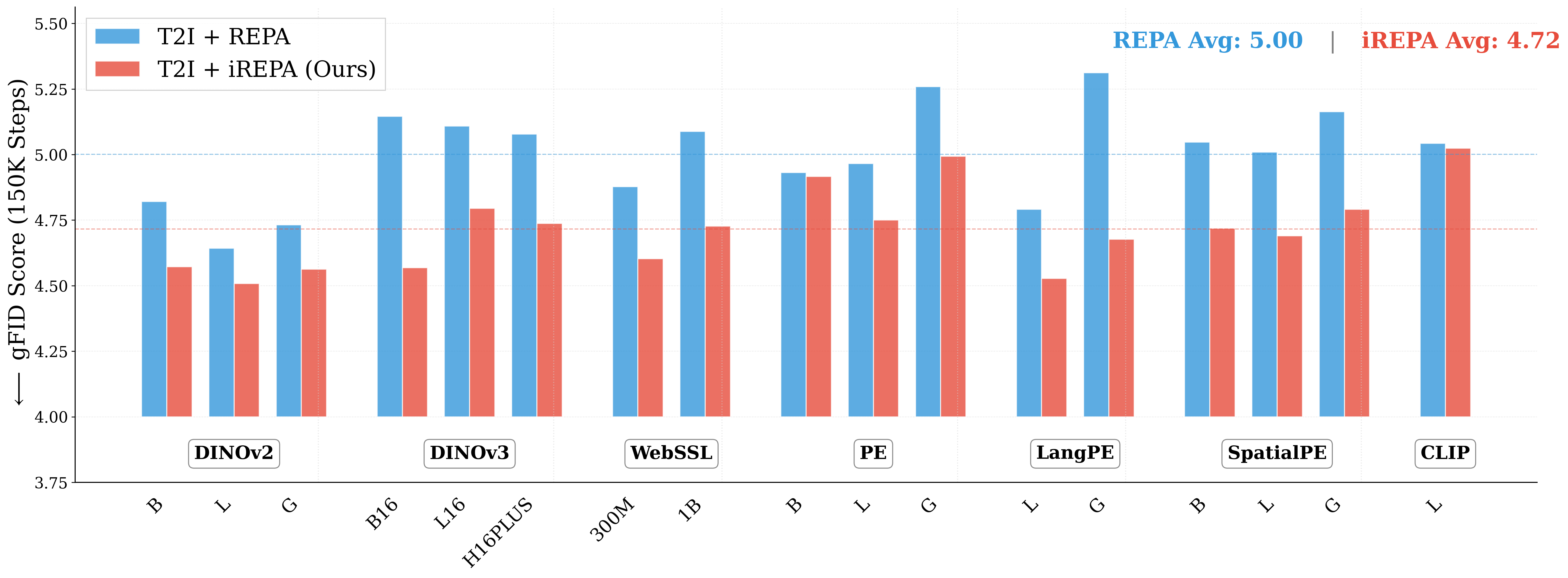
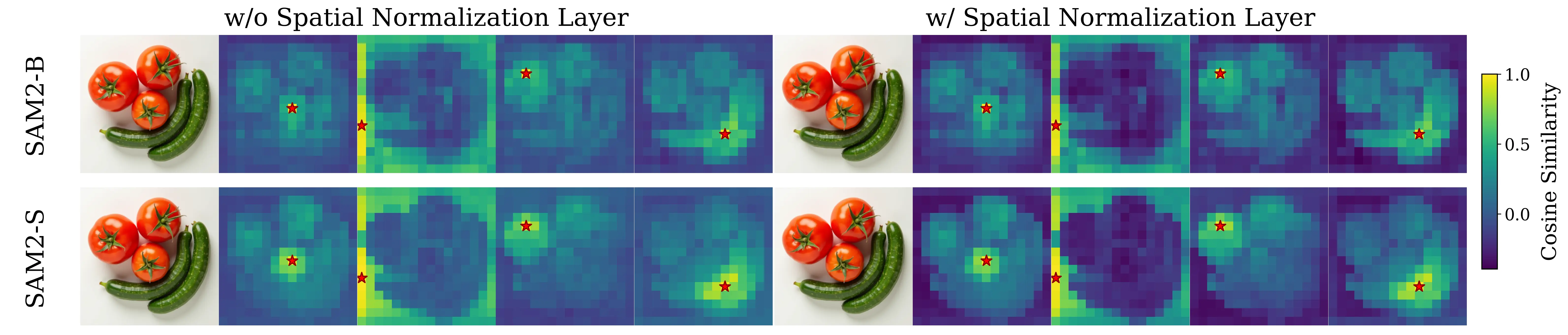
Representation alignment (REPA) guides generative training by distilling representations from a strong, pretrained vision encoder to intermediate diffusion features. We investigate a fundamental question: what aspect of the target representation matters for generation, its global semantic information (e.g., measured by ImageNet-1K accuracy) or its spatial structure (i.e. pairwise cosine similarity between patch tokens)? Prevalent wisdom holds that stronger global semantic performance leads to better generation as a target representation. To study this, we first perform a large-scale empirical analysis across 27 different vision encoders and different model scales. The results are surprising -spatial structure, rather than global performance, drives the generation performance of a target representation. To further study this, we introduce two straightforward modifications, which specifically accentuate the transfer of spatial information. We replace the standard MLP projection layer in REPA with a simple convolution layer and introduce a spatial normalization layer for the external representation. Surprisingly, our simple method (implemented in <4 lines of code), termed iREPA, consistently improves convergence speed of REPA, across a diverse set of vision encoders, model sizes, and training variants (such as REPA, REPA-E, Meanflow, JiT etc). Our work motivates revisiting the fundamental working mechanism of representational alignment and how it can be leveraged for improved training of generative models.
💡 Deep Analysis
Deep Dive into What matters for Representation Alignment: Global Information or Spatial Structure?.
Representation alignment (REPA) guides generative training by distilling representations from a strong, pretrained vision encoder to intermediate diffusion features. We investigate a fundamental question: what aspect of the target representation matters for generation, its global semantic information (e.g., measured by ImageNet-1K accuracy) or its spatial structure (i.e. pairwise cosine similarity between patch tokens)? Prevalent wisdom holds that stronger global semantic performance leads to better generation as a target representation. To study this, we first perform a large-scale empirical analysis across 27 different vision encoders and different model scales. The results are surprising -spatial structure, rather than global performance, drives the generation performance of a target representation. To further study this, we introduce two straightforward modifications, which specifically accentuate the transfer of spatial information. We replace the standard MLP projection layer in
📄 Full Content
Preprint.
WHAT MATTERS FOR REPRESENTATION ALIGNMENT:
GLOBAL INFORMATION OR SPATIAL STRUCTURE?
Jaskirat Singh12
Xingjian Leng2
Zongze Wu1
Liang Zheng2
Richard Zhang1
Eli Shechtman1
Saining Xie3
1Adobe Research
2ANU
3New York University
ABSTRACT
Representation alignment (REPA) guides generative training by distilling rep-
resentations from a strong, pretrained vision encoder to intermediate diffusion
features. We investigate a fundamental question: what aspect of the target repre-
sentation matters for generation, its global semantic information (e.g., measured
by ImageNet-1K accuracy) or its spatial structure (i.e. pairwise cosine similarity
between patch tokens)? Prevalent wisdom holds that stronger global semantic
performance leads to better generation as a target representation. To study this, we
first perform a large-scale empirical analysis across 27 different vision encoders
and different model scales. The results are surprising — spatial structure, rather
than global performance, drives the generation performance of a target representa-
tion. To further study this, we introduce two straightforward modifications, which
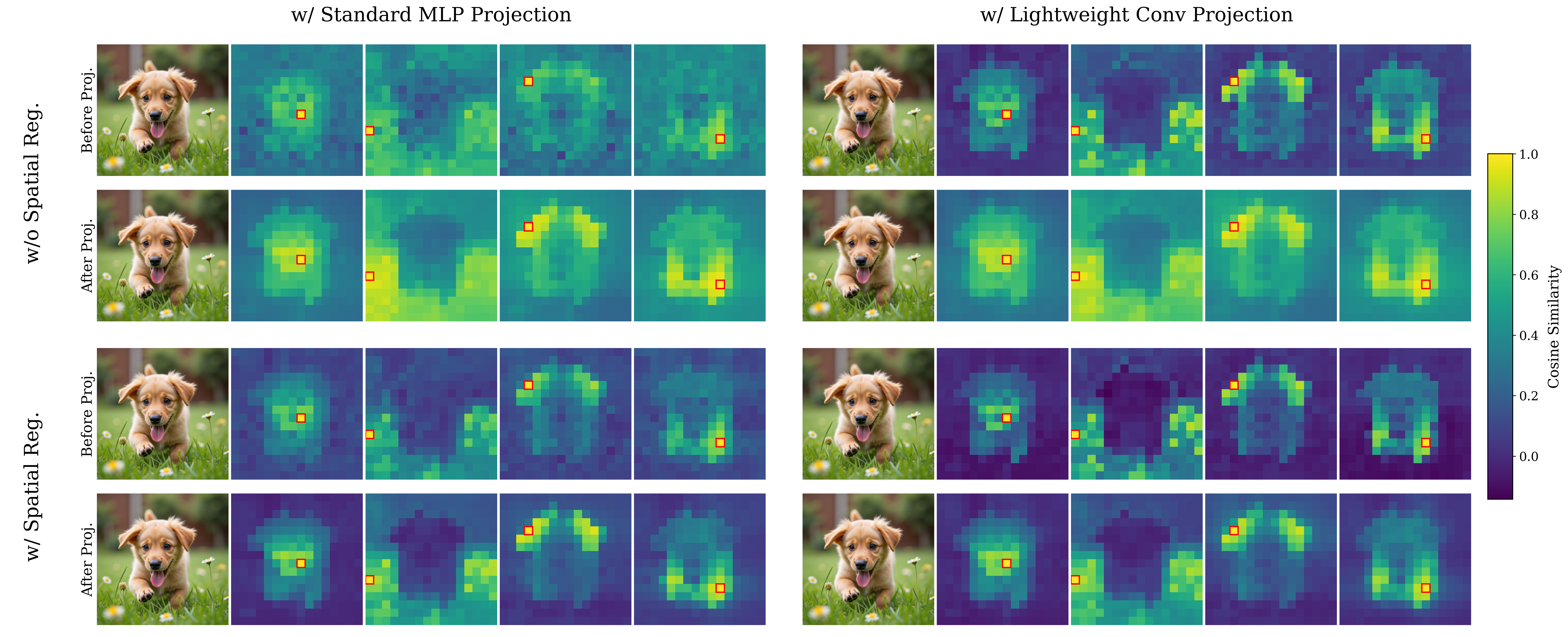
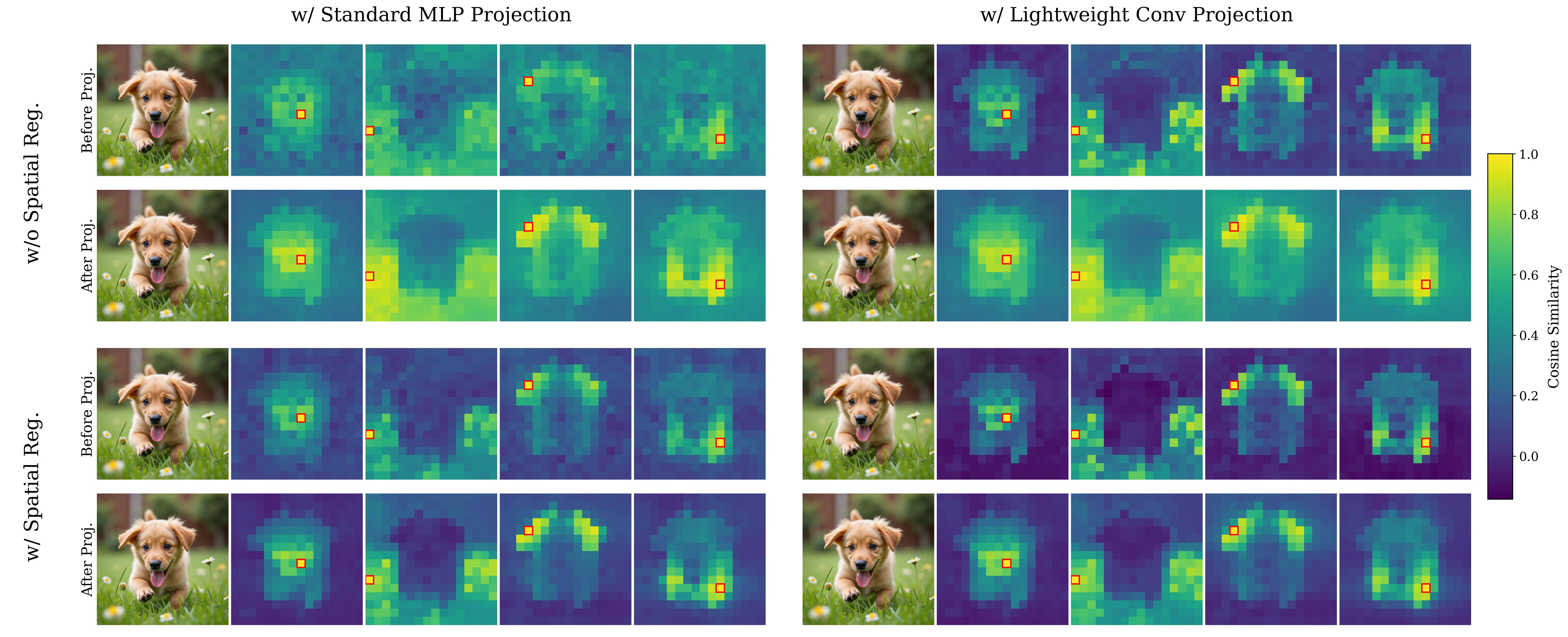
specifically accentuate the transfer of spatial information. We replace the standard
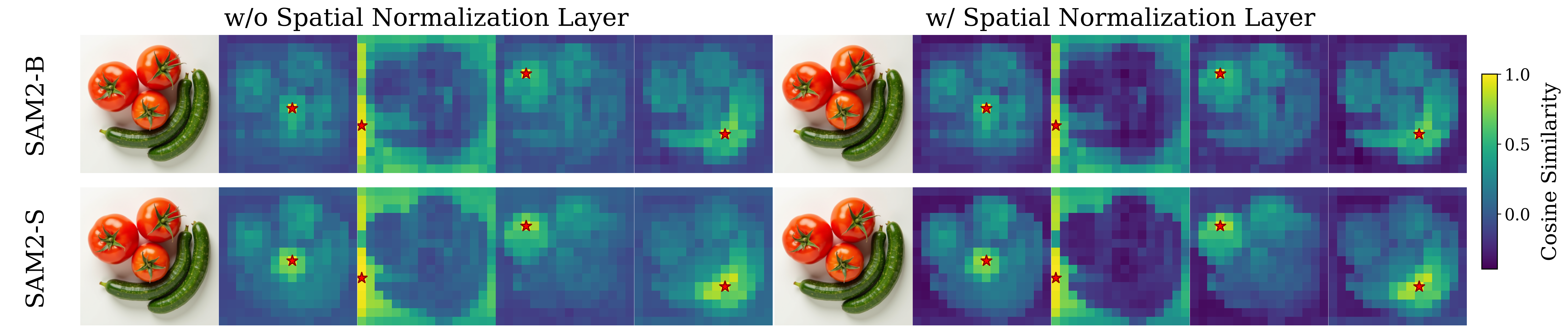
MLP projection layer in REPA with a simple convolution layer and introduce a
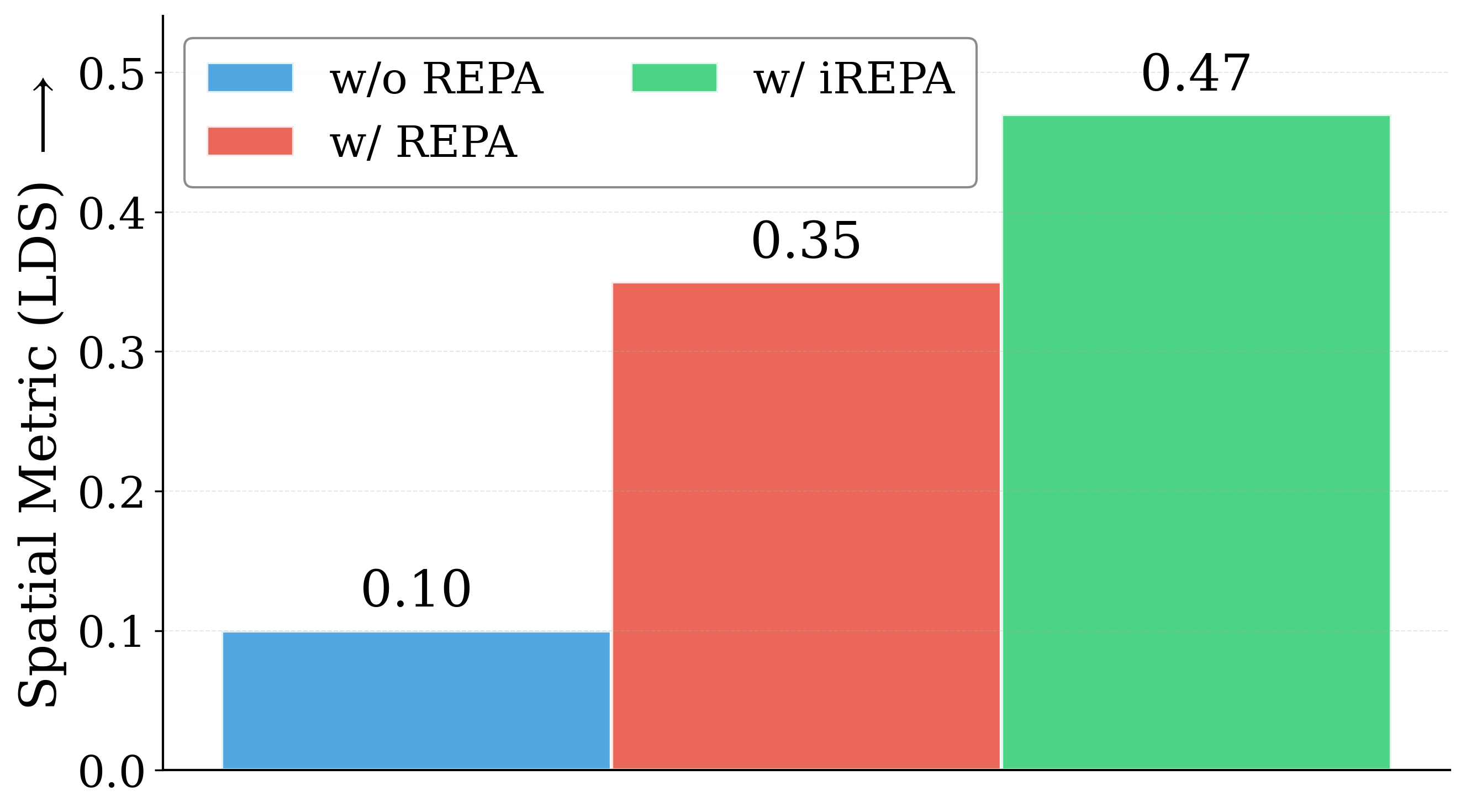
spatial normalization layer for the external representation. Surprisingly, our simple
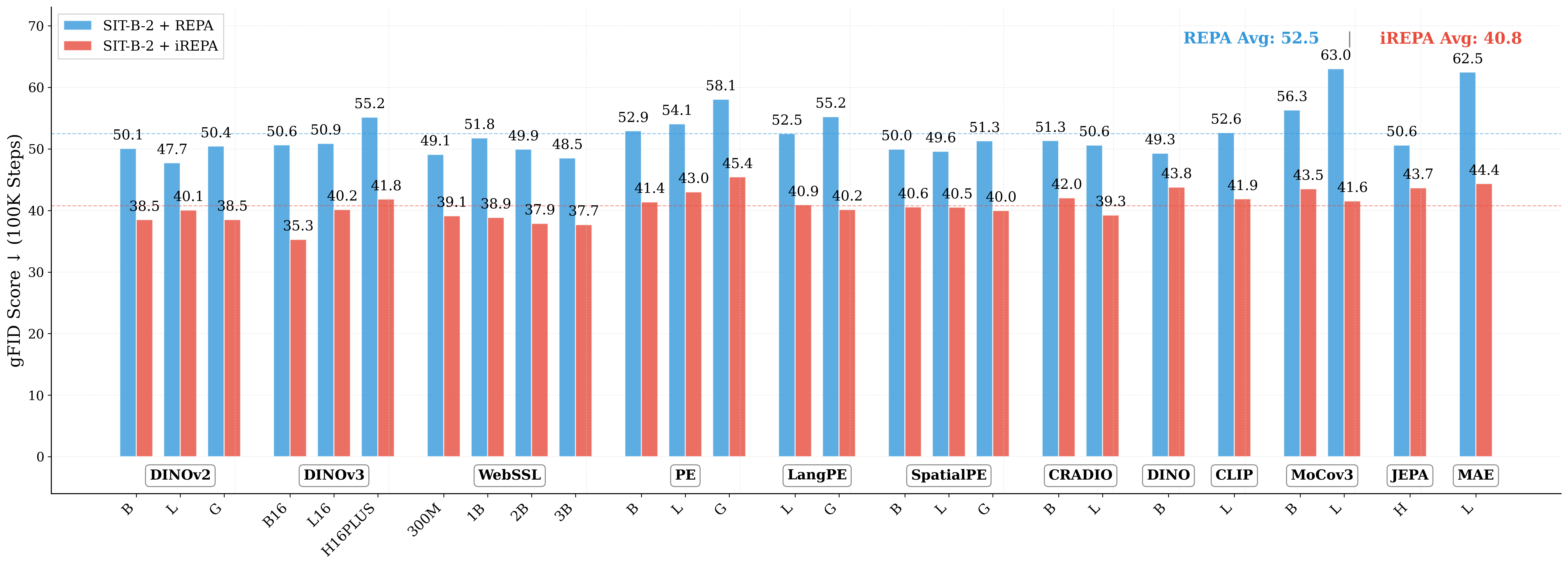
method (implemented in <4 lines of code), termed iREPA, consistently improves
convergence speed of REPA, across a diverse set of vision encoders, model sizes,
and training variants (such as REPA, REPA-E, Meanflow, JiT etc). Our work moti-
vates revisiting the fundamental working mechanism of representational alignment
and how it can be leveraged for improved training of generative models.
