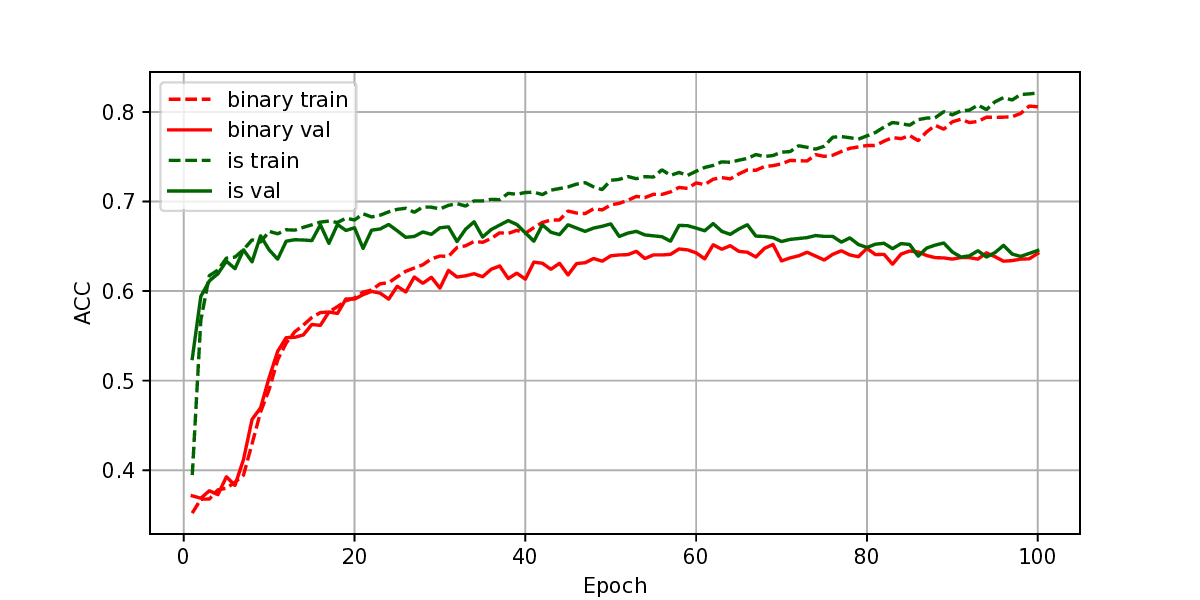
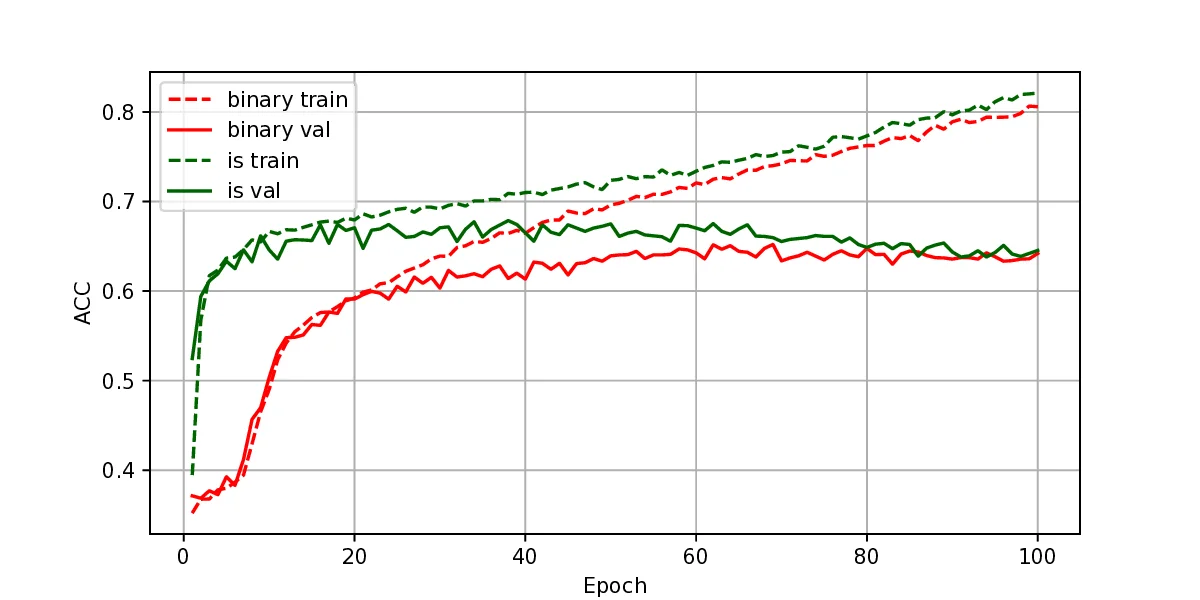
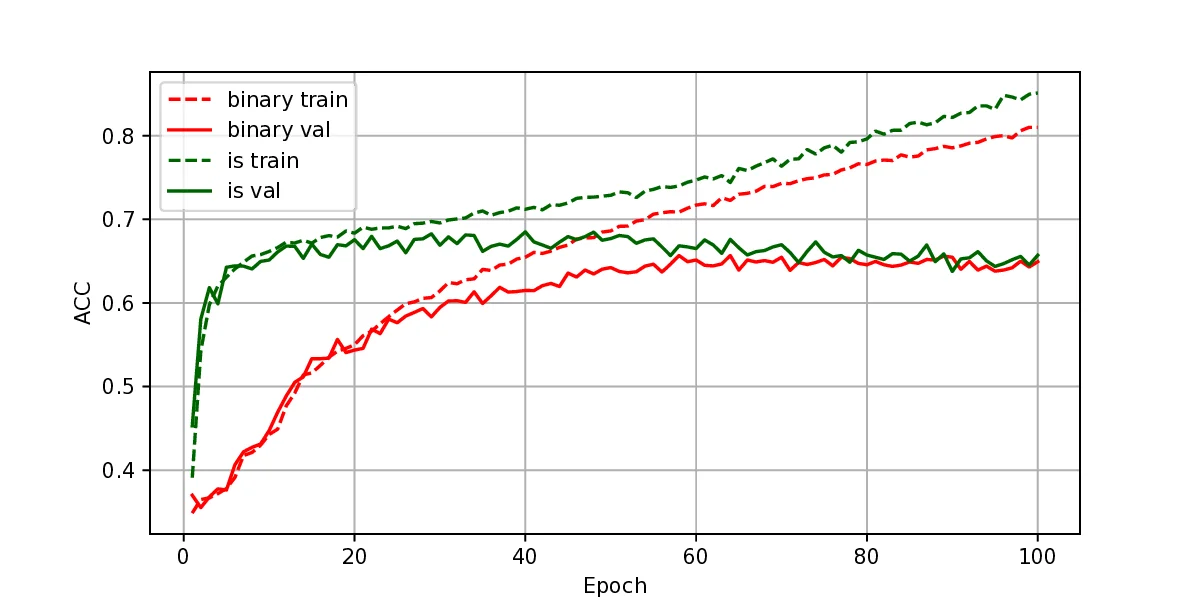
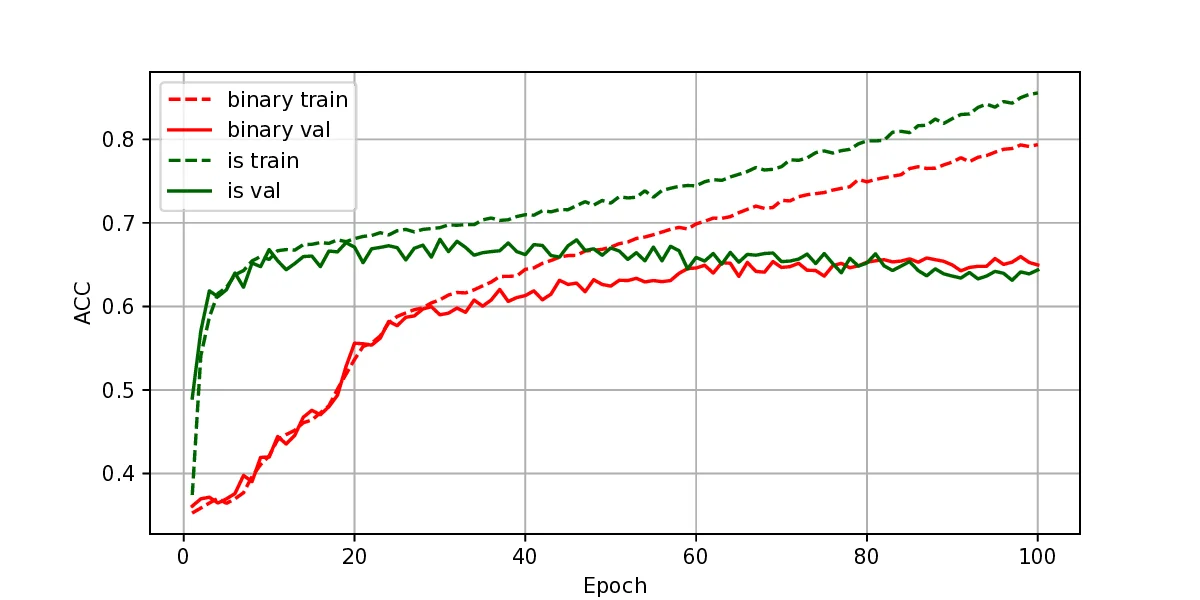