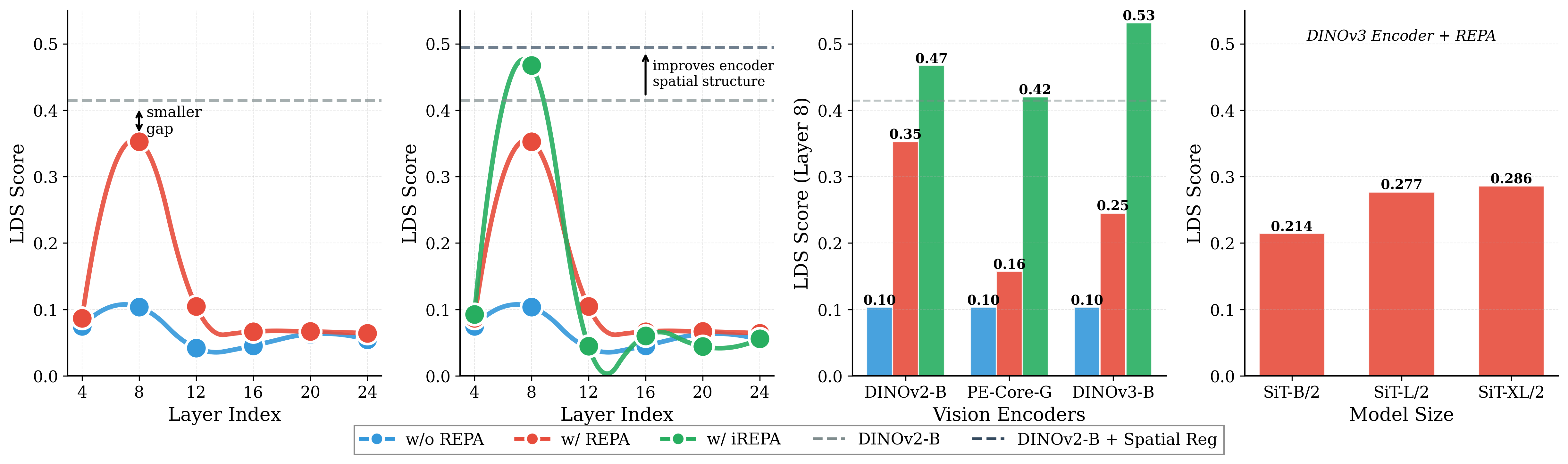
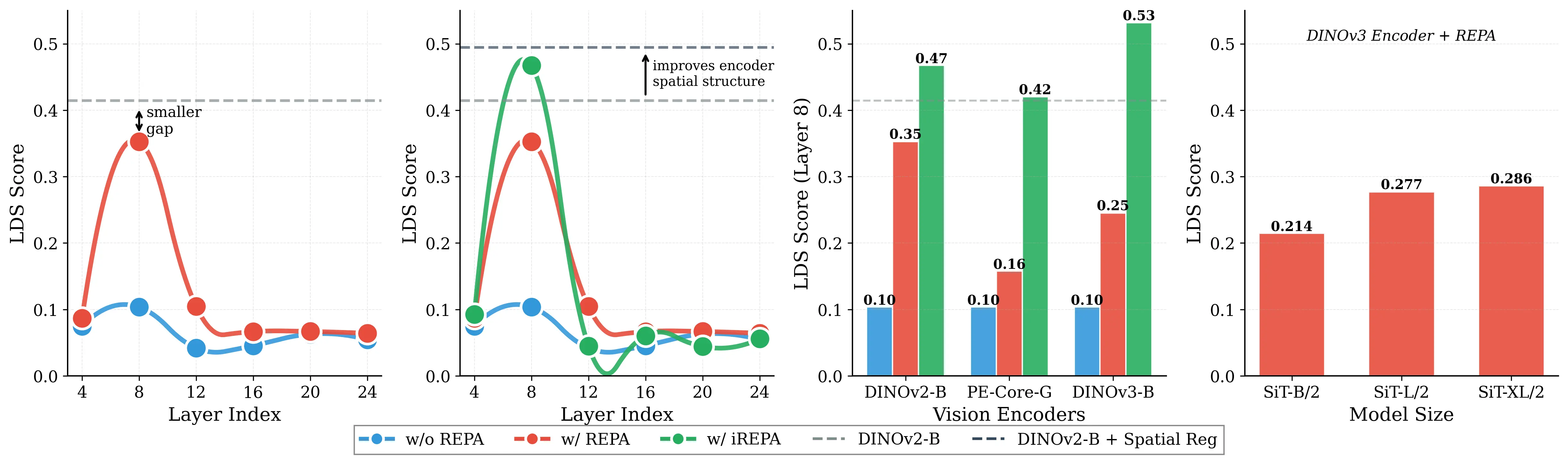
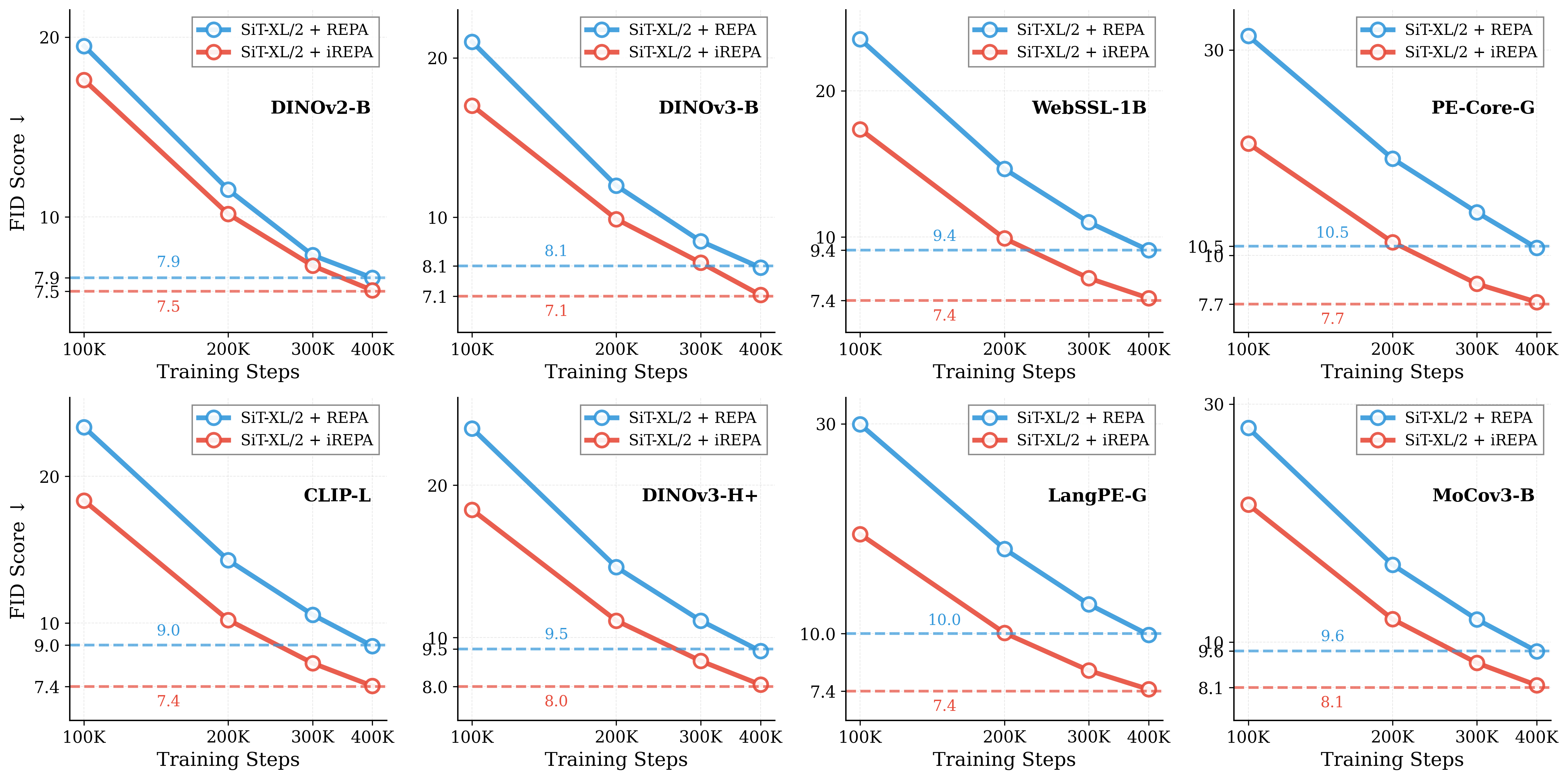
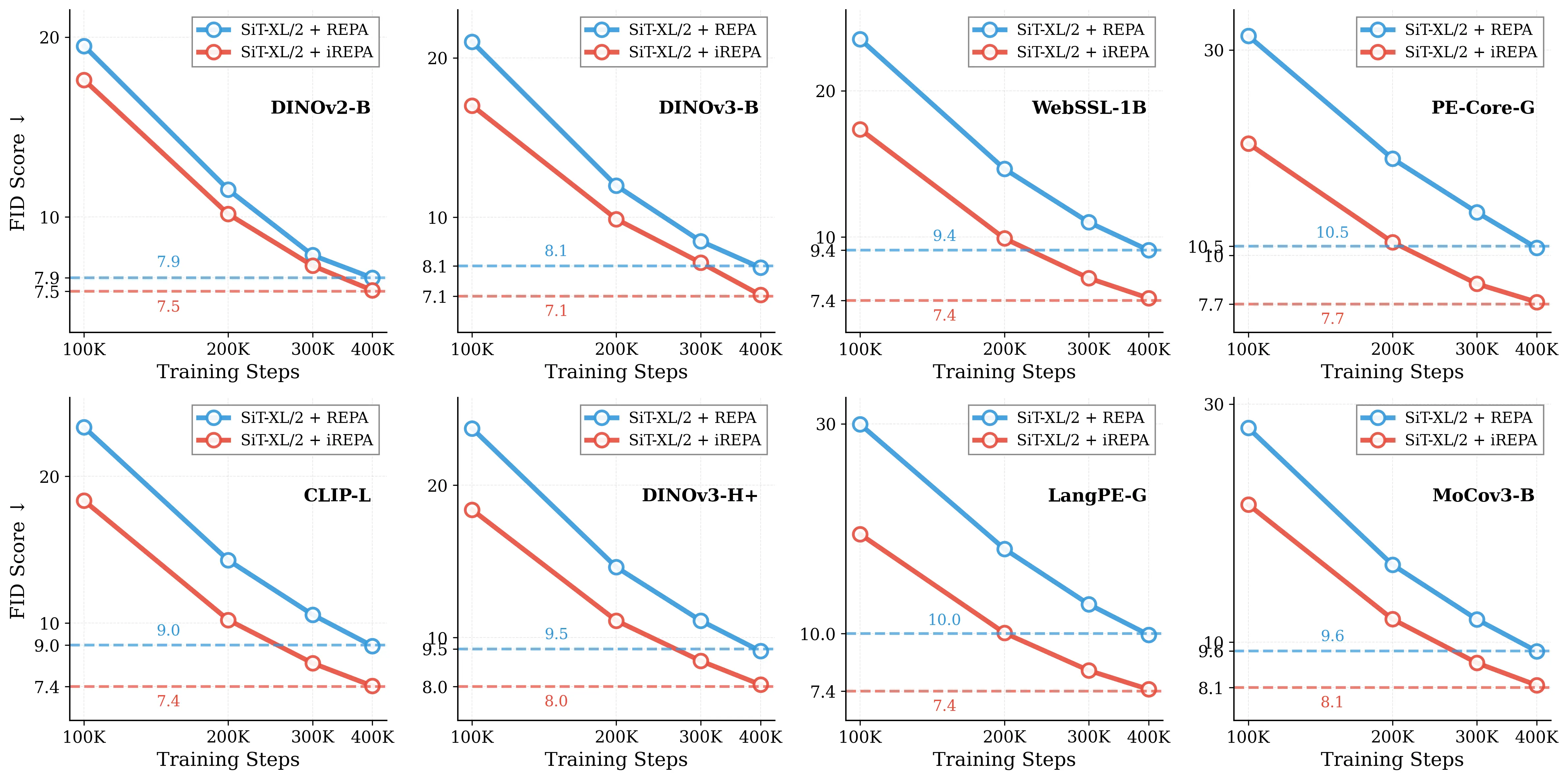
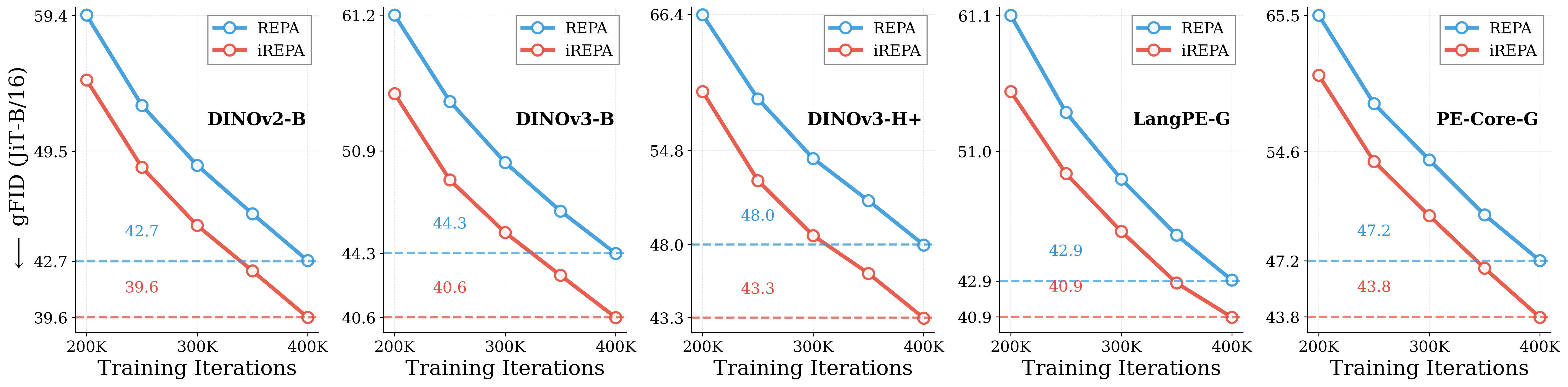
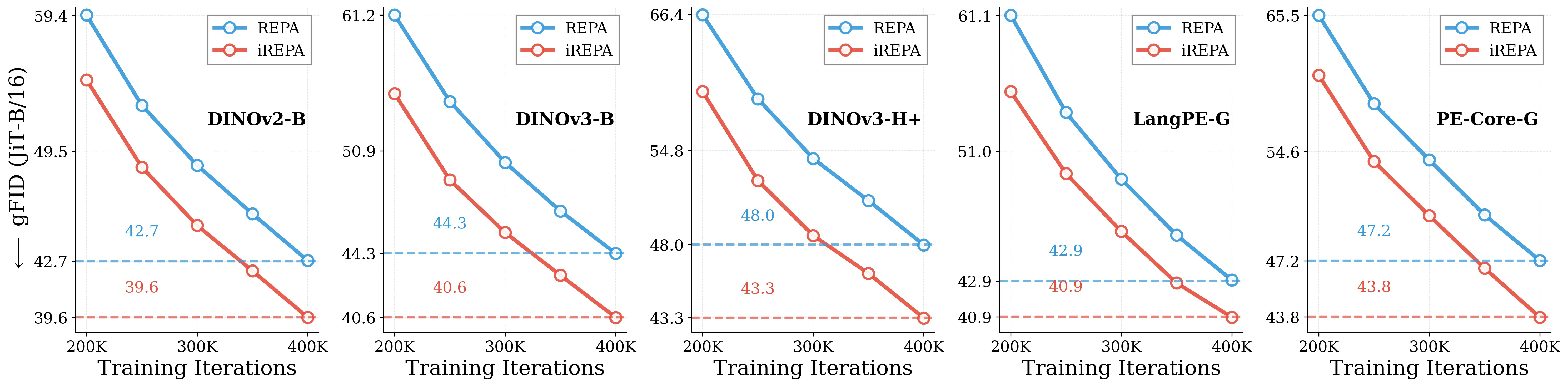
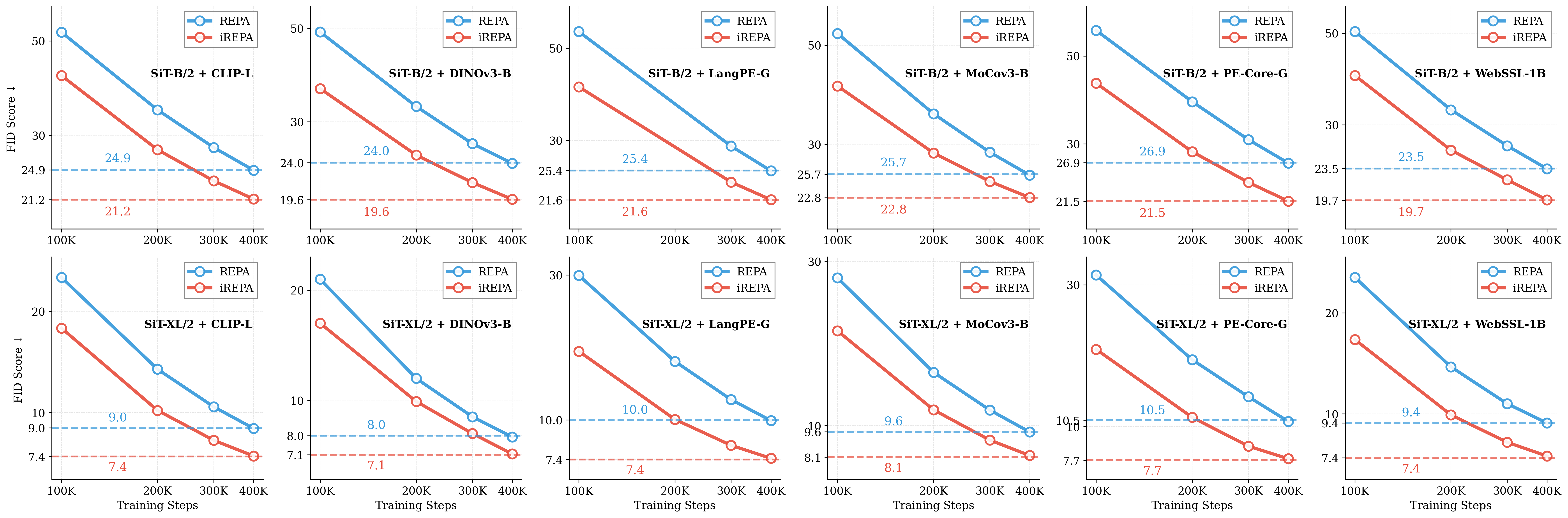
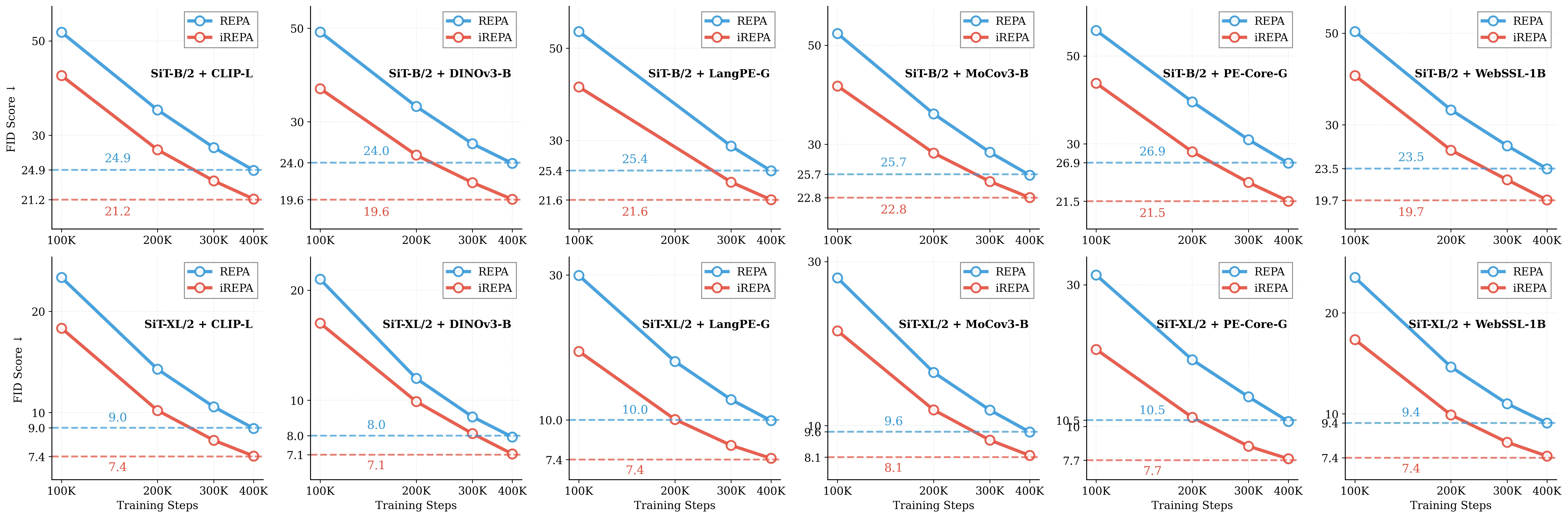
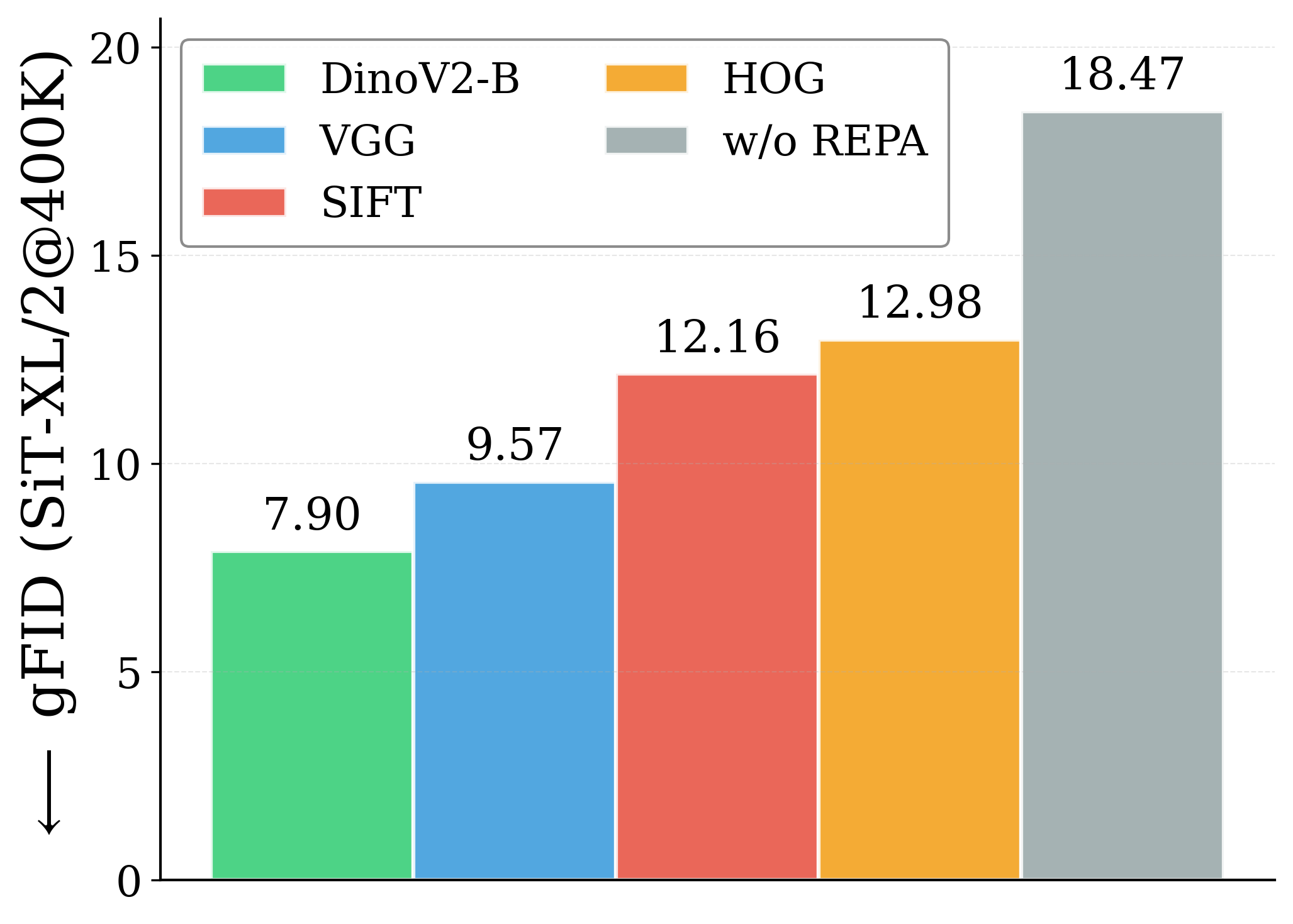
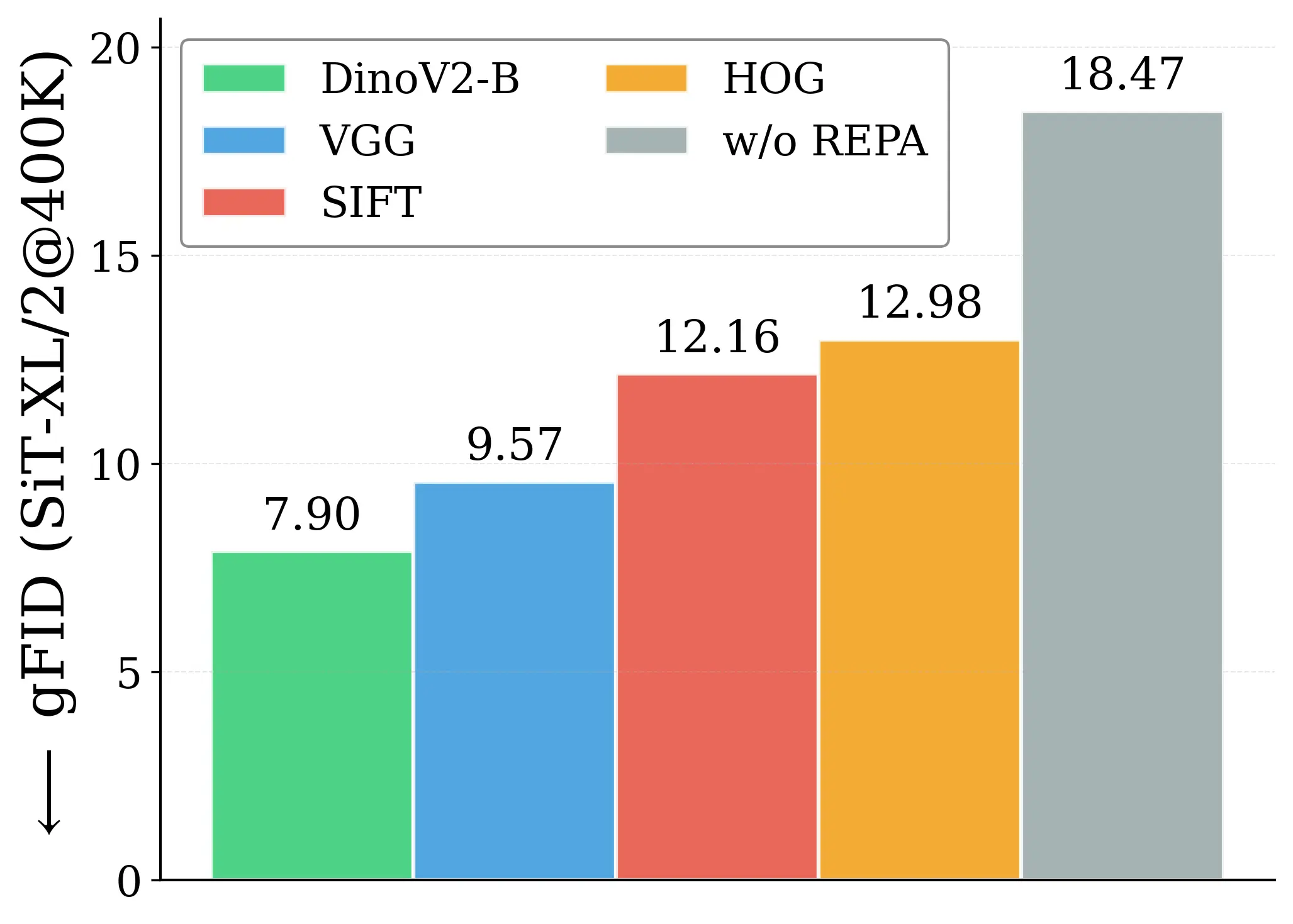
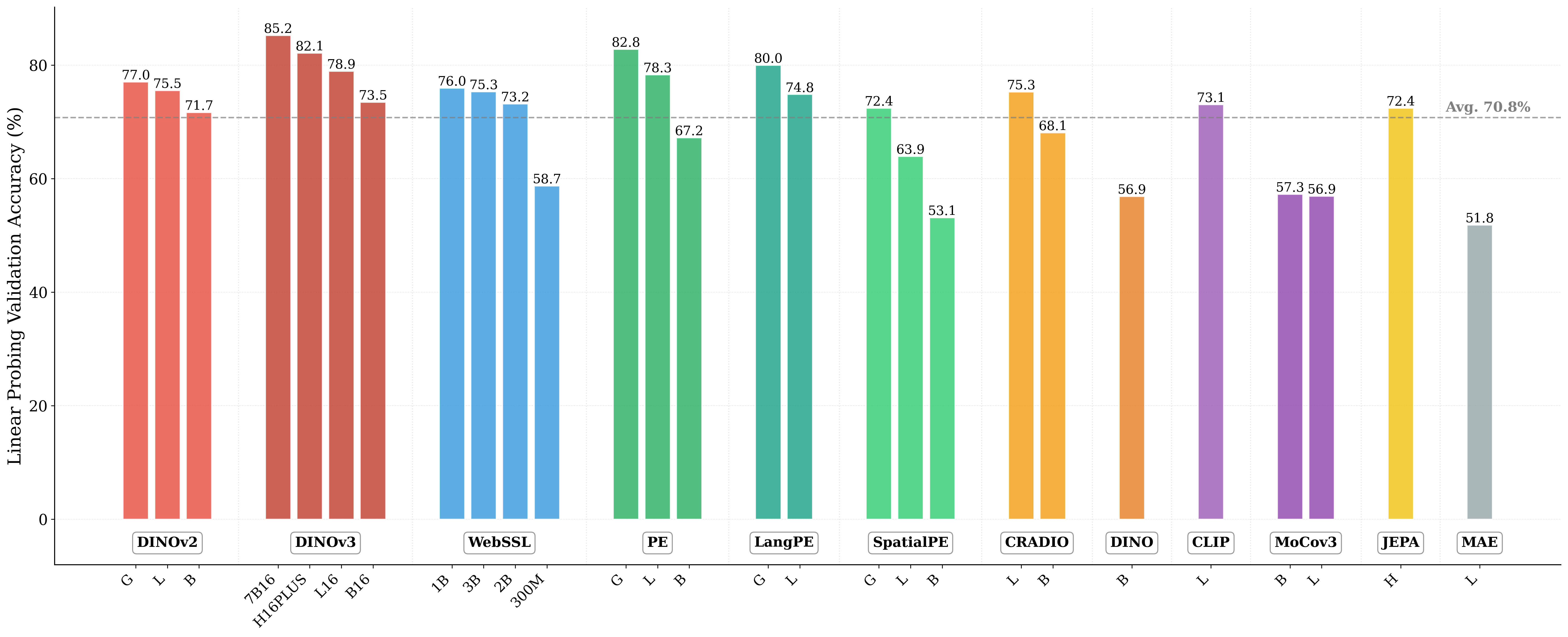
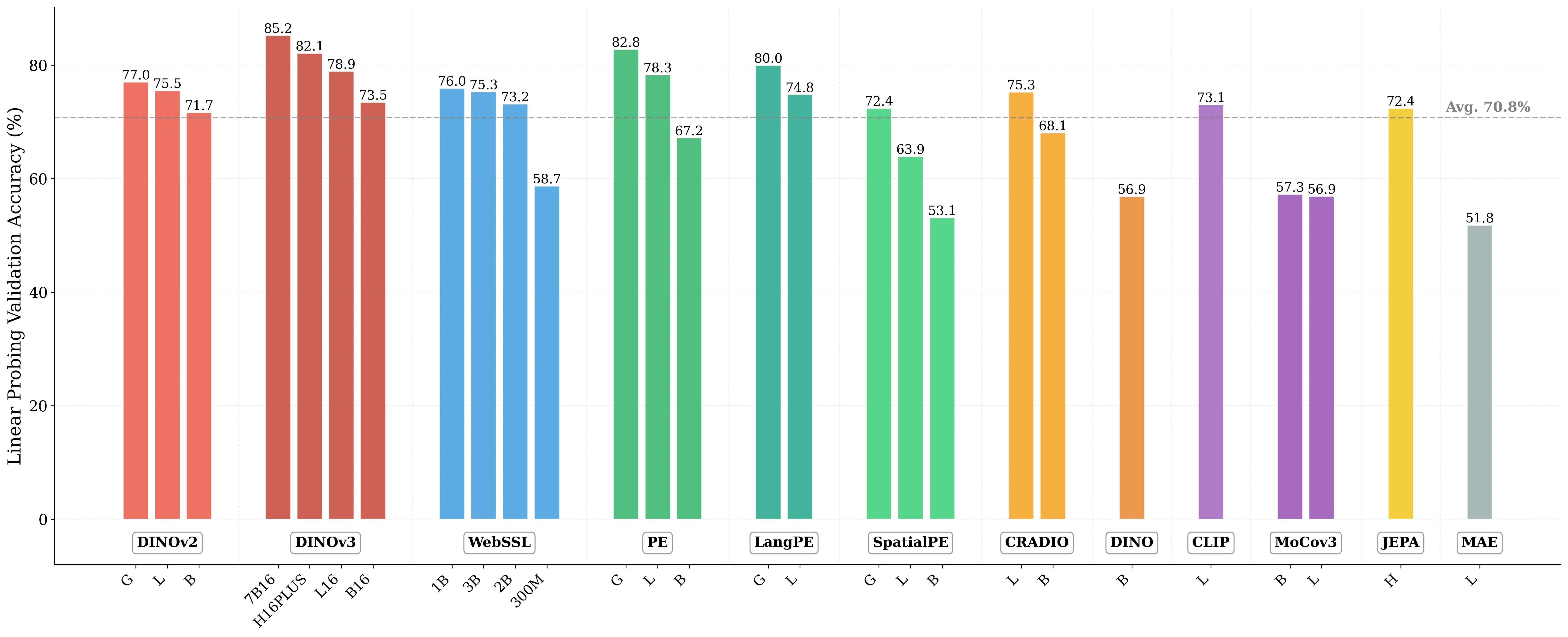
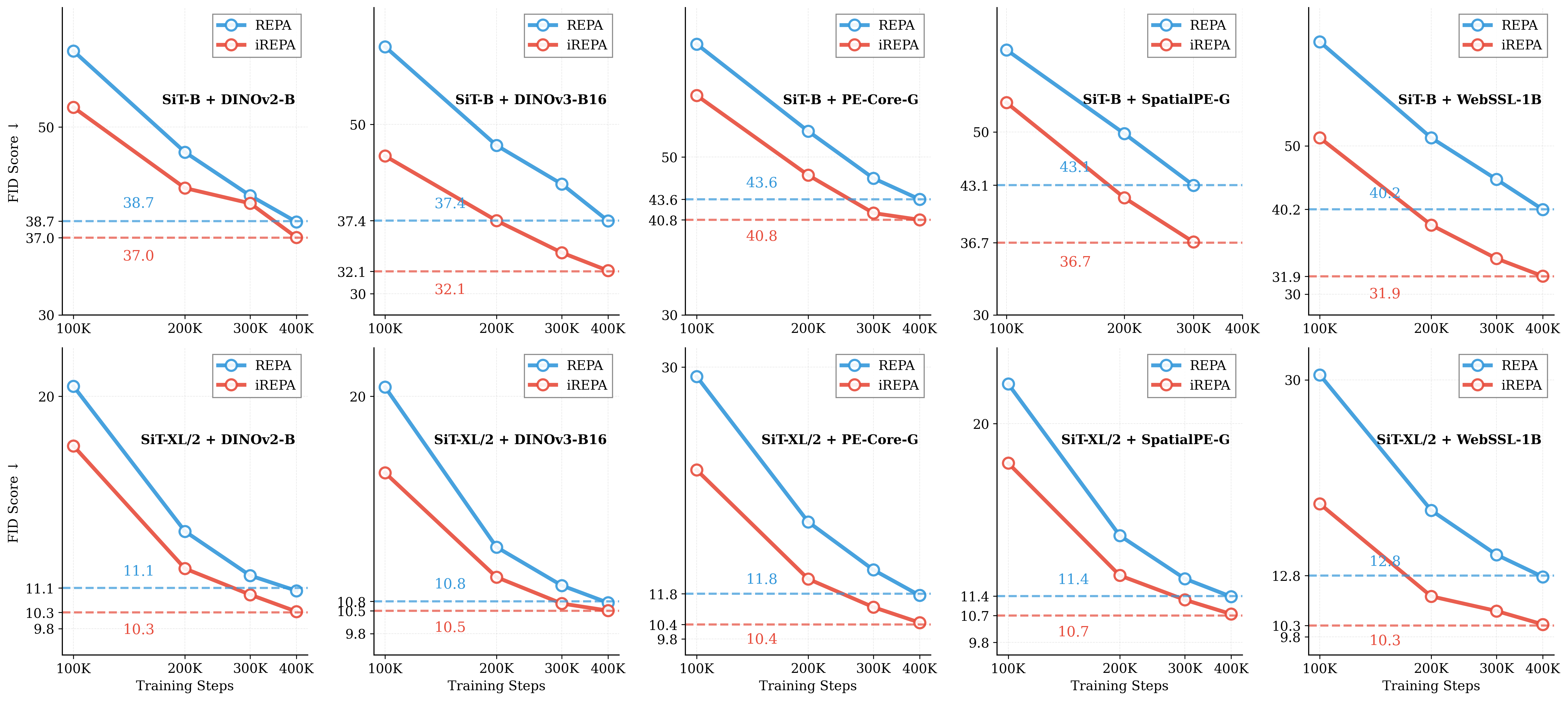
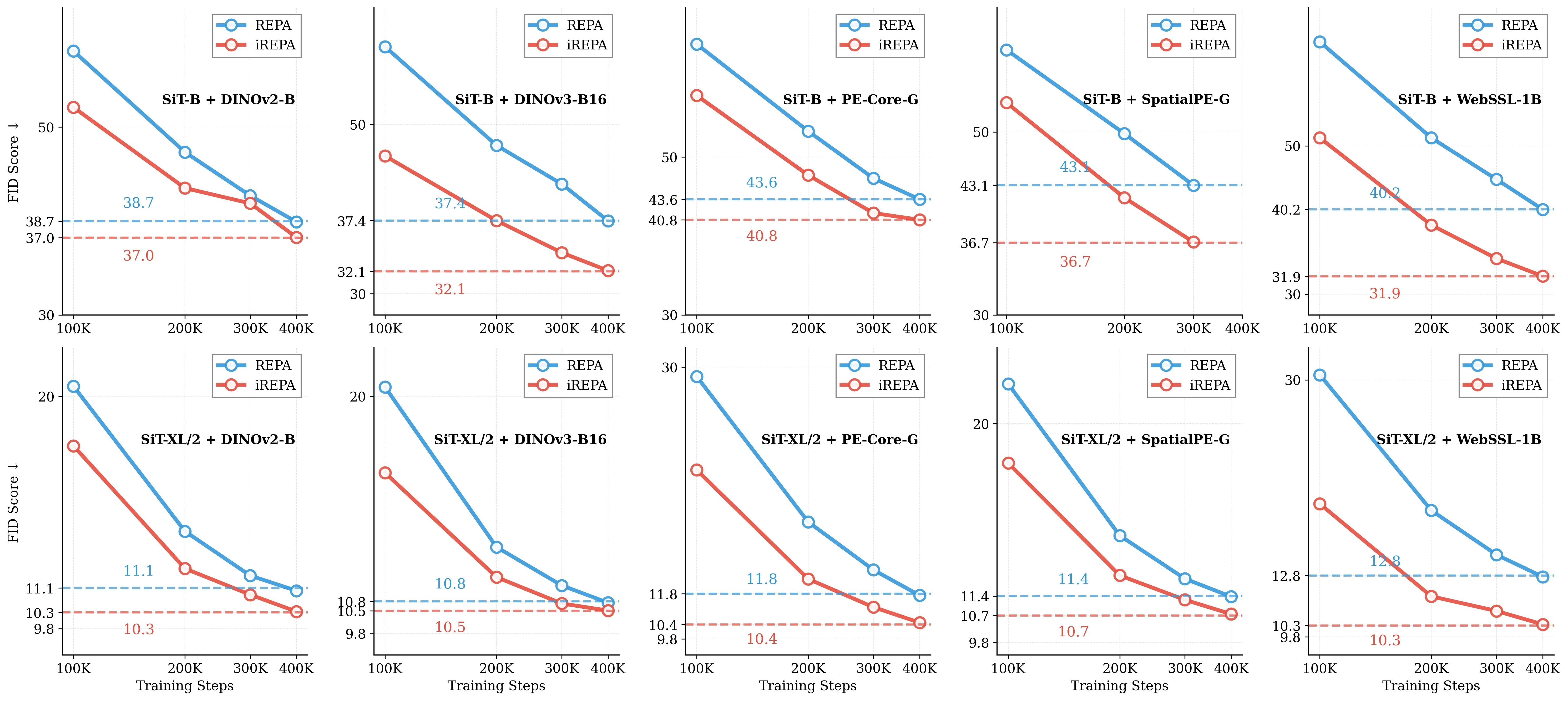
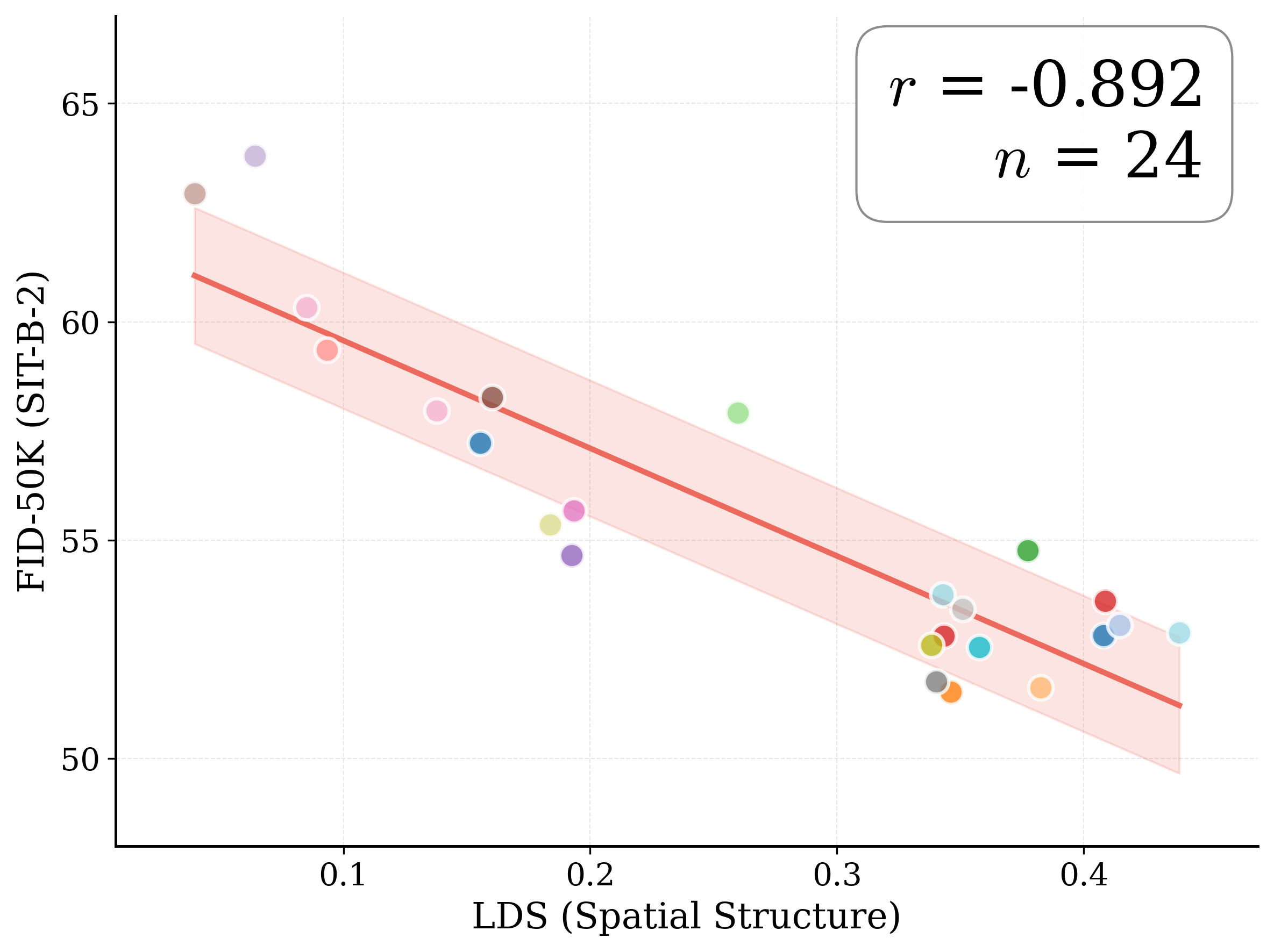
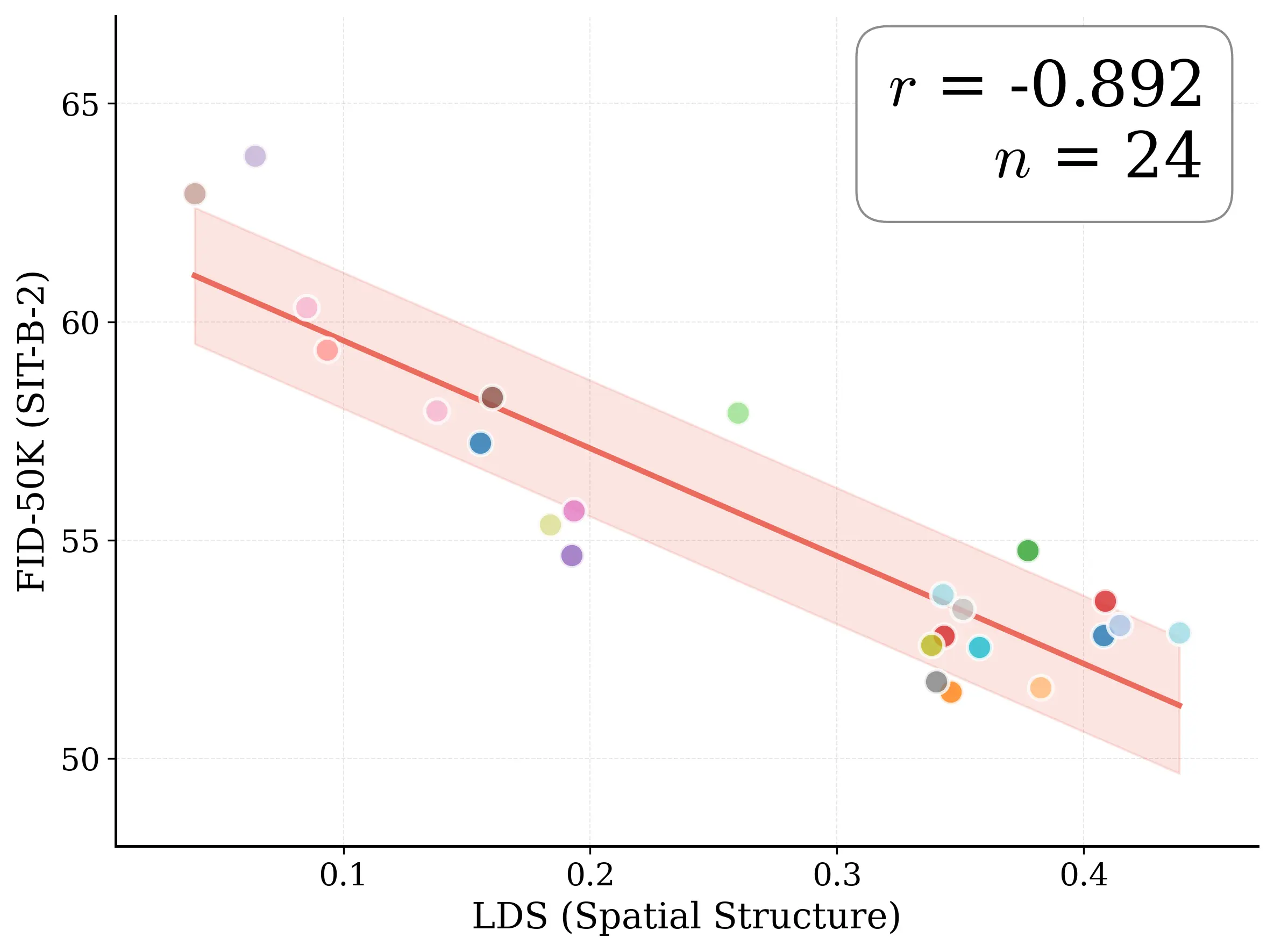
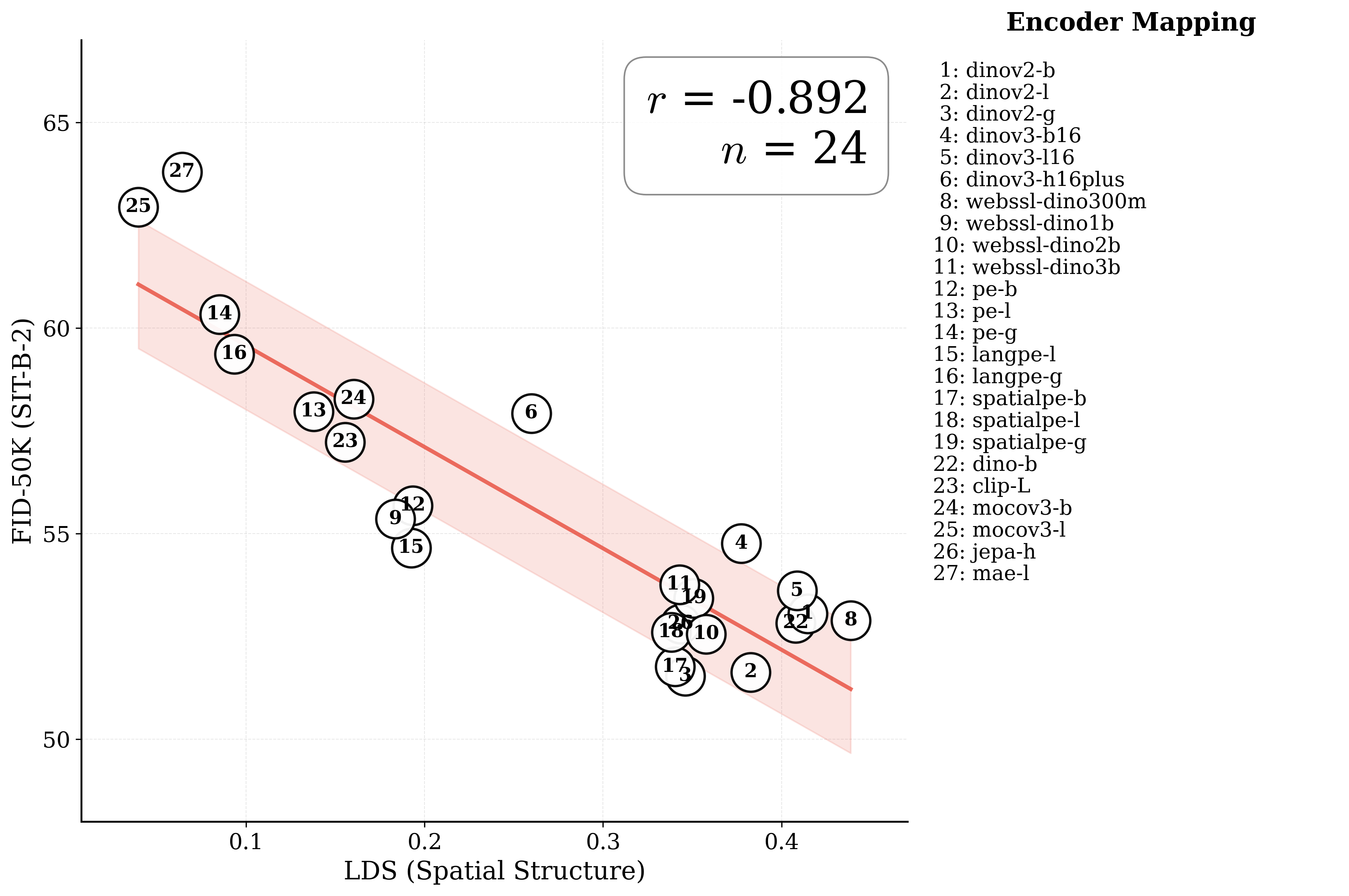
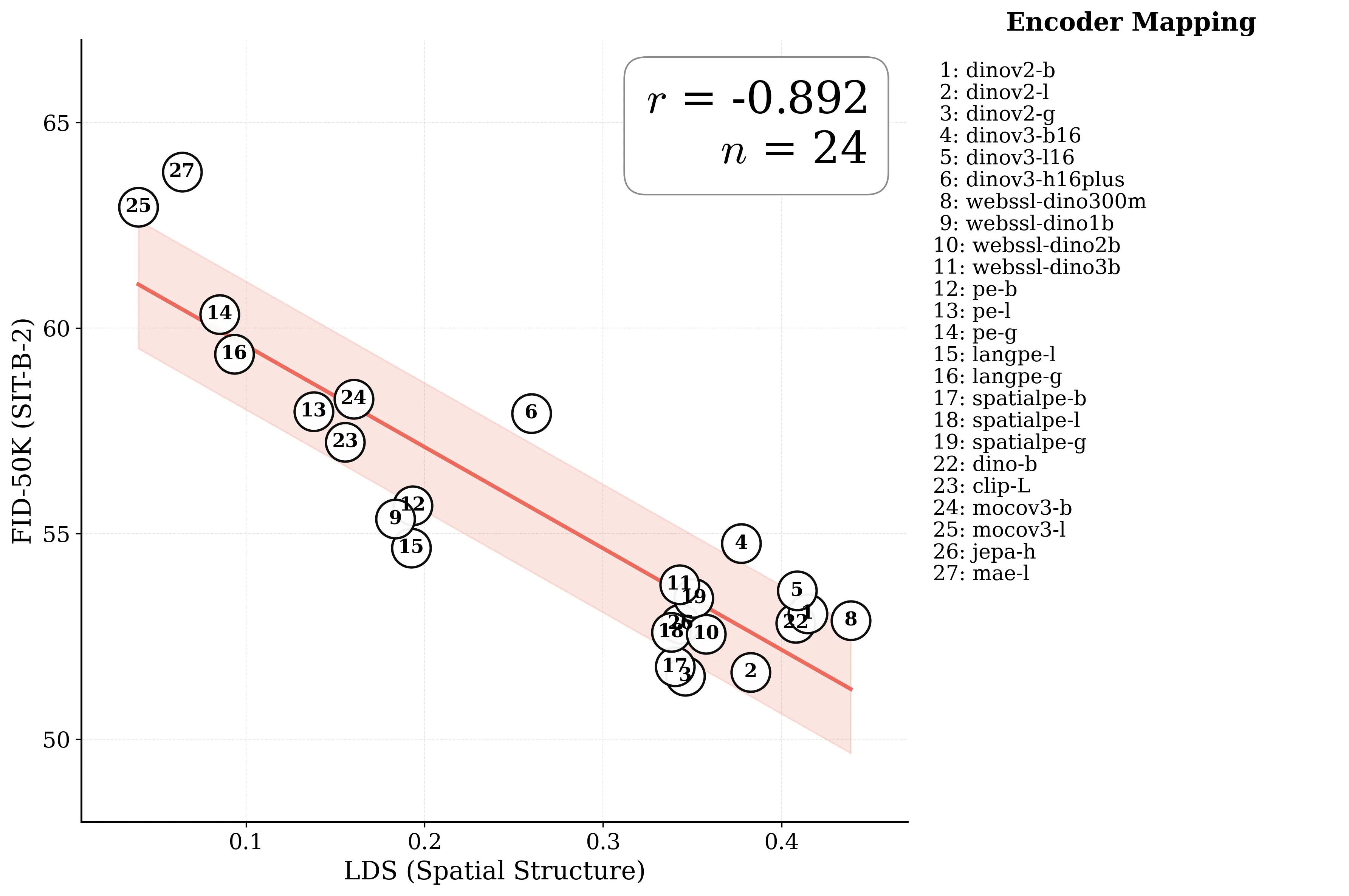
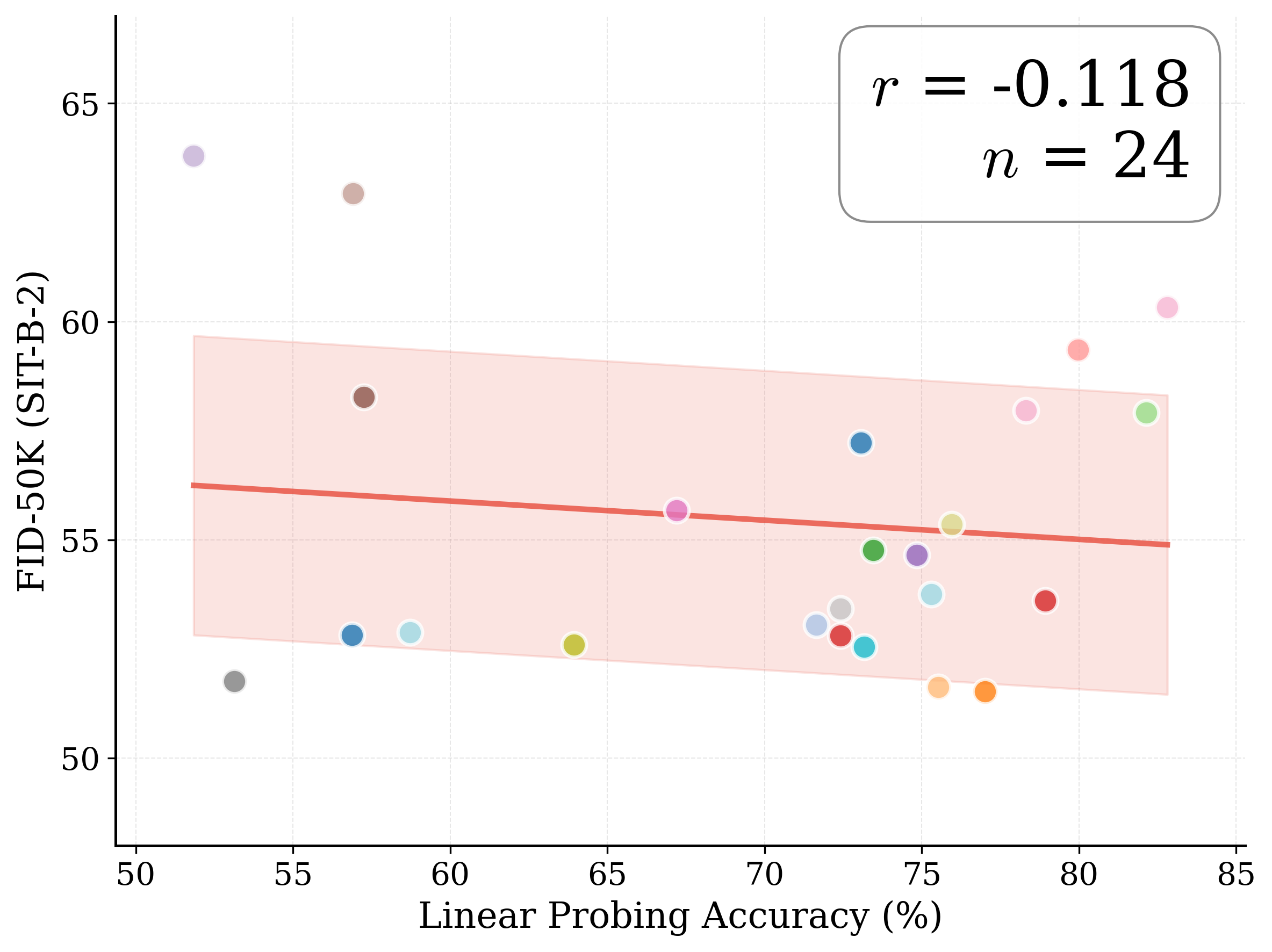
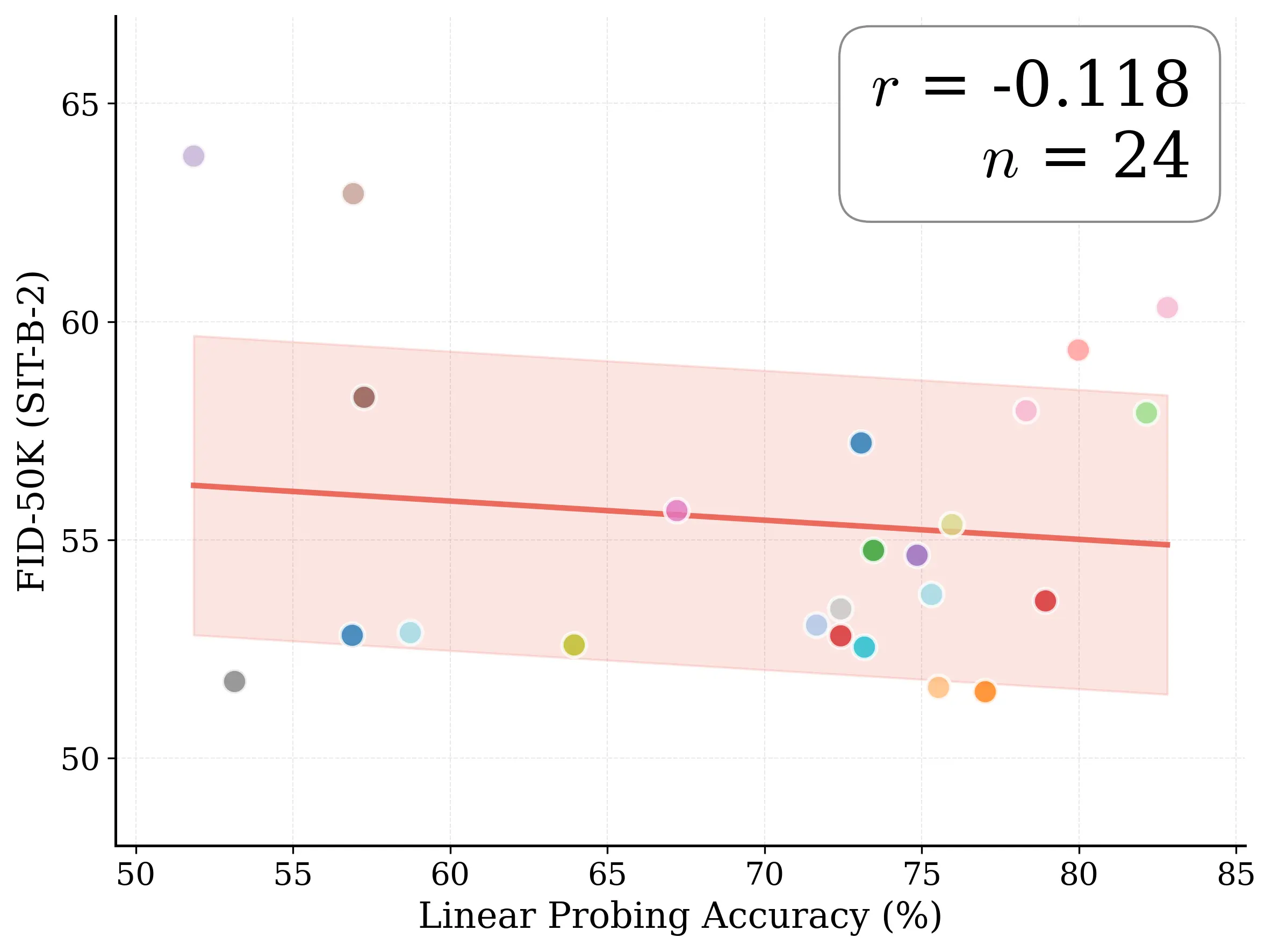
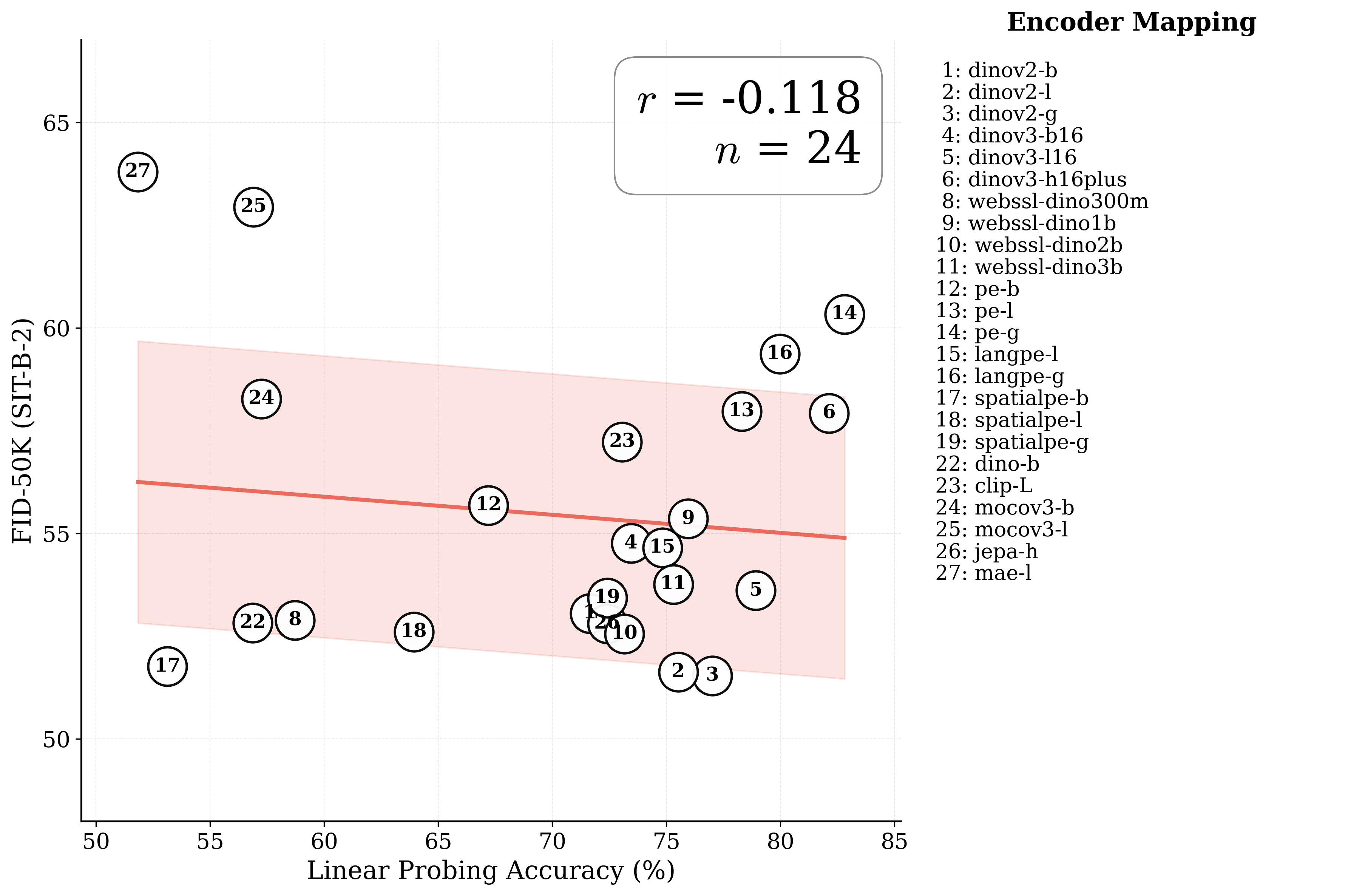
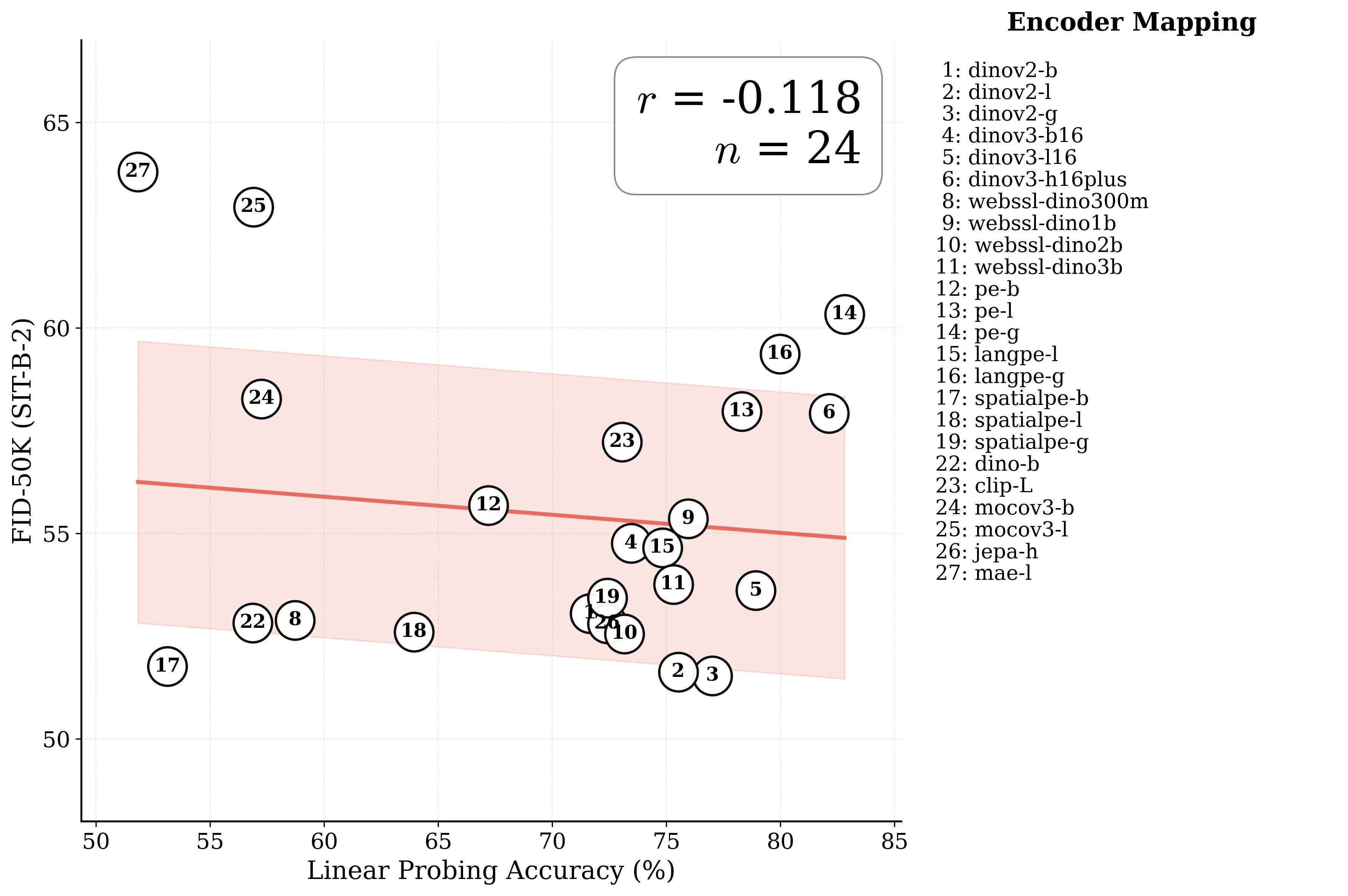
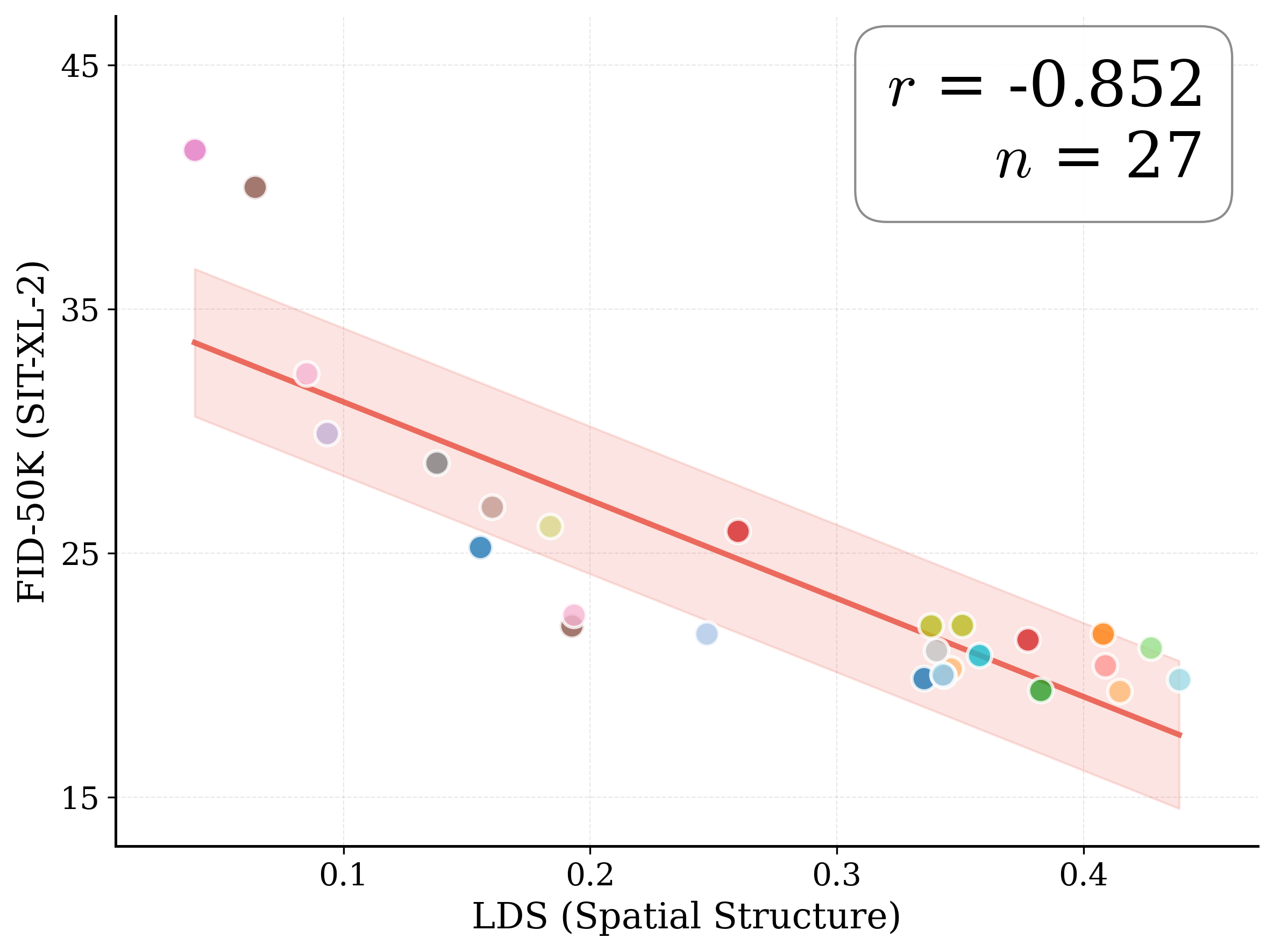
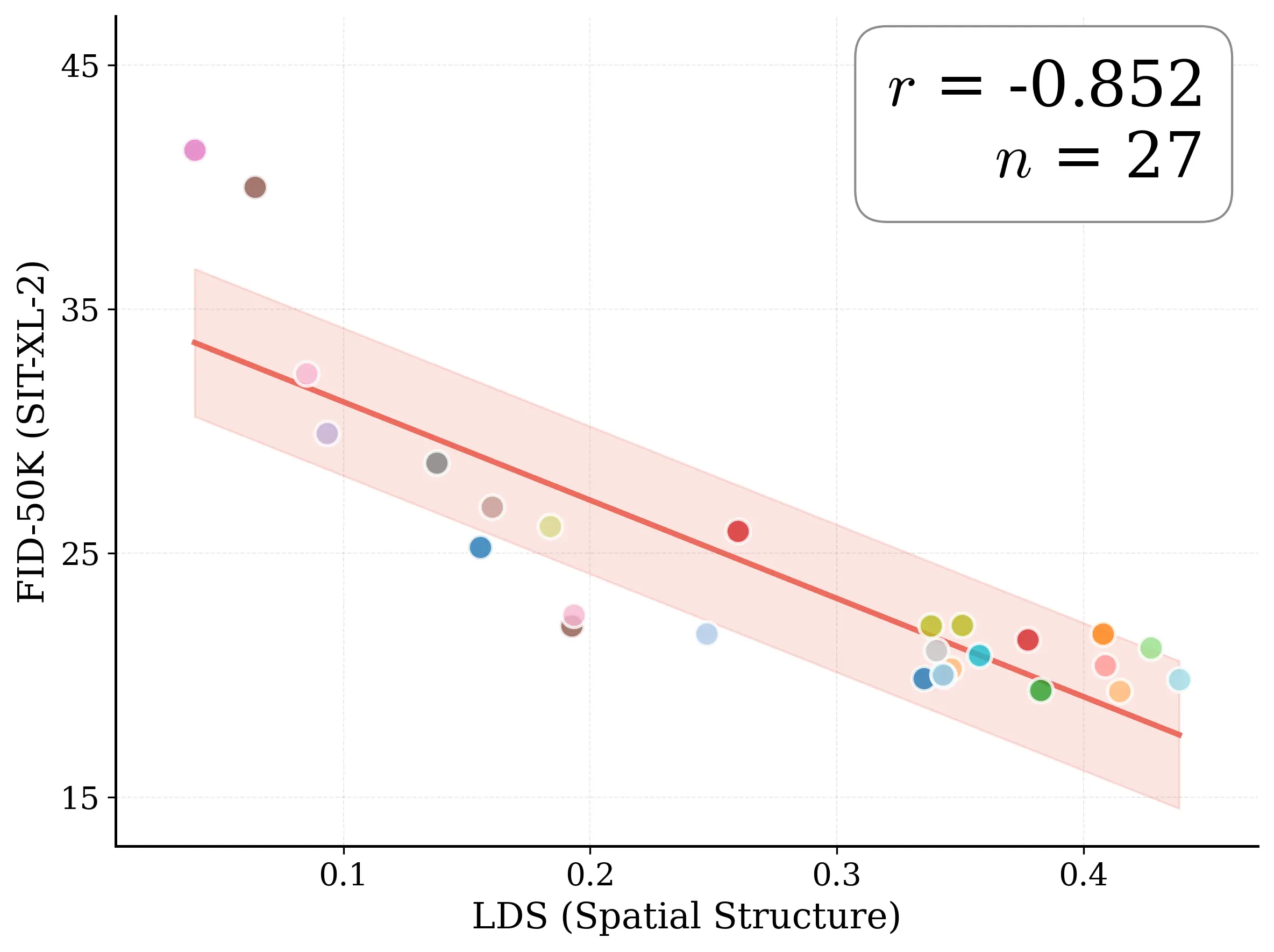
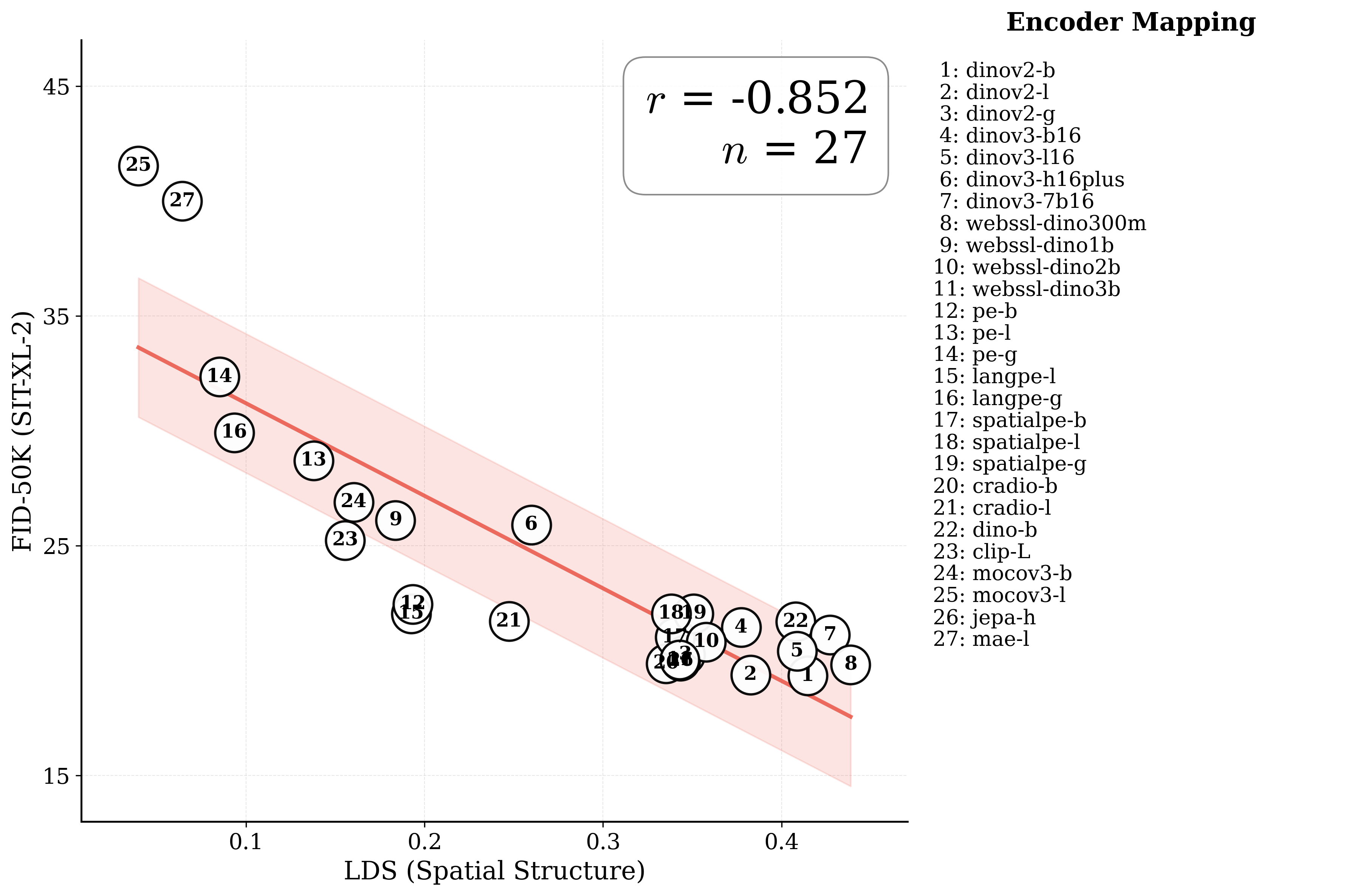