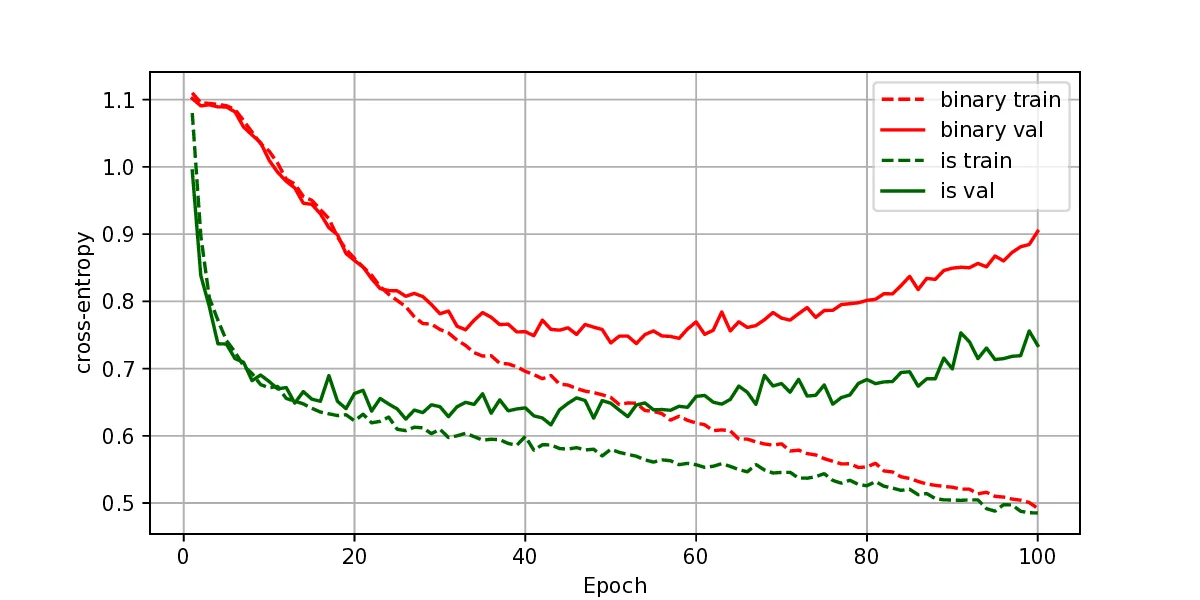
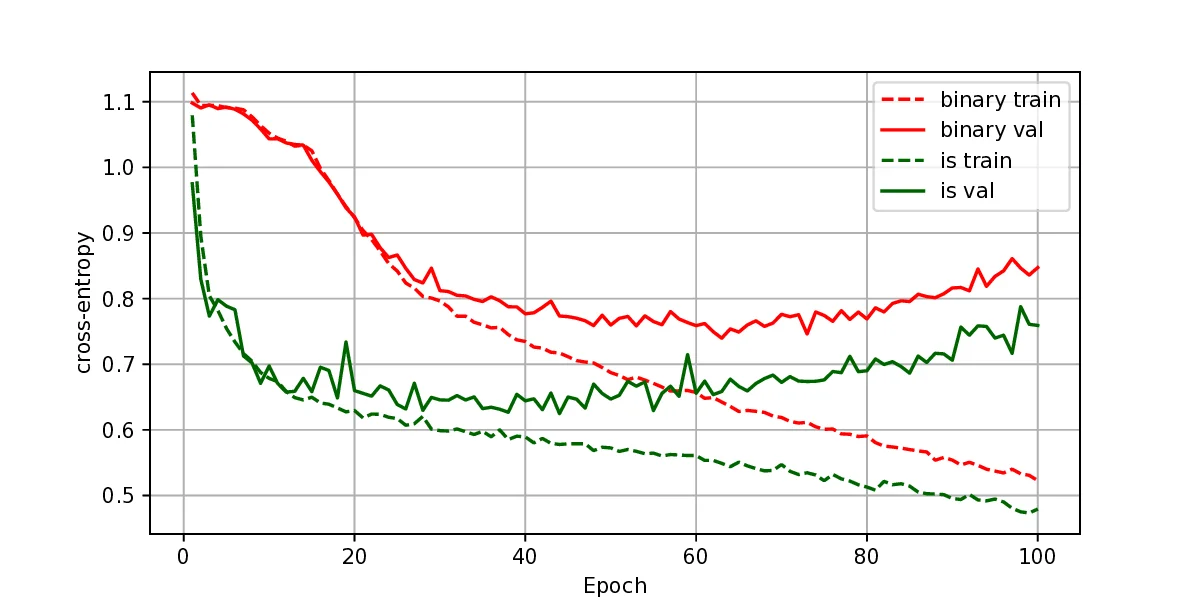
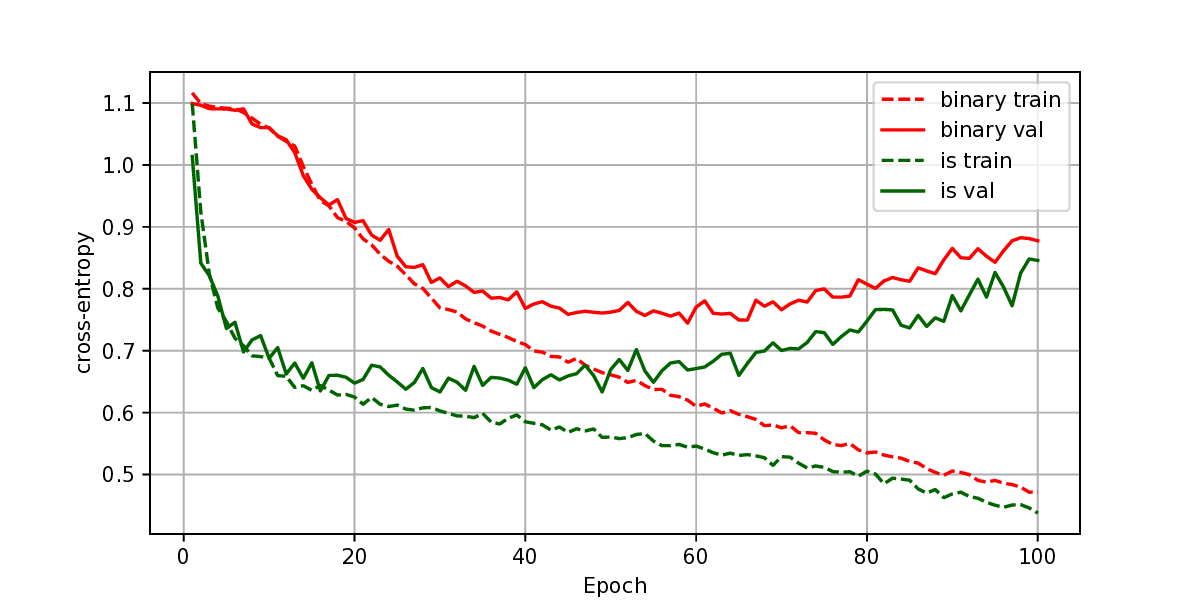