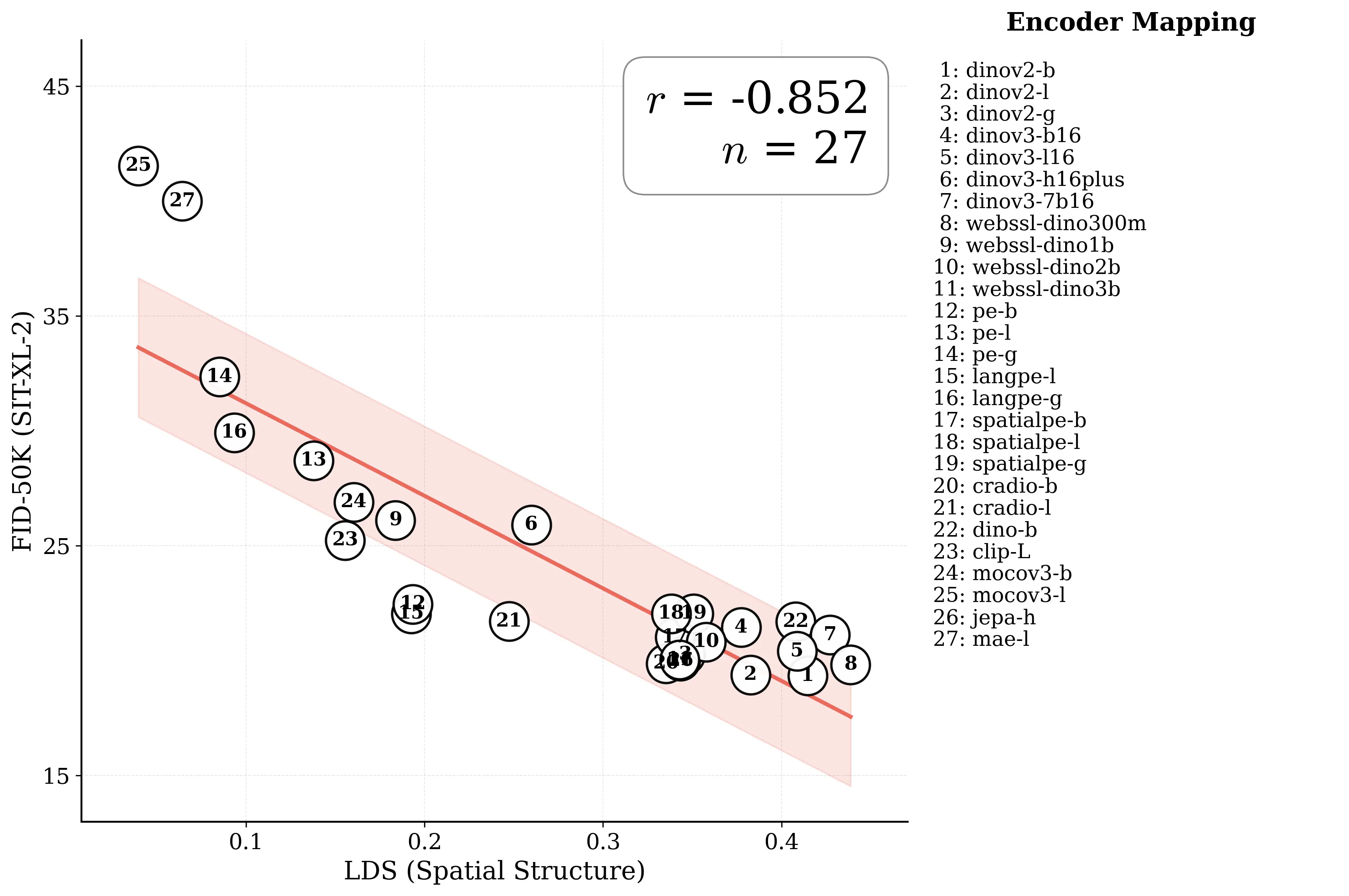
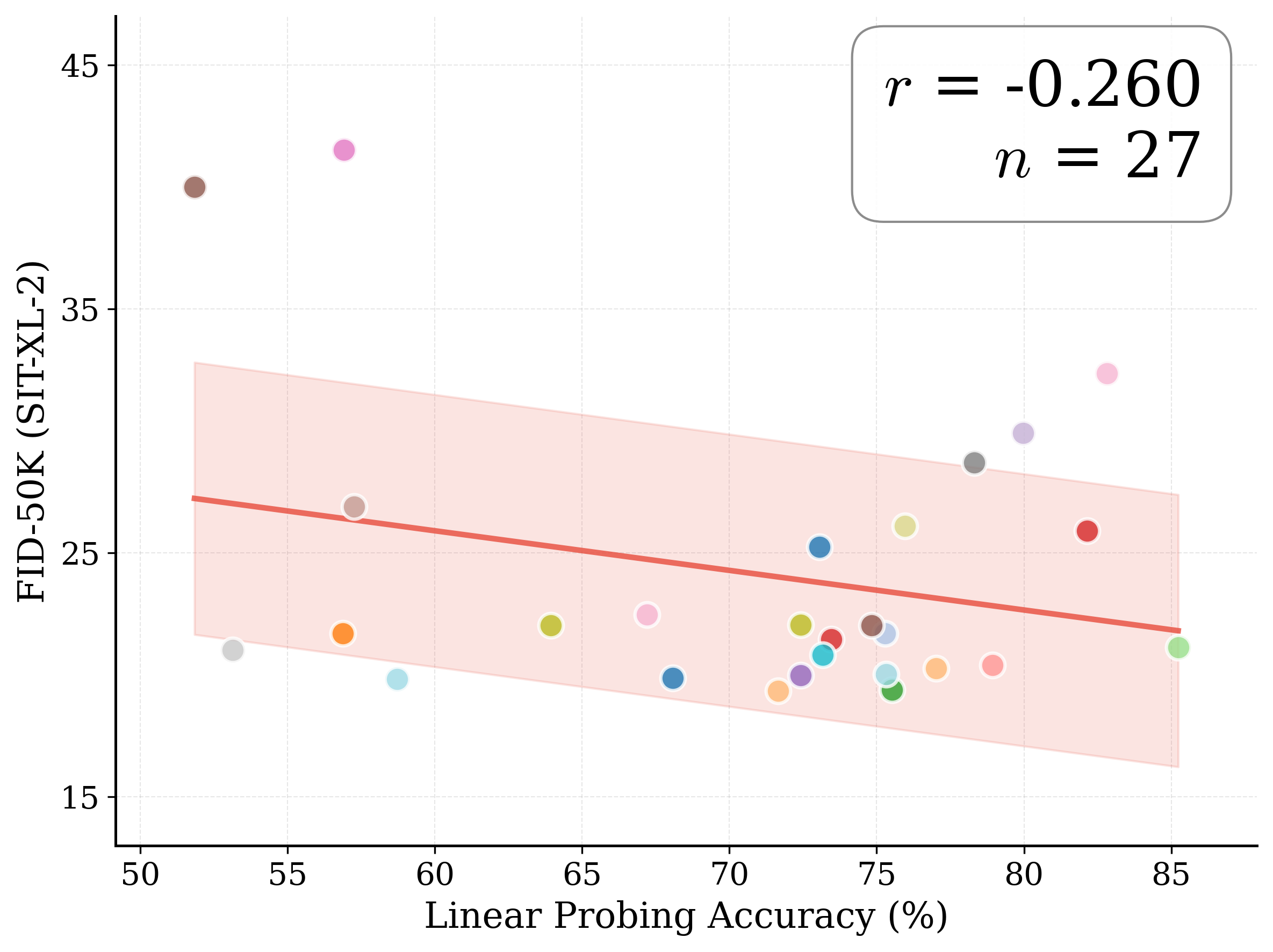
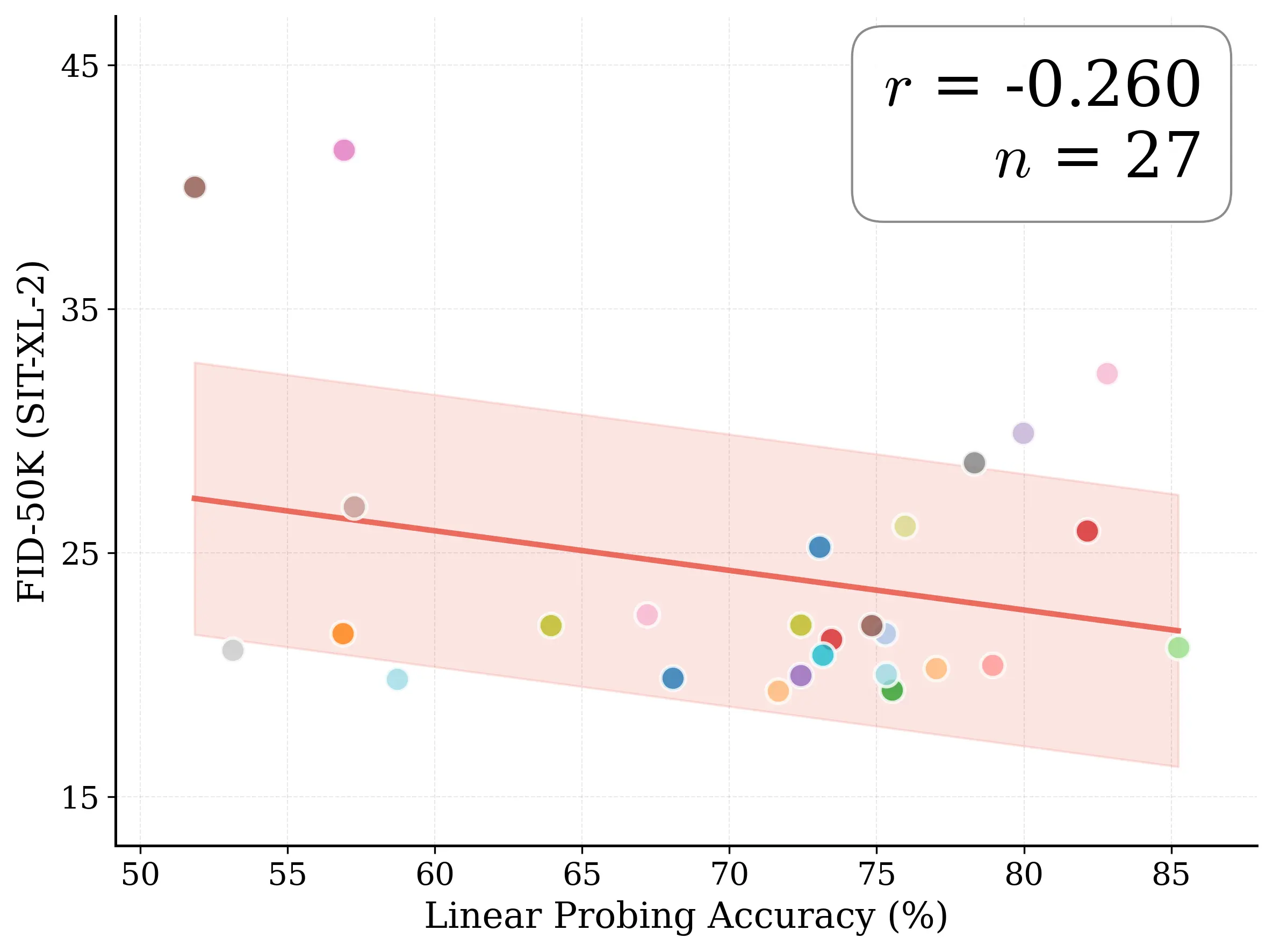
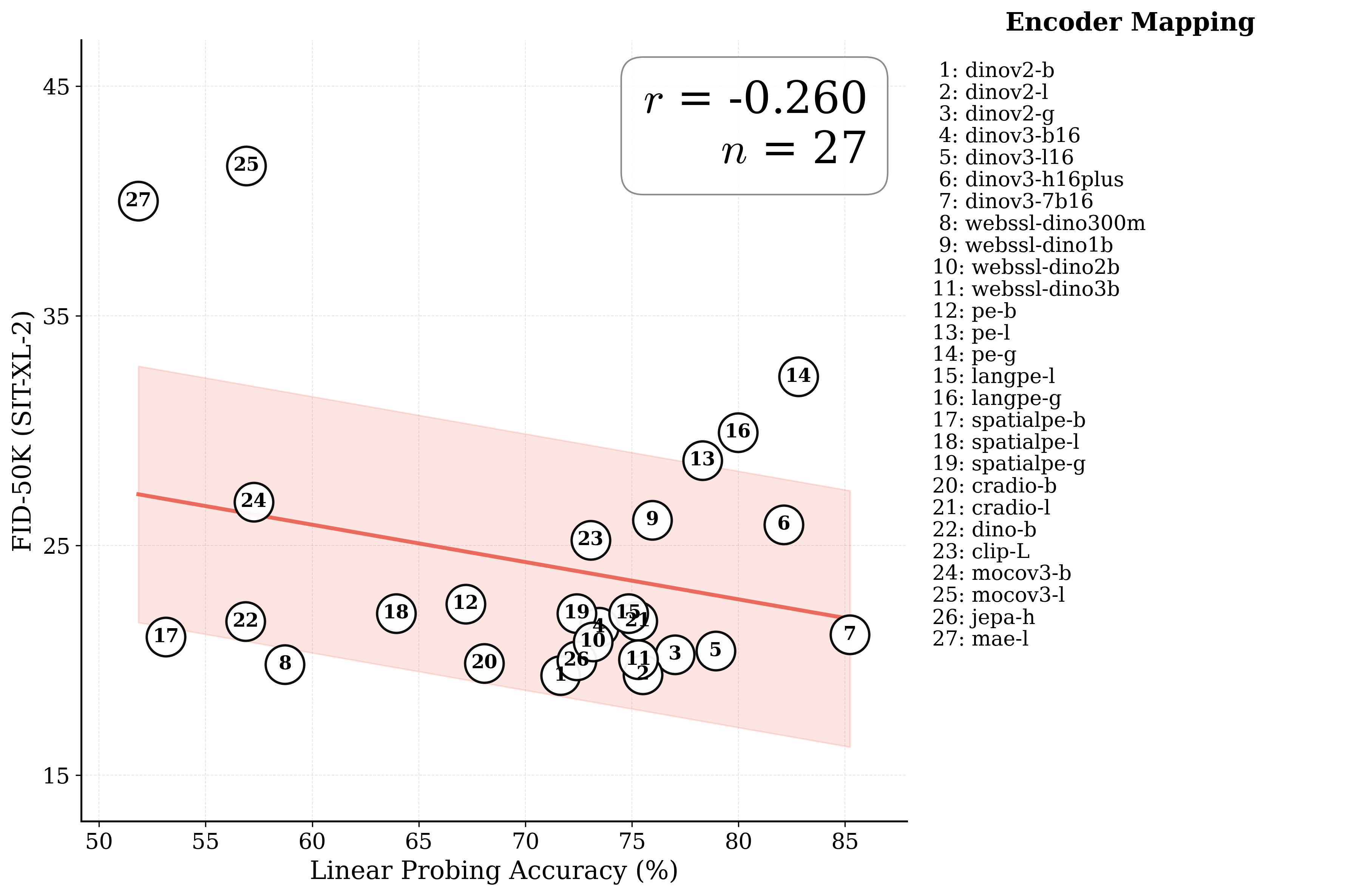
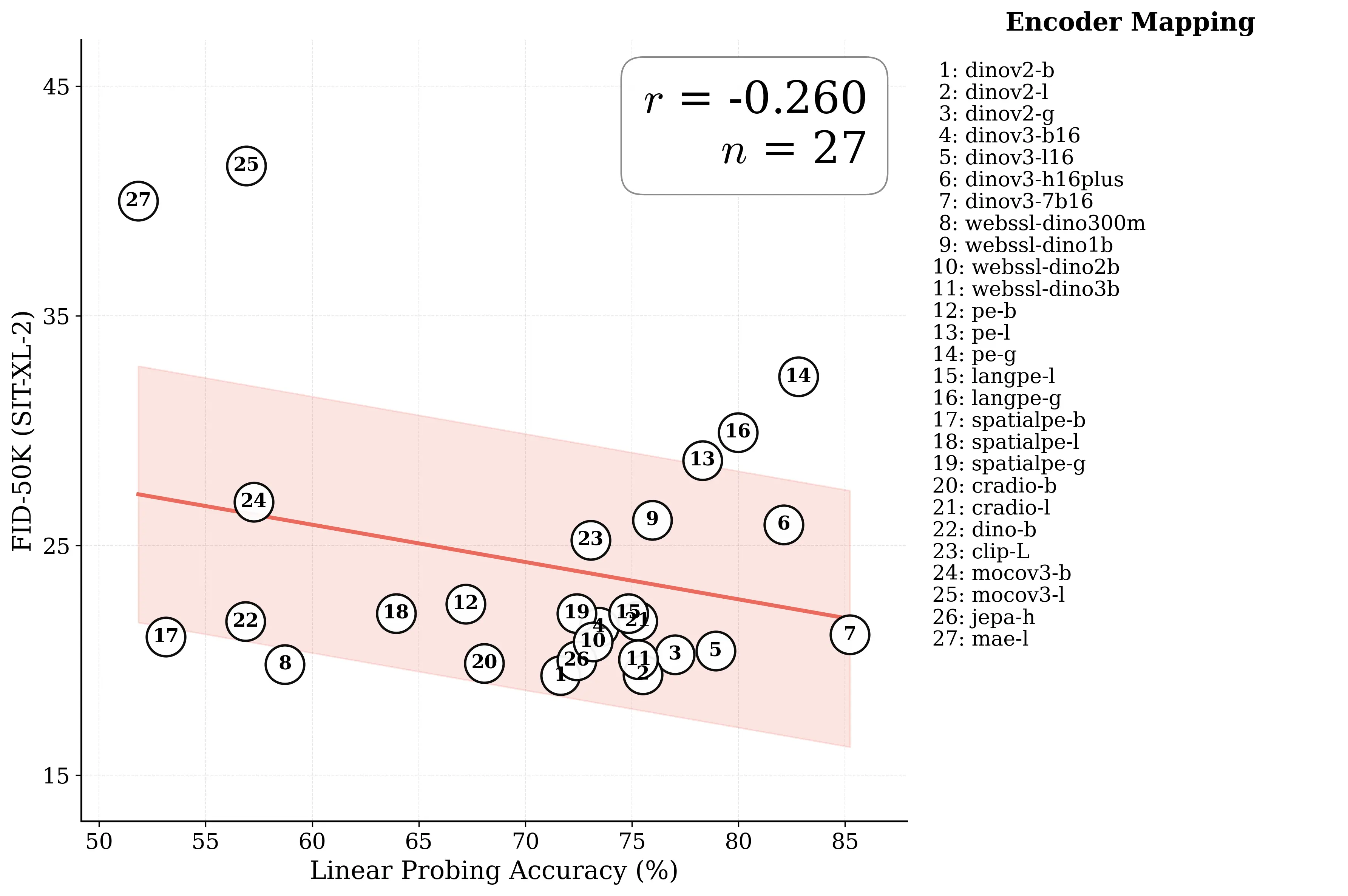
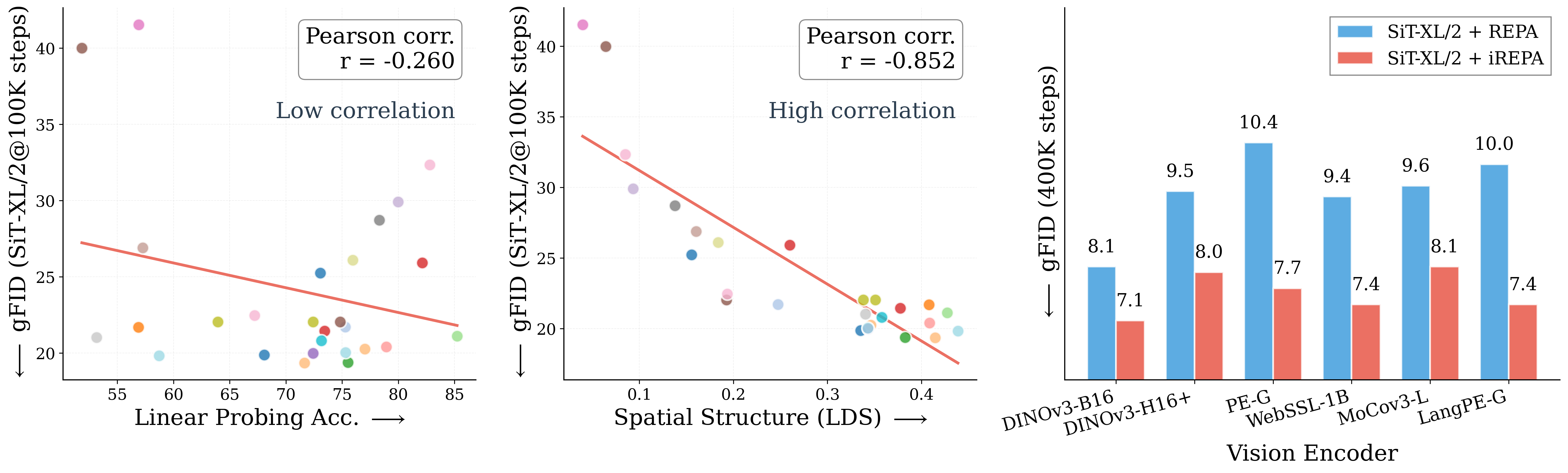
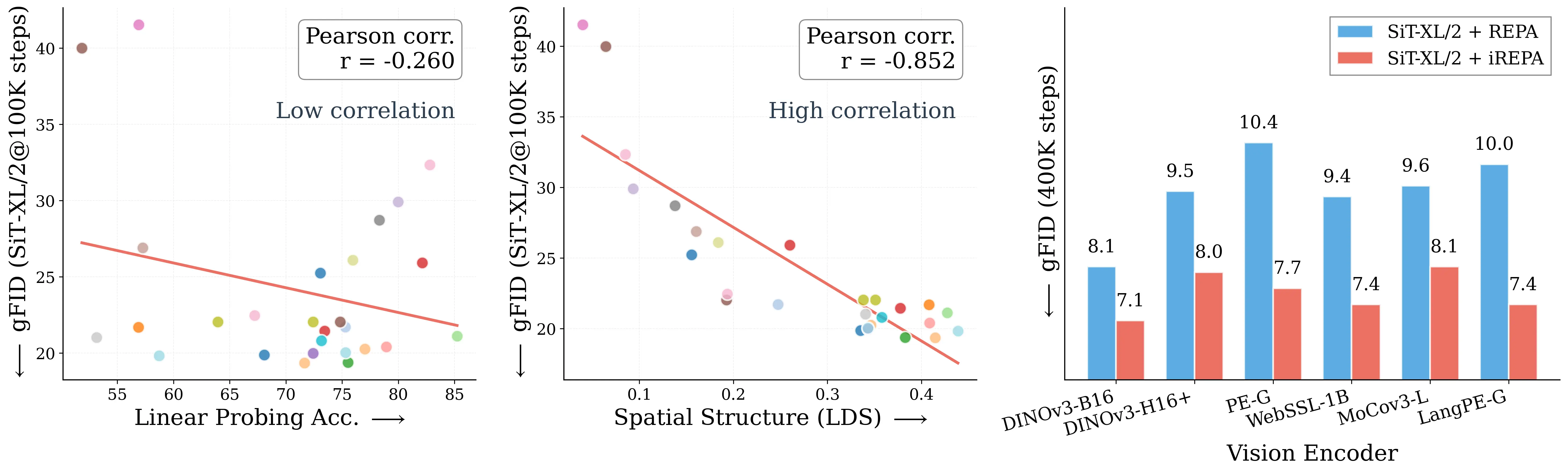
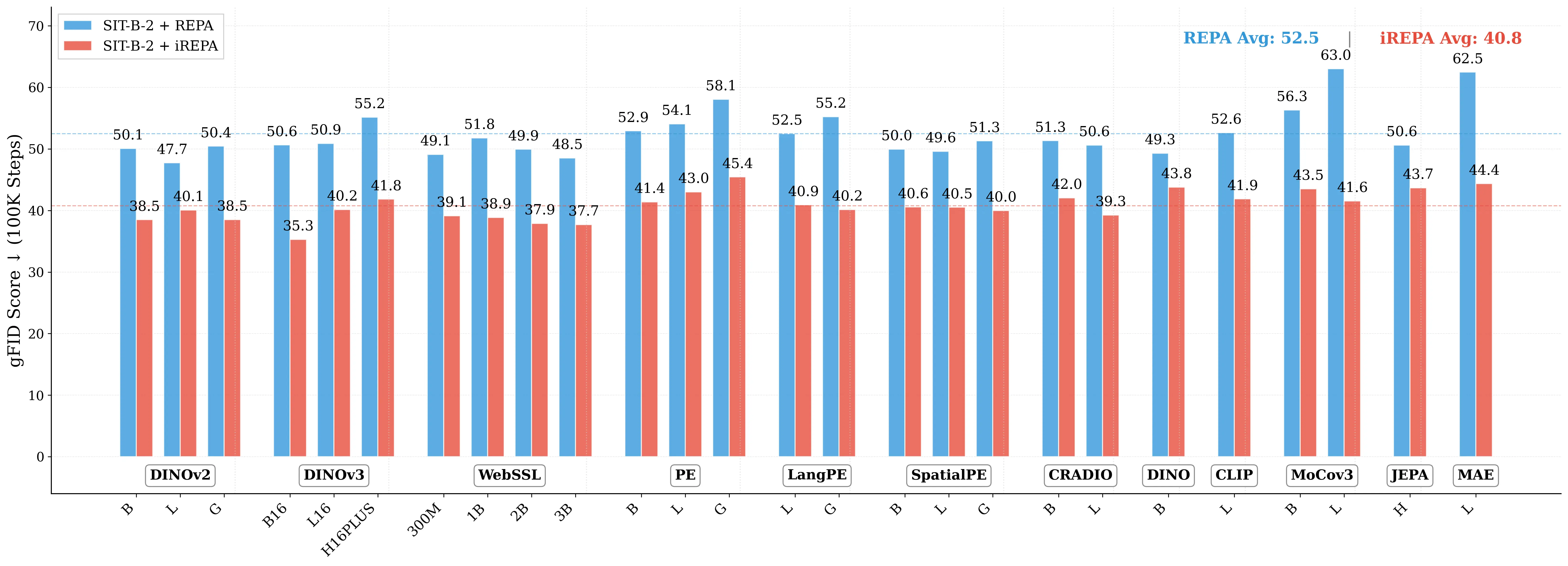
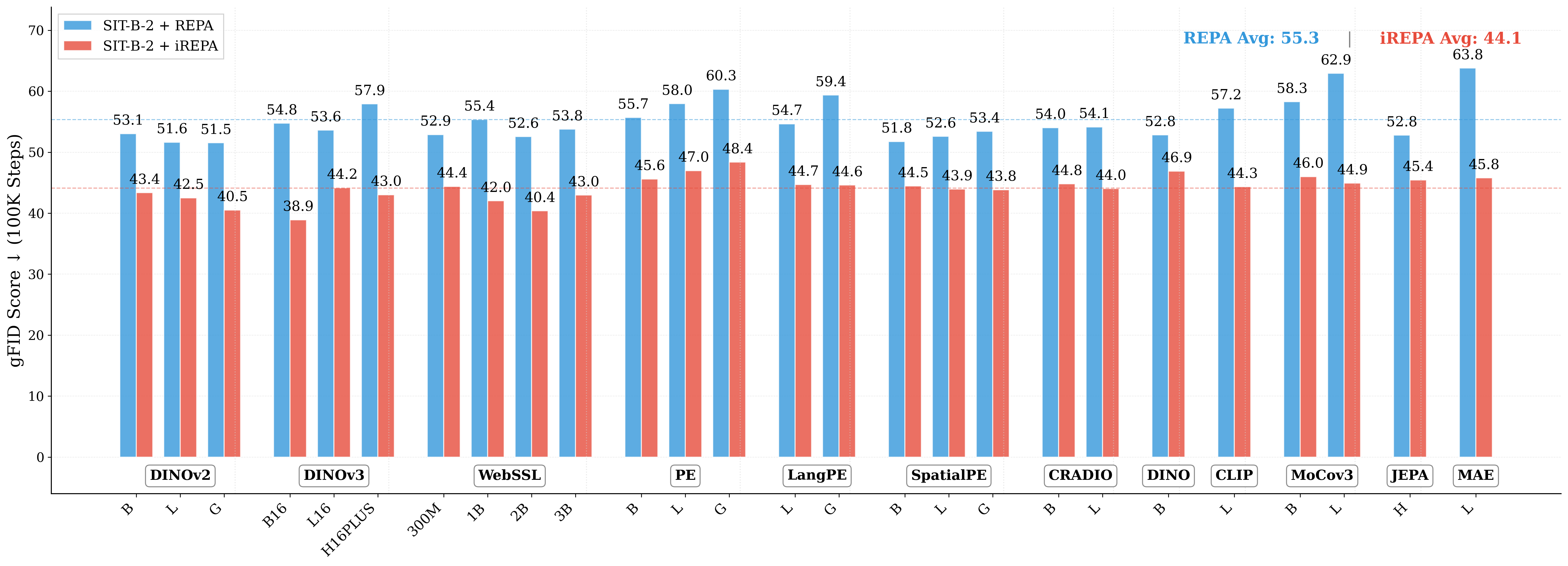
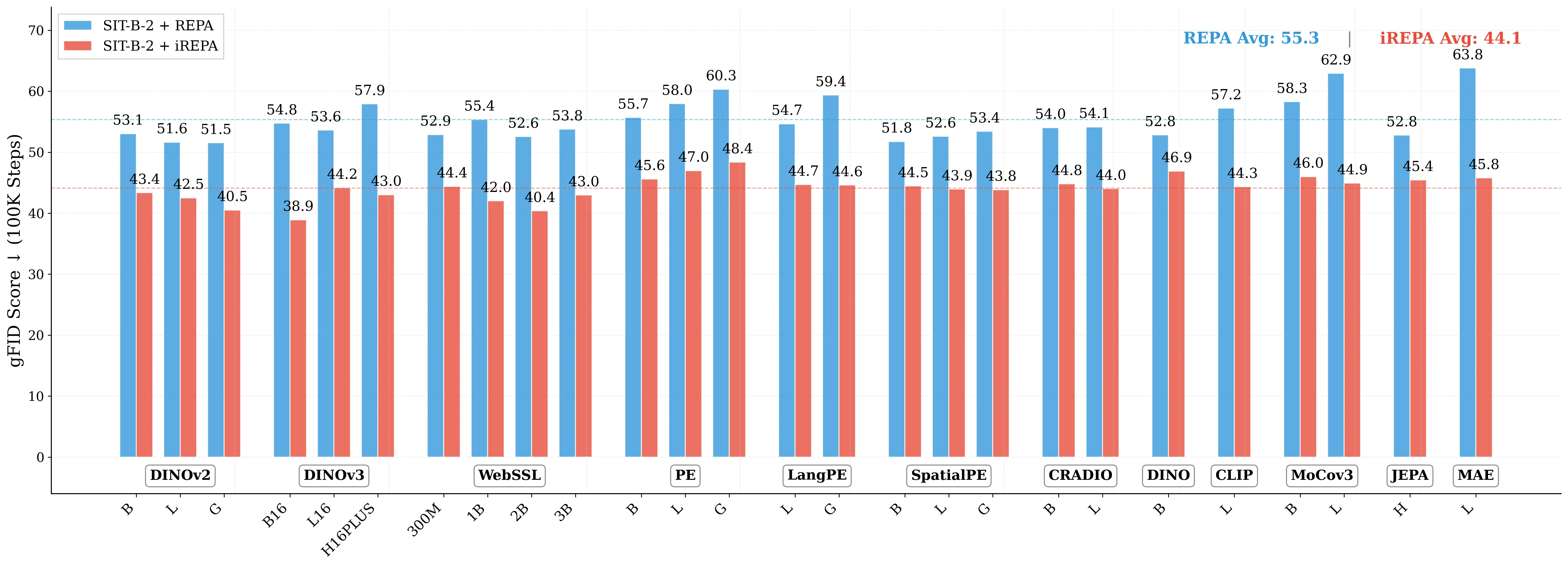
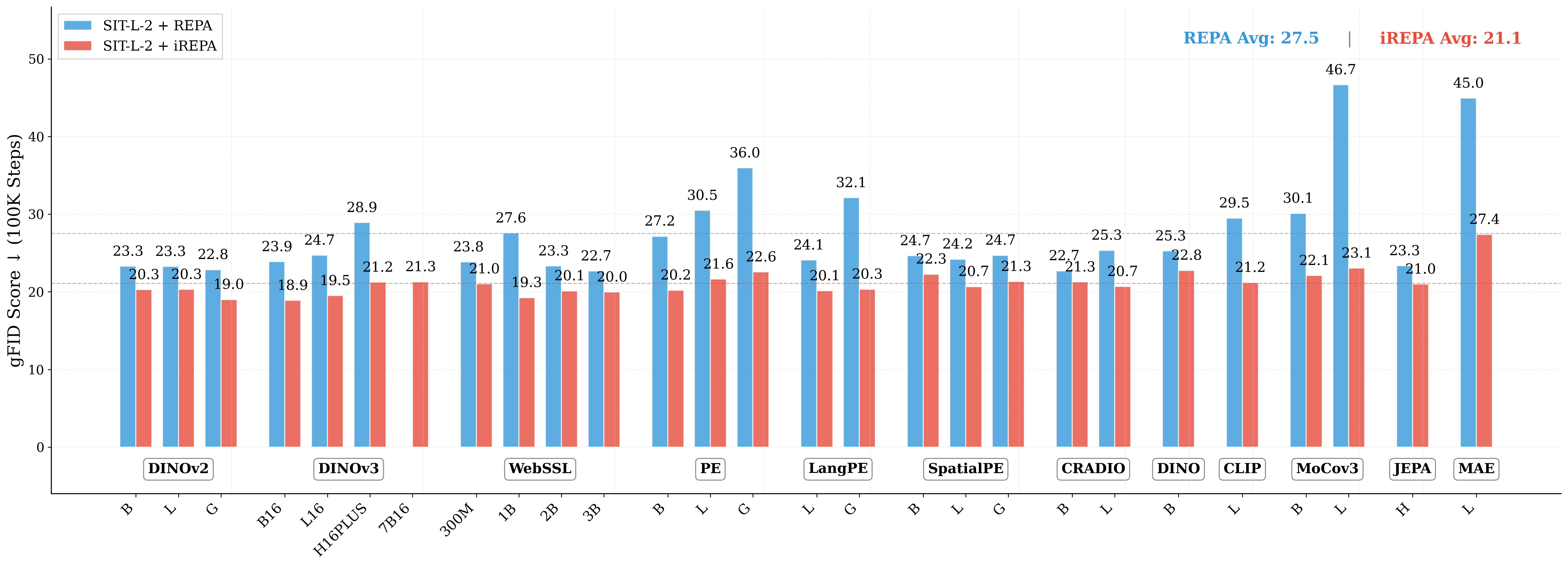
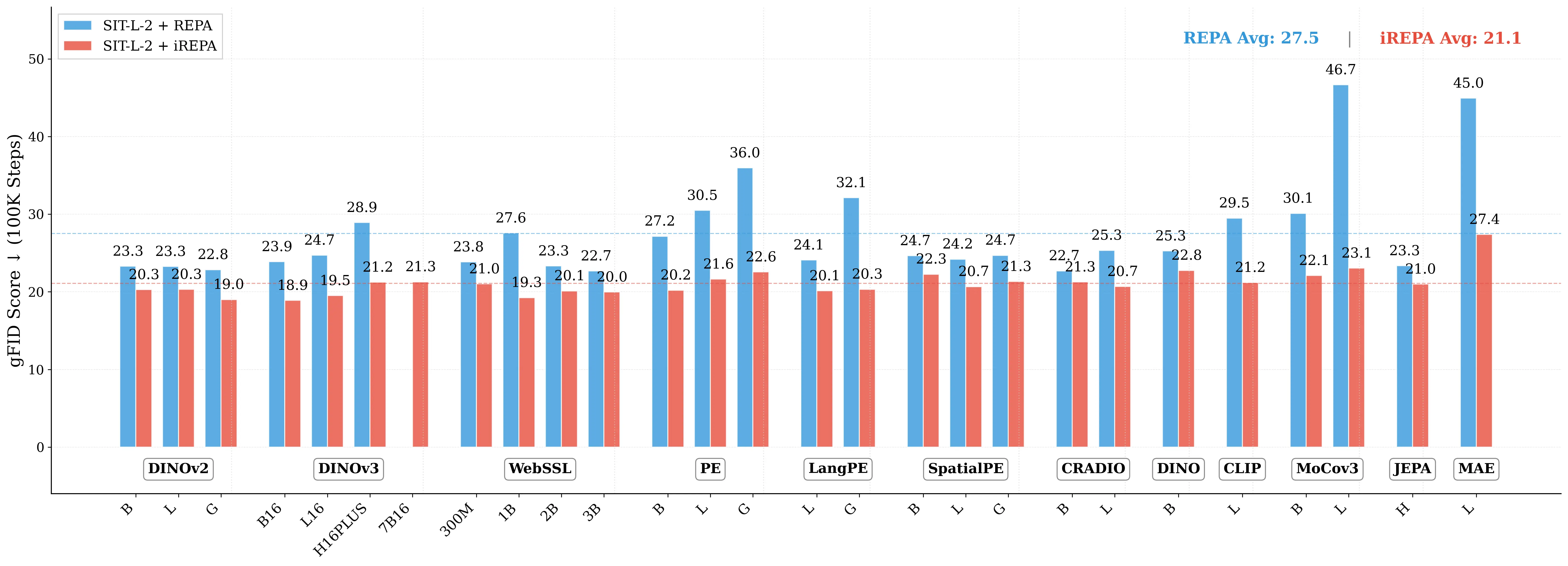
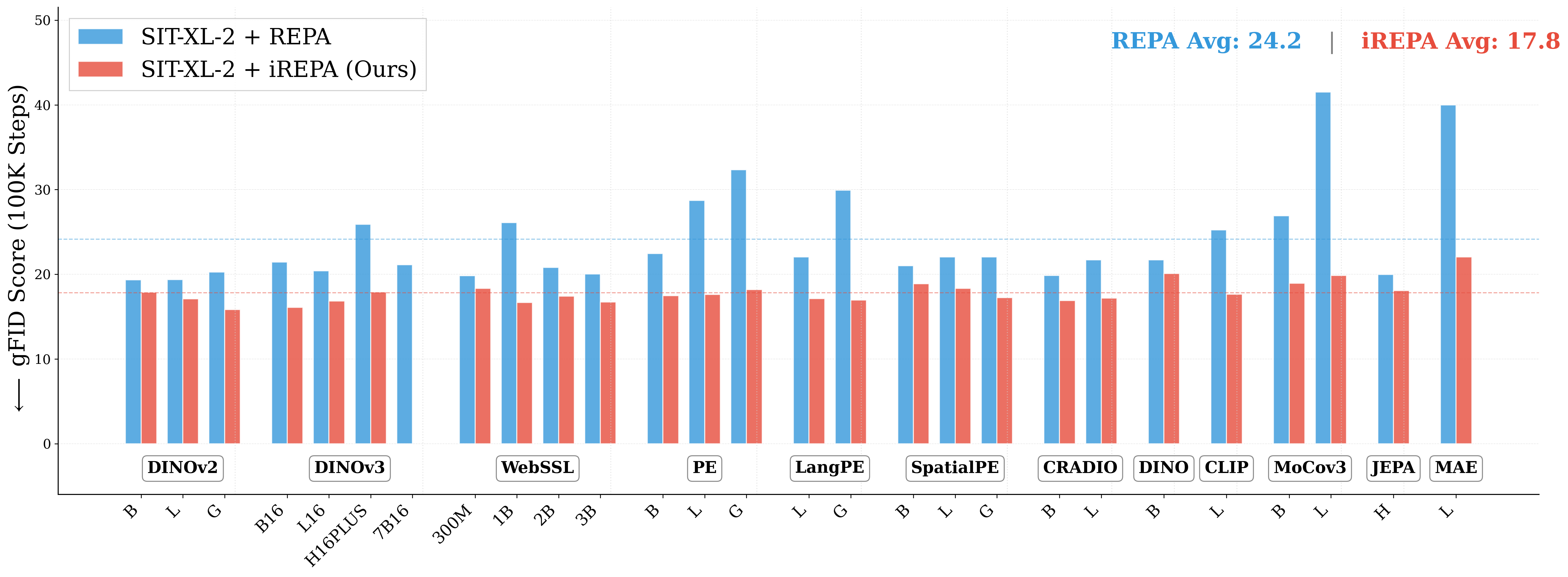
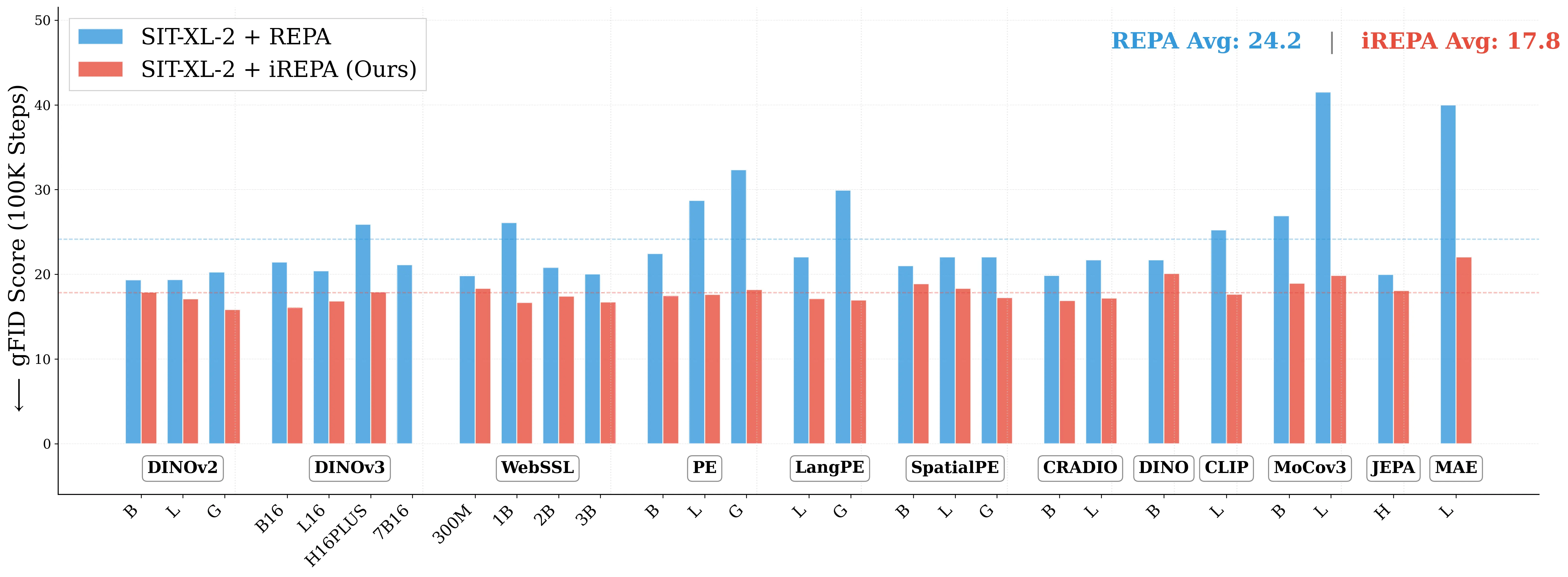
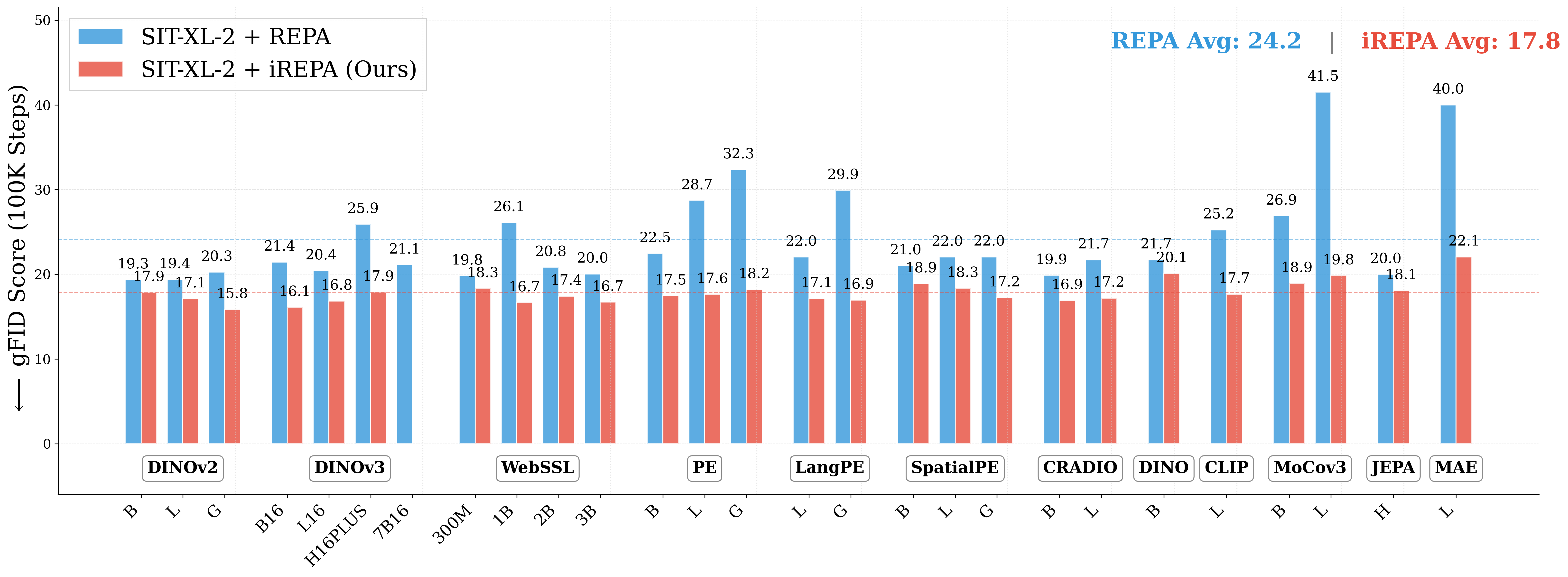
Figure 1: What matters for representation alignment? Left: Correlation analysis across 27 diverse
vision encoders. Surprisingly, contrary to the prevailing wisdom, we find that spatial structure, rather
than global performance (measured by linear probing accuracy), drives the generation performance
of a target representation. Right: We further study this by introducing two simple modifications to
accentuate the transfer of spatial features from target representation to diffusion model. Our simple
approach consistently improves the convergence speed of REPA across diverse settings.
1
INTRODUCTION
Representation alignment has emerged as a powerful technique for accelerating the training of
diffusion transformers (Ma et al., 2024; Peebles & Xie, 2023). By aligning internal diffusion
⋆Done during internship at Adobe Research
Project: https://end2end-diffusion.github.io/irepa
1
arXiv:2512.10794v1 [cs.CV] 11 Dec 2025
Preprint.
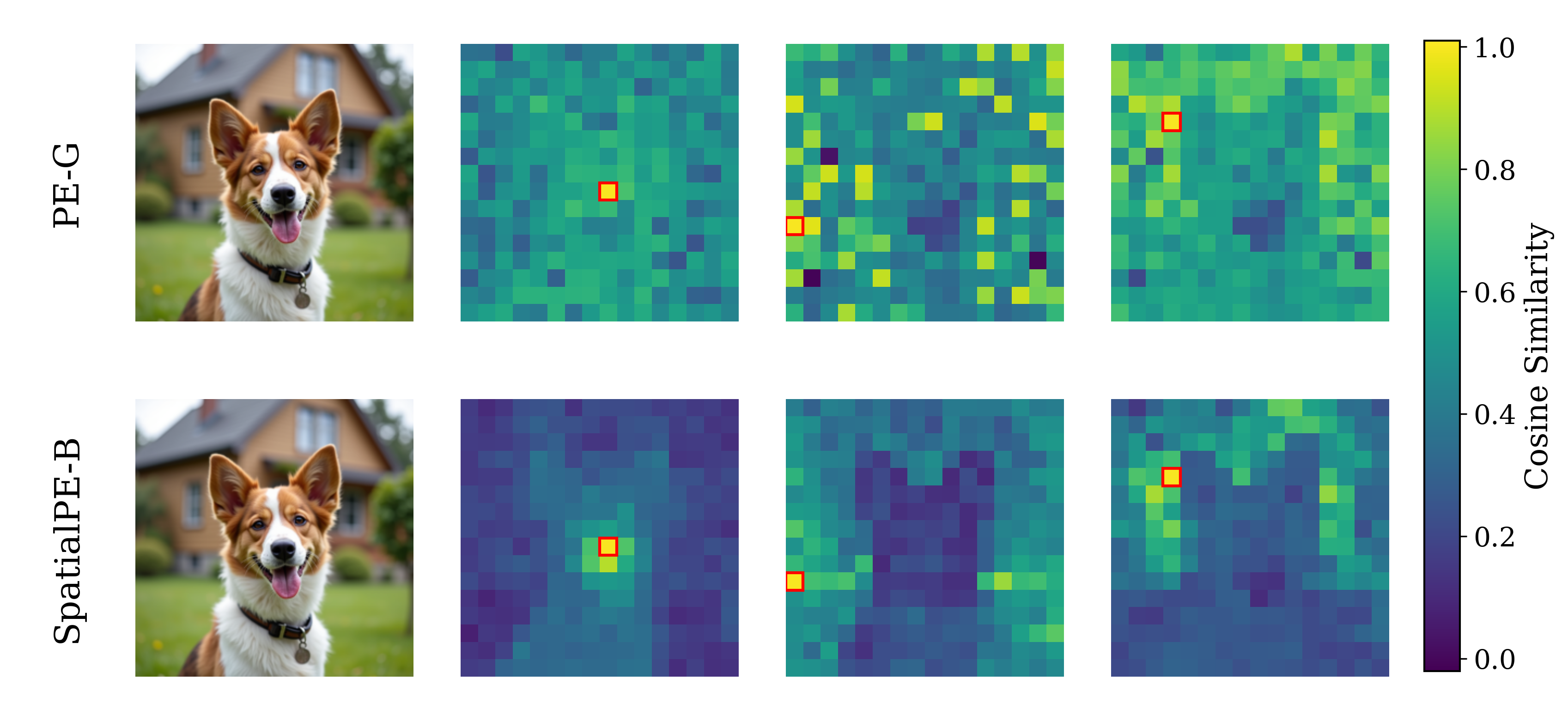
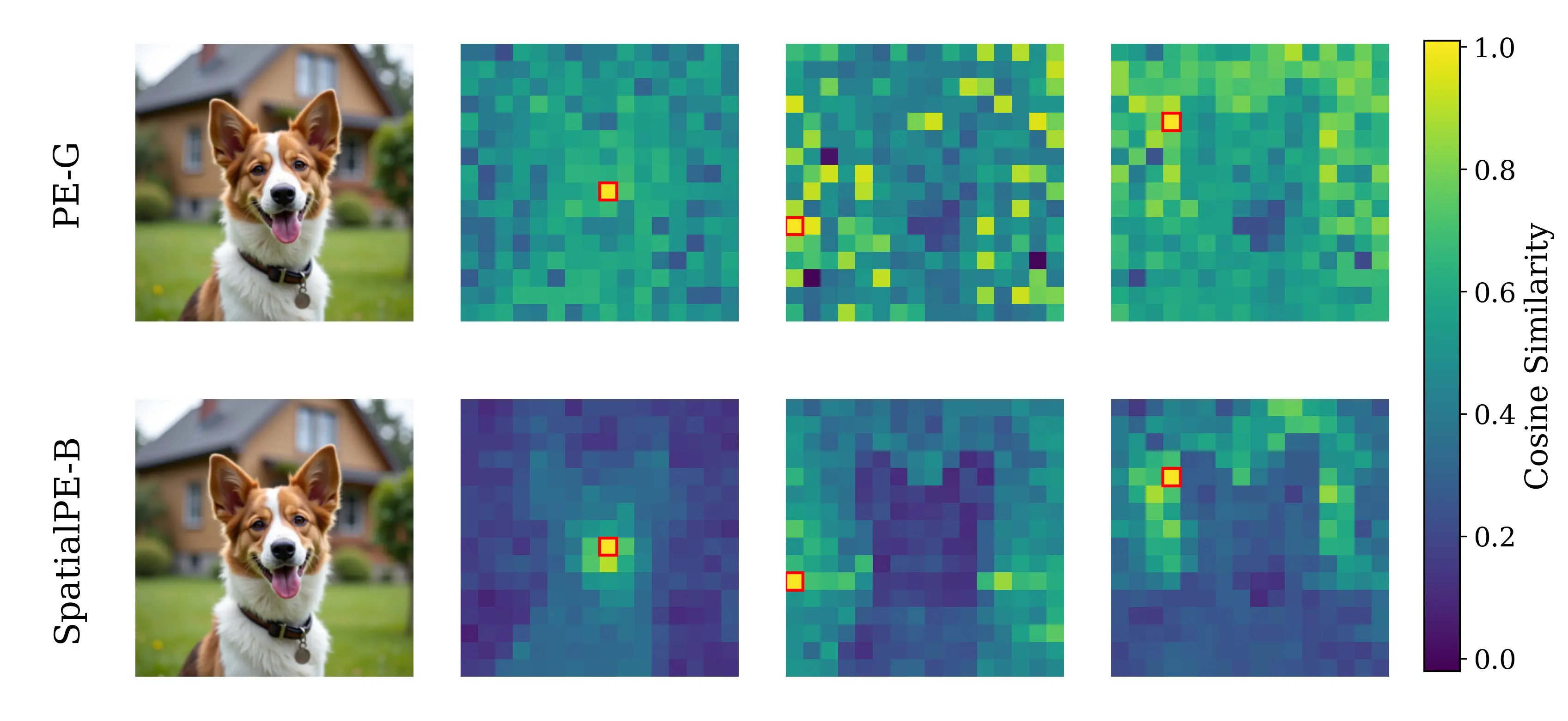
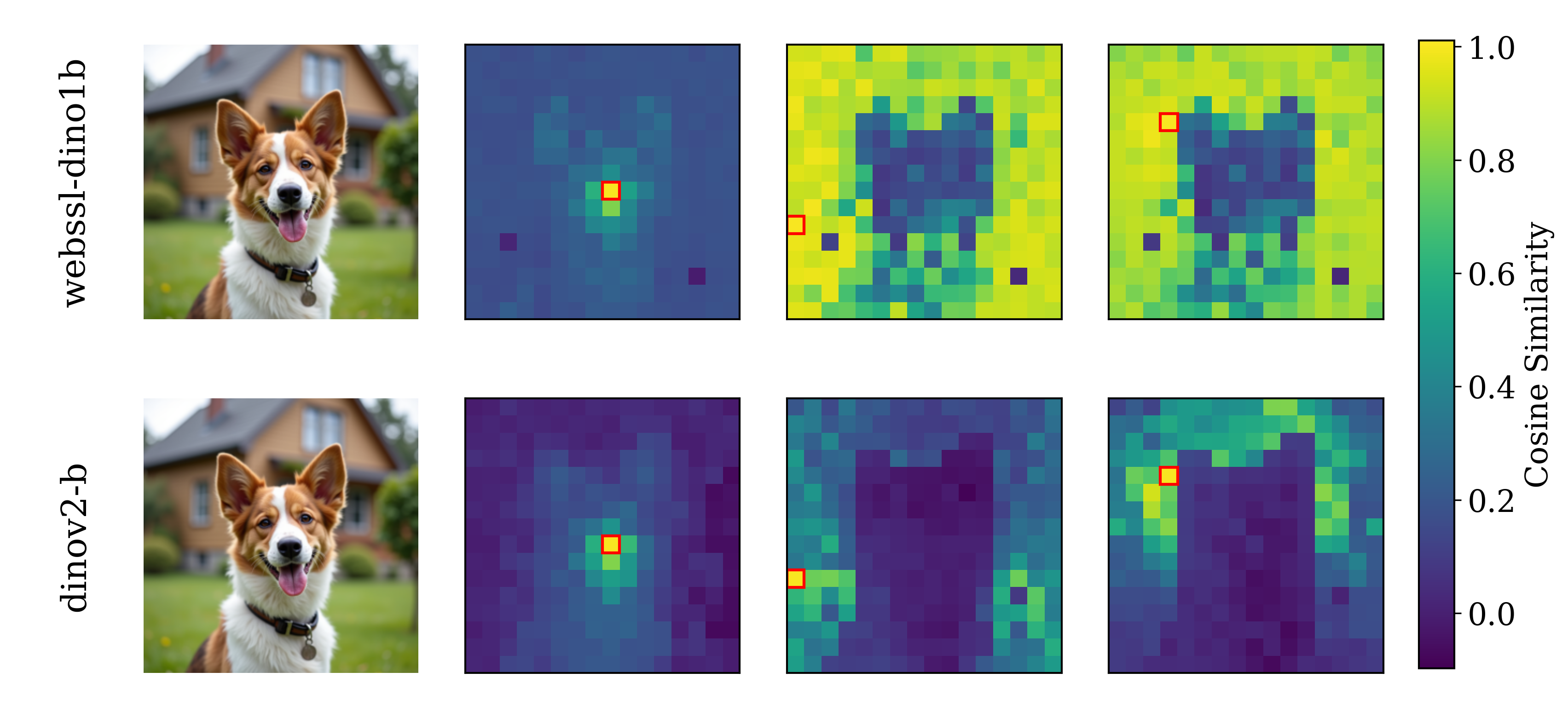
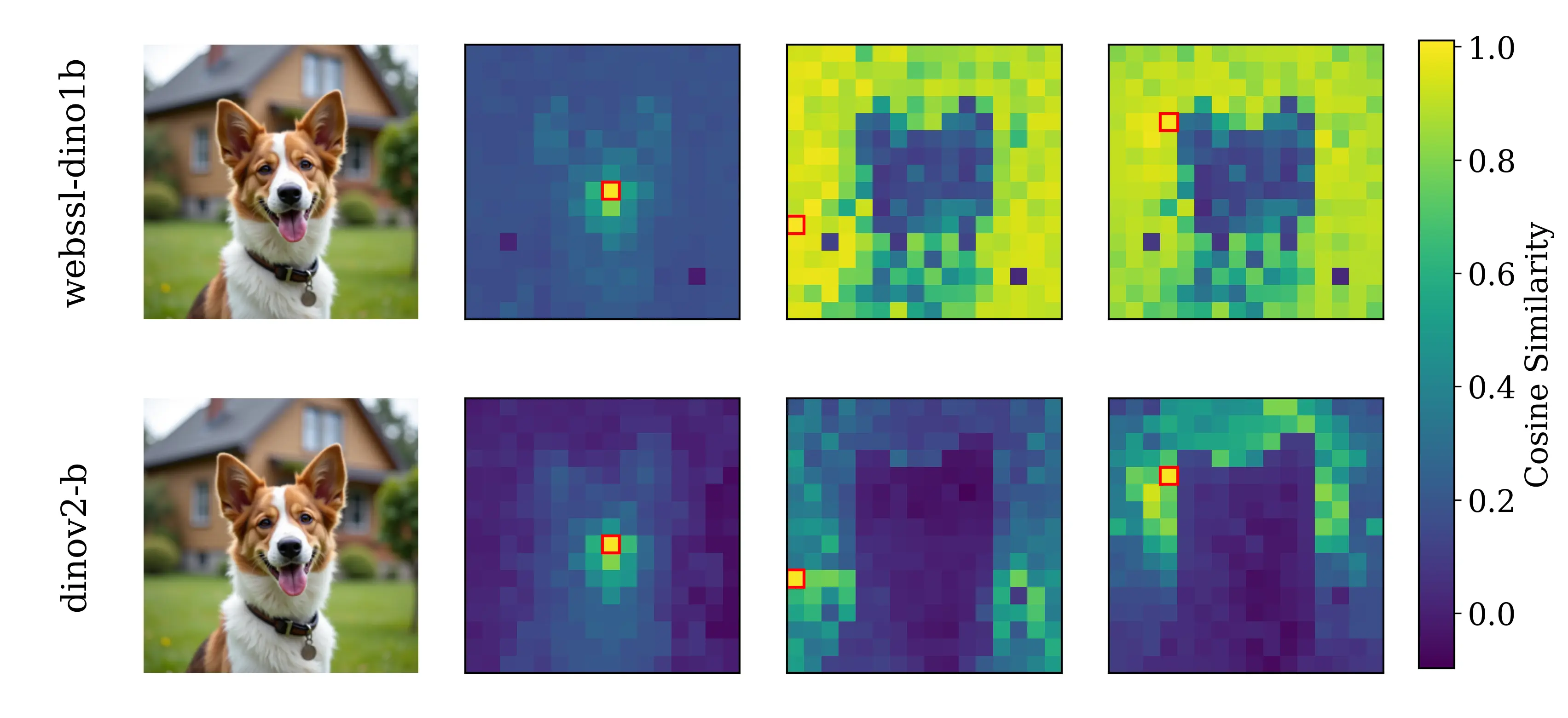
Spatial Self-similarity Visualization
PE-G
SpatialPE-B
Query image
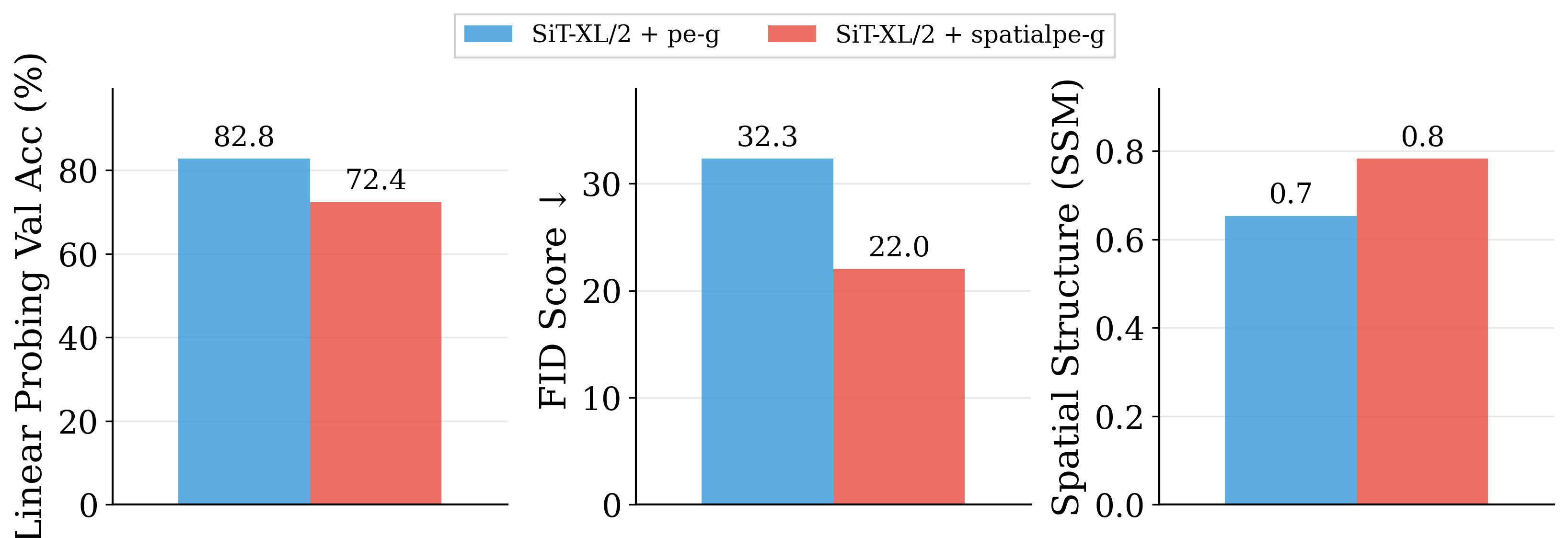
Better Global
Worse Generation
Better Spatial
Better Generation
Gen. qual.
gFID ↓
Spatial
LDS↑
Global
Val acc ↑
32.3
0.08
82.8%
21.0
0.34
53.1%
Spatial Self-similarity Visualization
Query image
WebSSL-1B
SpatialPE-B
Better Global
Worse Generation
Better Spatial
Better Generation
Gen. qual.
gFID ↓
Spatial
LDS ↑
Global
Val acc ↑
26.1
0.18
76.0%
21.0
0.34
53.1%
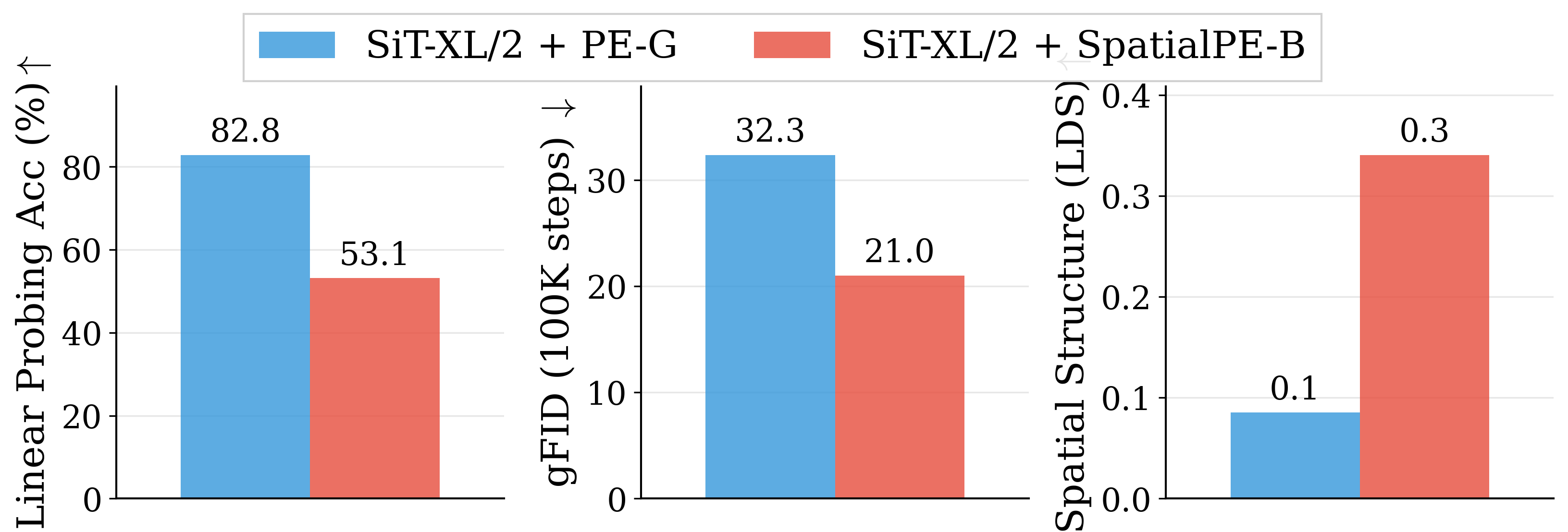
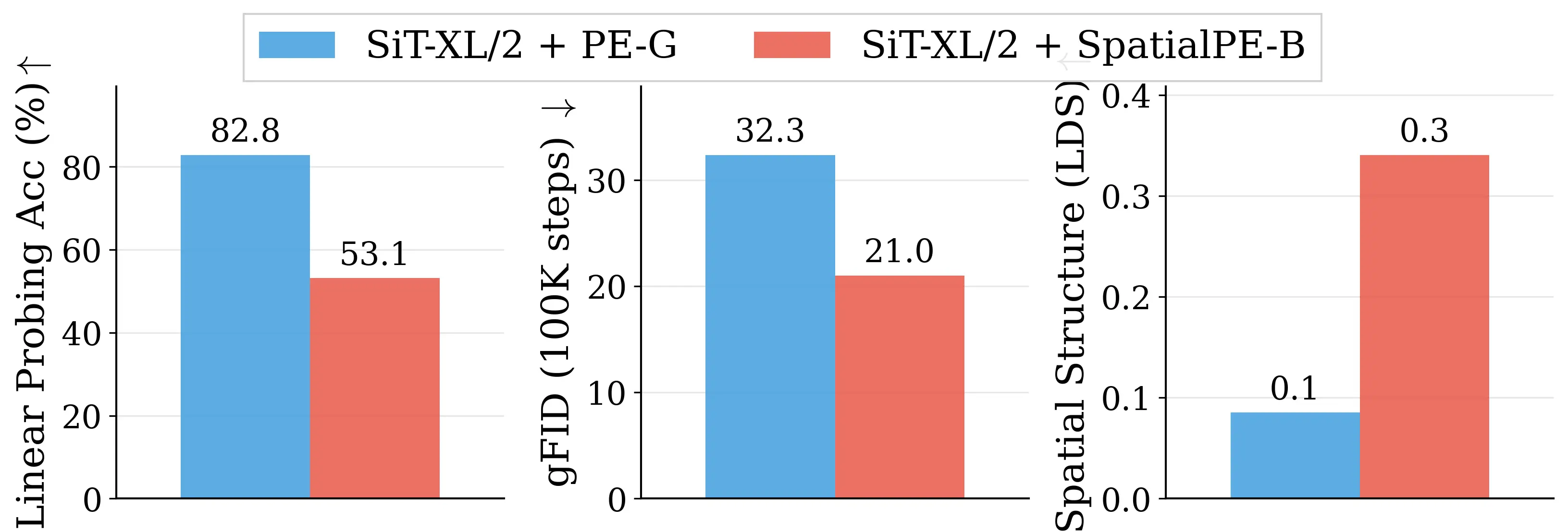
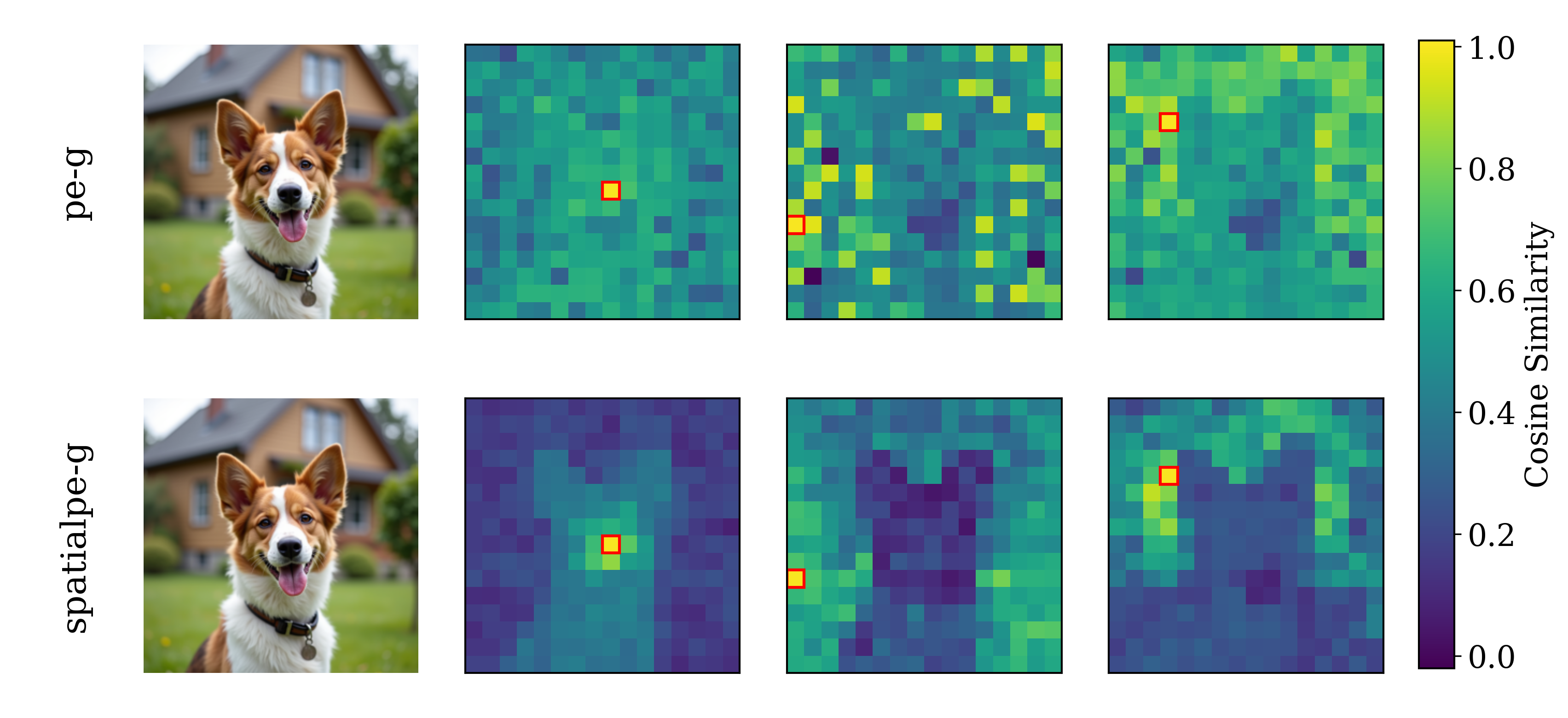
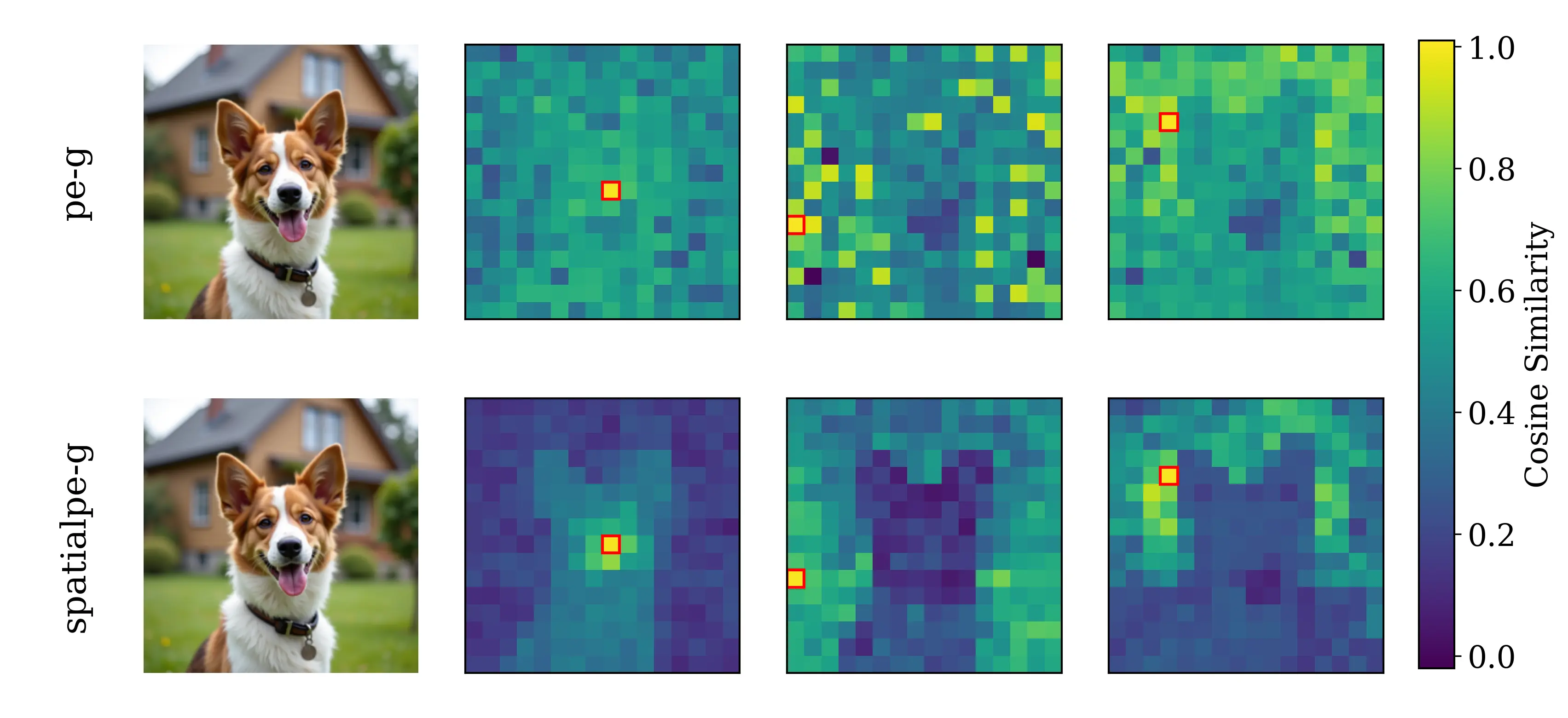
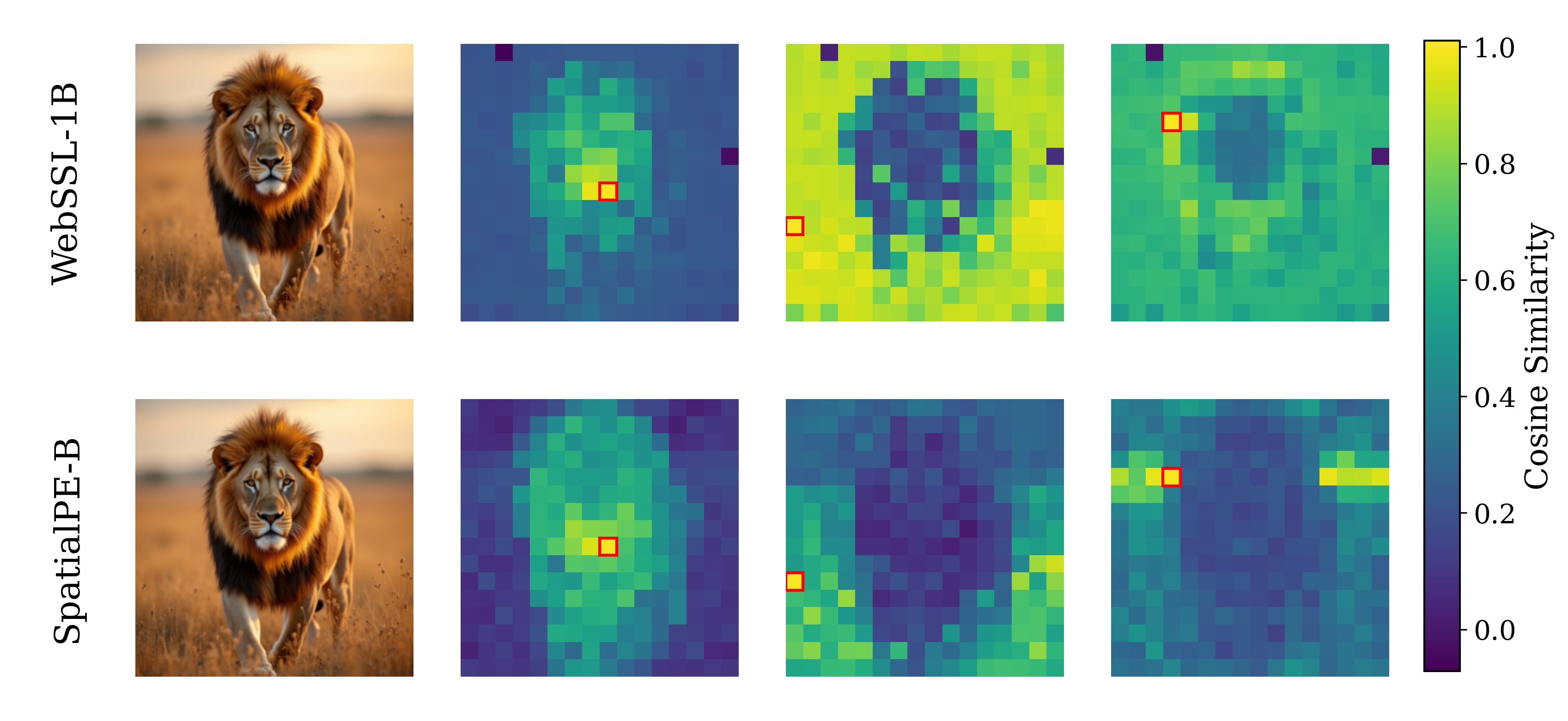
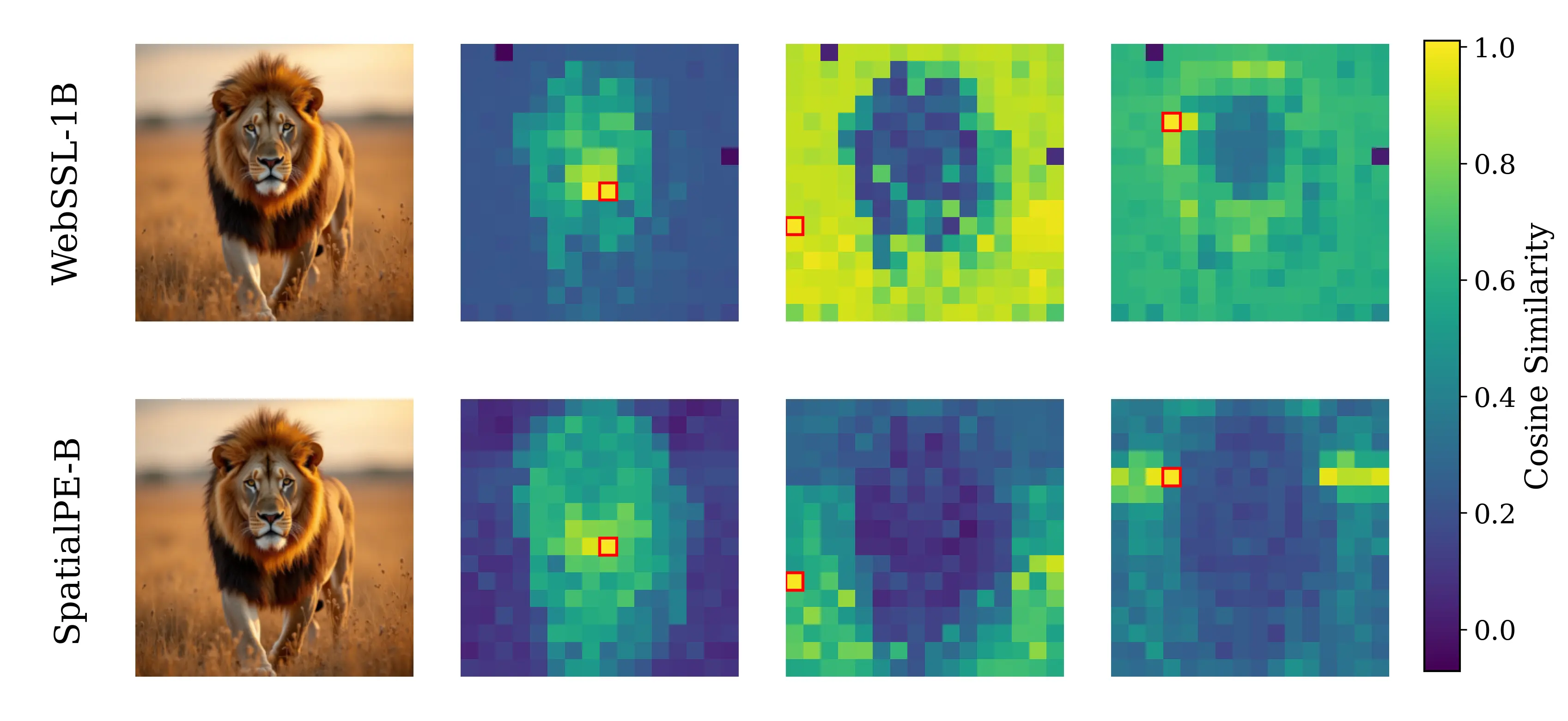
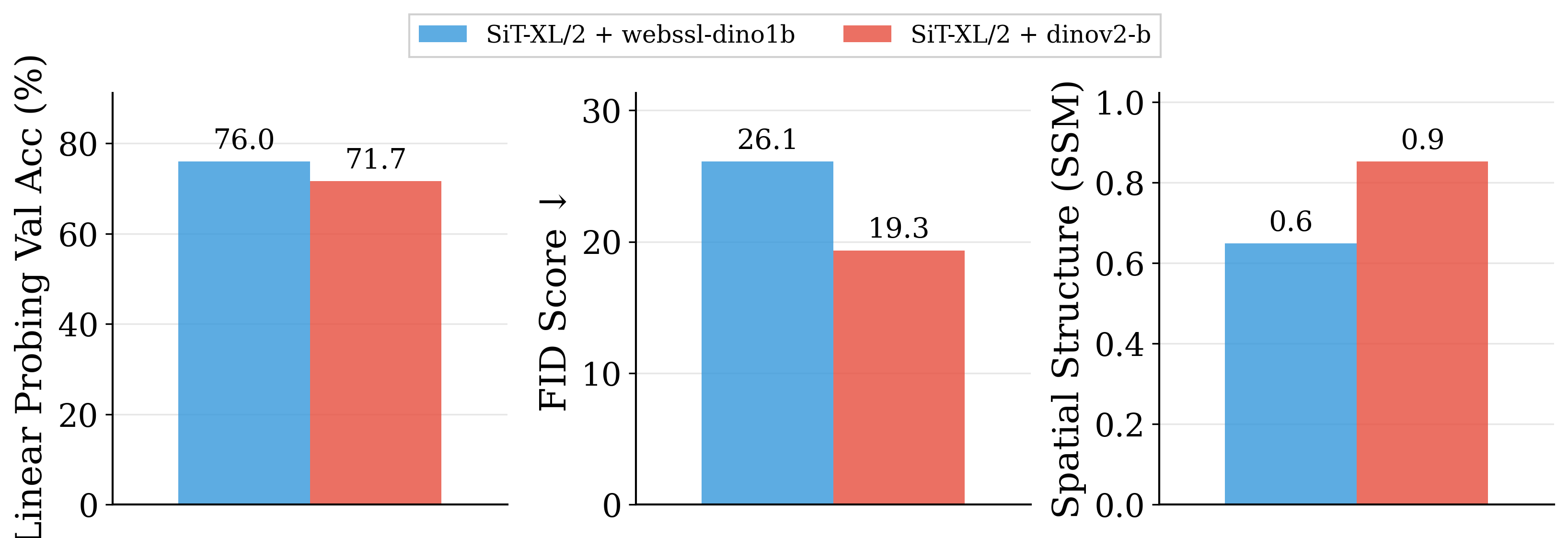
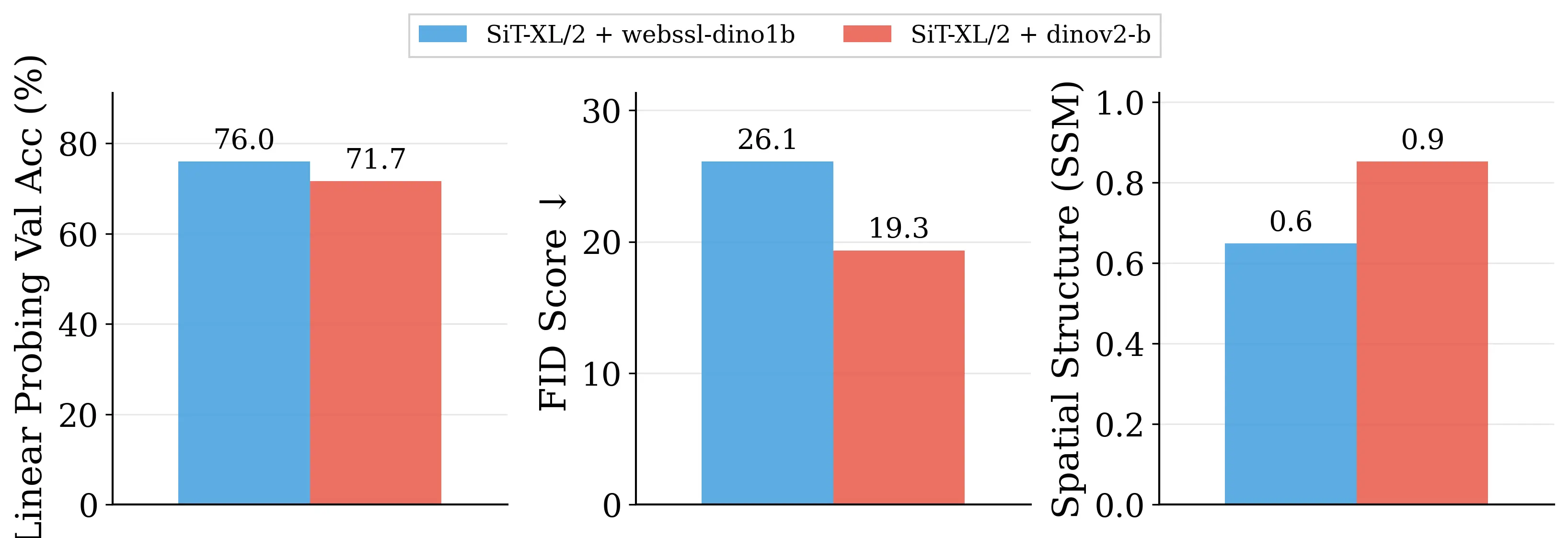
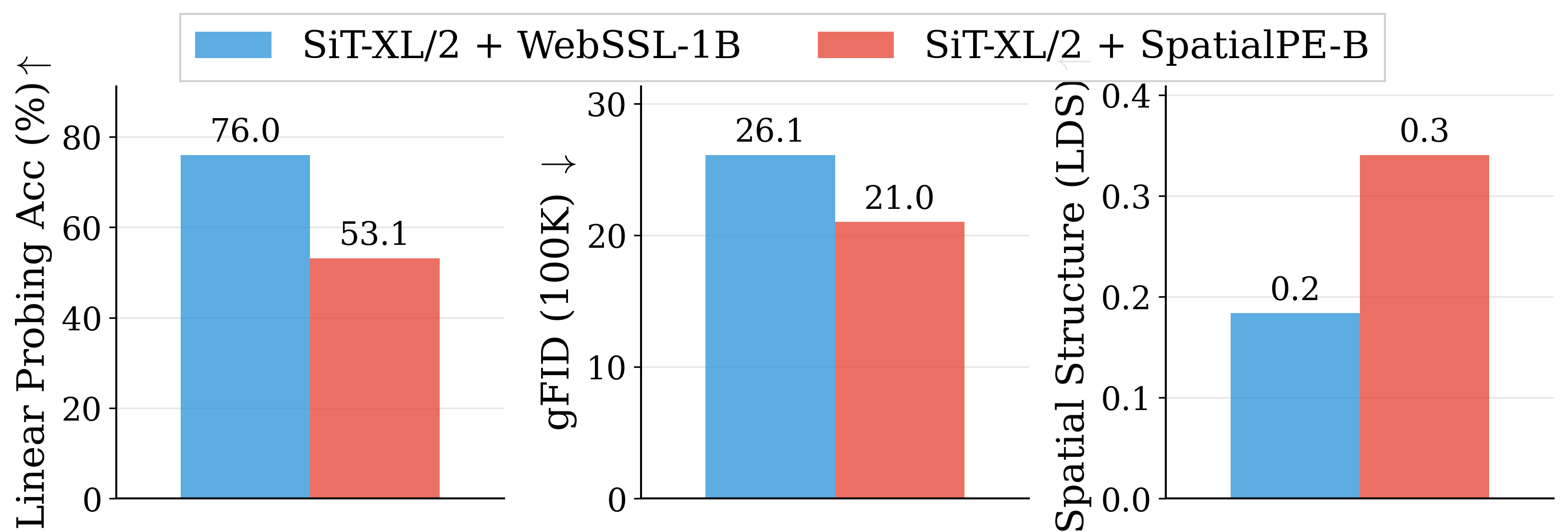
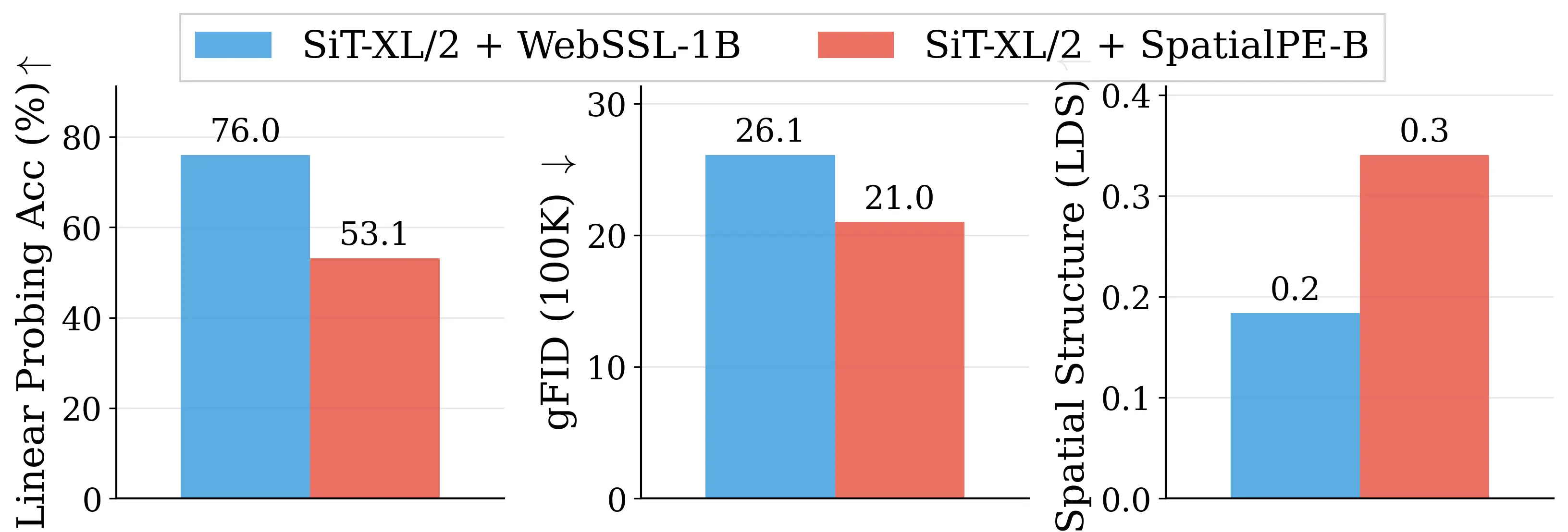
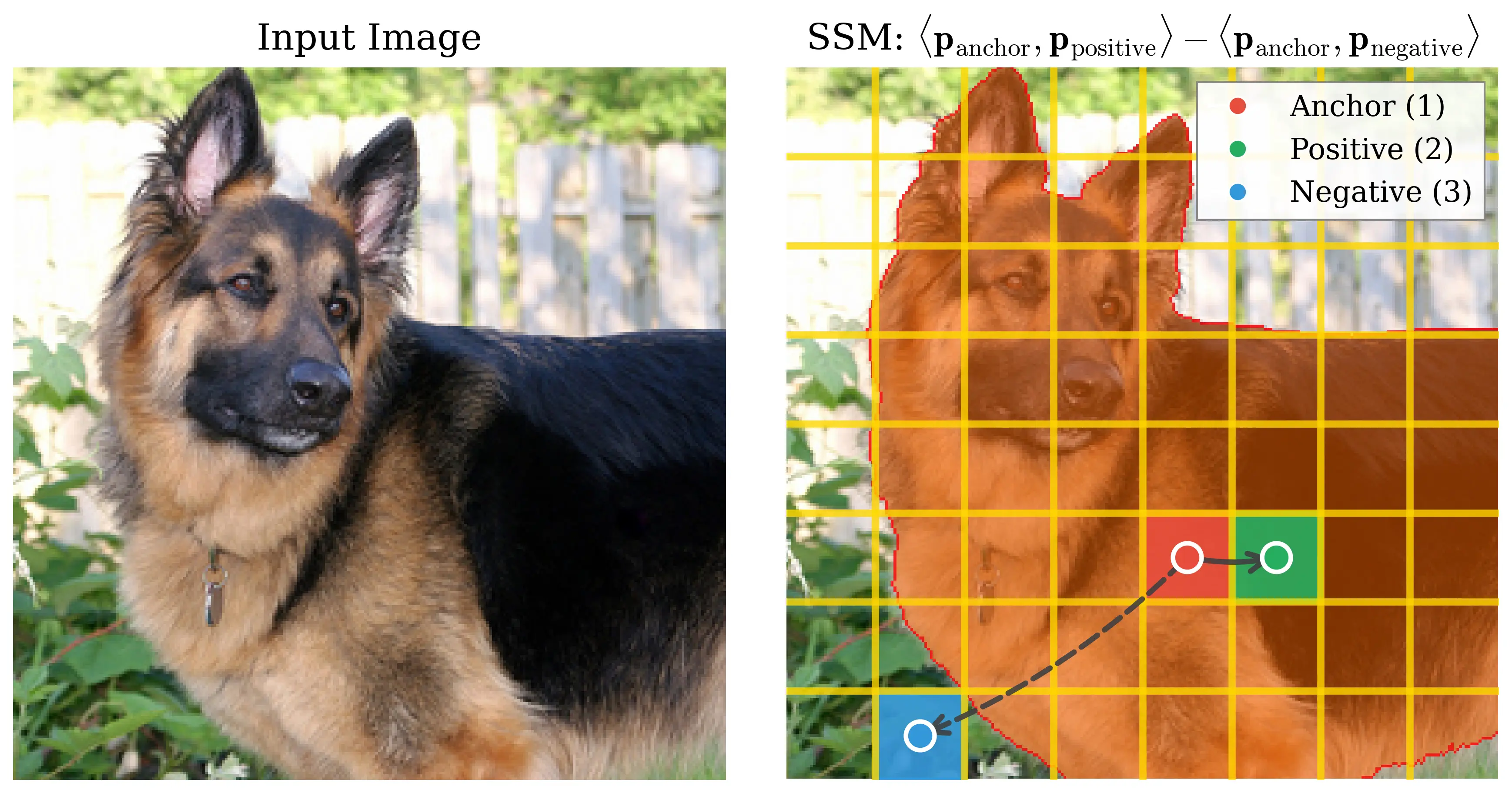
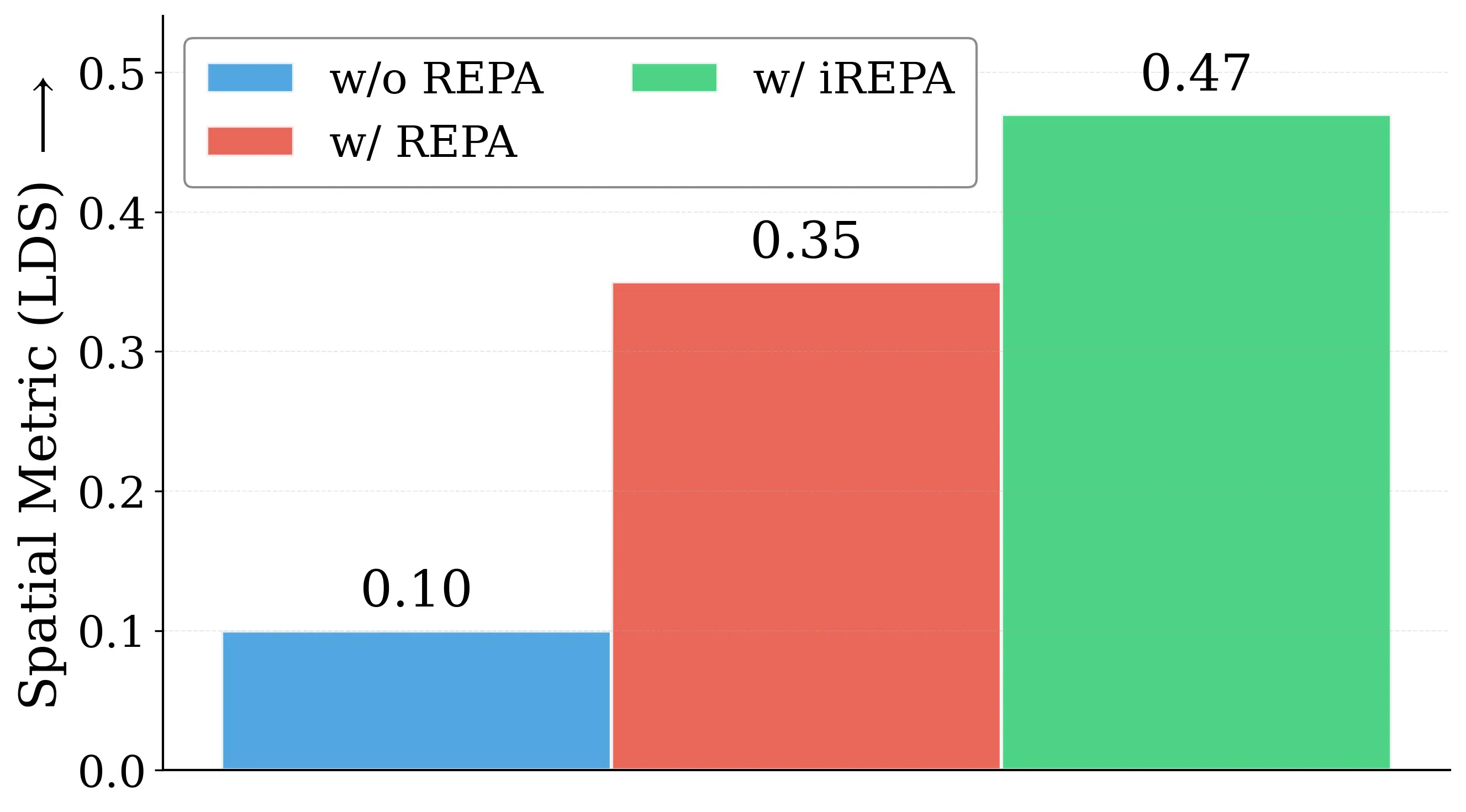
Figure 2: Motivating examples — spatial structure matters. Metrics comparison showing inverse
relationship between ImageNet accuracy and generation quality. Left: PE-G, despite having signifi-
cantly higher validation accuracy (82.8% vs. 53.1%), shows worse generation quality compared to
SpatialPE-B (Bolya et al., 2025). Right: Similarly, WebSSL-1B (Fan et al., 2025) also shows much
better global performance (76.0% vs. 53.1%), but worse generation. Spatial Self-Similarity: We find
that spatial structure instead provides a better predictor of generation quality than global performance.
See §3 for spatial structure metric. All results reported at 100K using SiT-XL/2 and REPA.
representations with pretrained self-supervised visual encoders, recent methods have demonstrated
significant improvements in the convergence speed and final performance (Yu et al., 2024; Leng
et al., 2025a). However, despite these empirical successes, there remains limited understanding of
the precise mechanisms through which self-supervised features enhance diffusion model training. A
fundamental question persists: is the improvement primarily driven by incorporating better global
semantic information, as commonly measured through linear probing performance, or does it stem
from better capturing spatial structure, characterized by the relationships between patch token
representations?
Understanding these mechanisms is crucial for advancing generative model training, as it directly
impacts one’s ability to select the optimal target representation and maximize its benefits. Currently,
a prevalent assumption is that encoder performance for representation alignment correlates strongly
with ImageNet-1K validation accuracy, a proxy measure of global semantic understanding (Oquab
et al., 2024; Chen et al., 2021). That is, target representations with better
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.