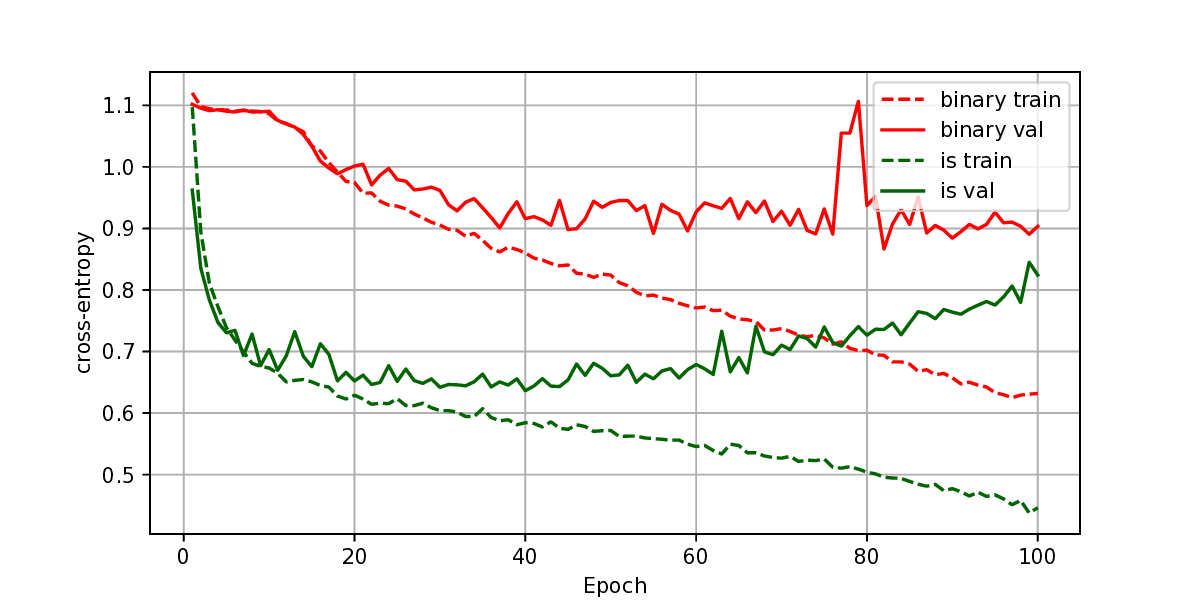
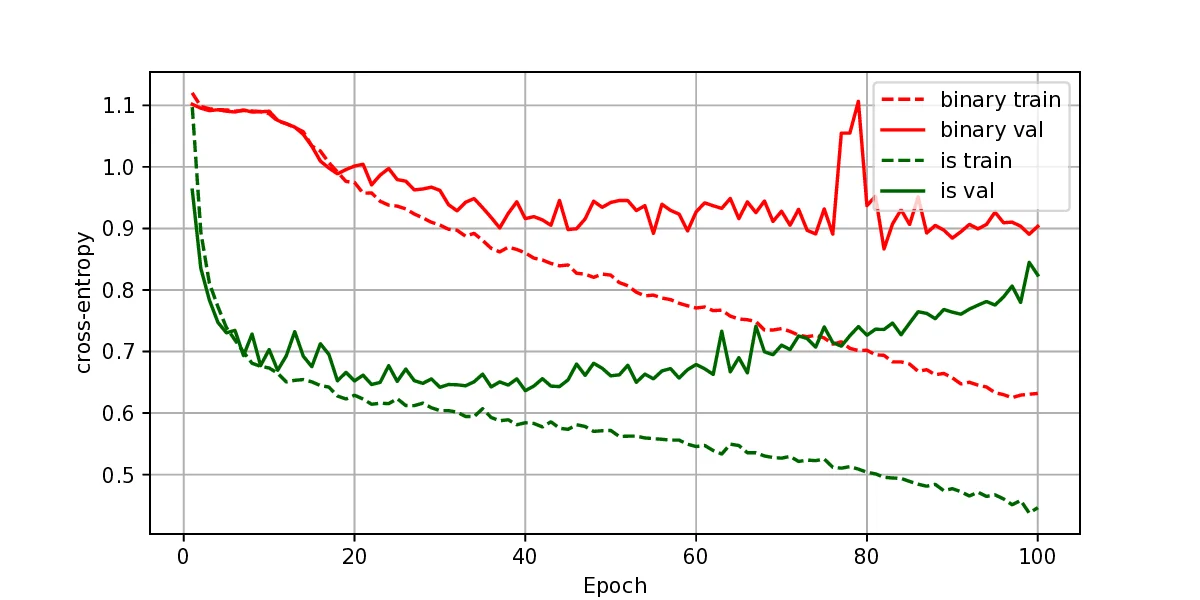
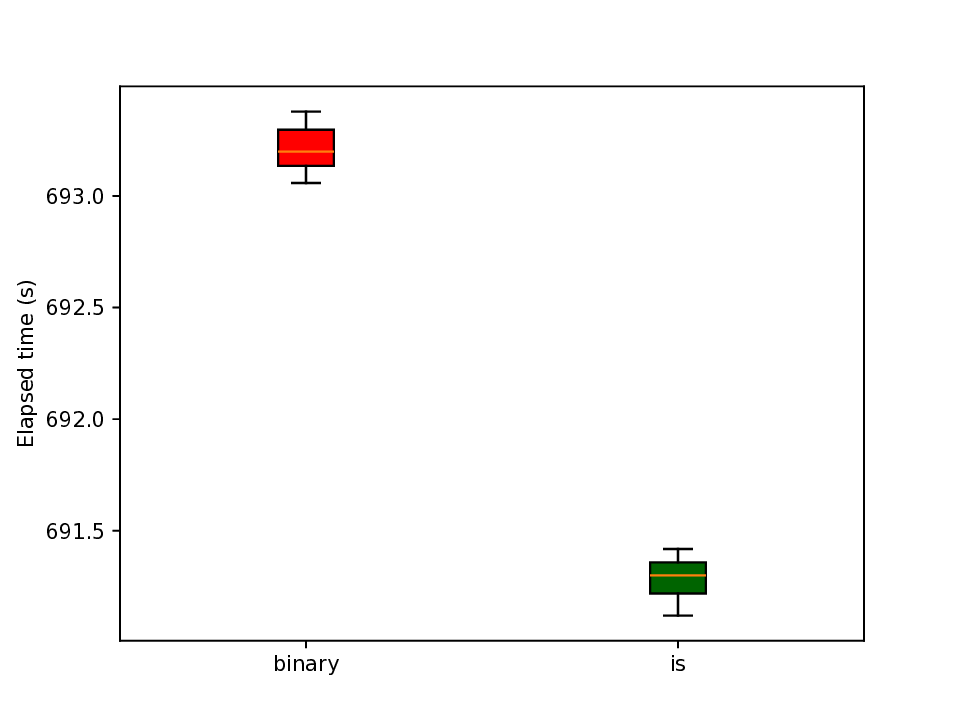
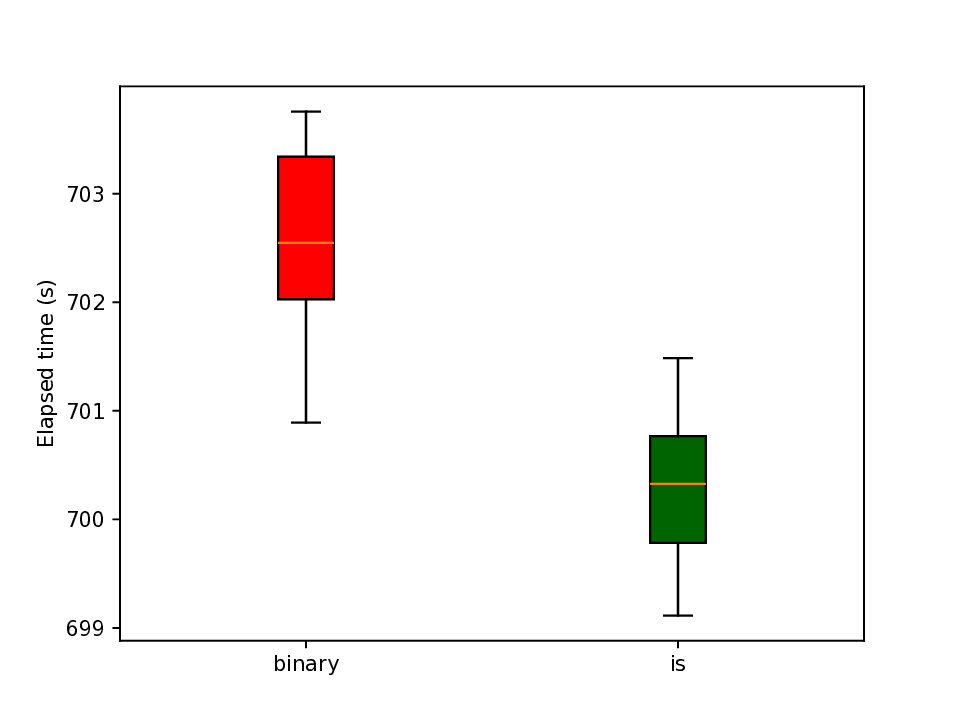
The representation of graphs is commonly based on the adjacency matrix concept. This formulation is the foundation of most algebraic and computational approaches to graph processing. The advent of deep learning language models offers a wide range of powerful computational models that are specialized in the processing of text. However, current procedures to represent graphs are not amenable to processing by these models. In this work, a new method to represent graphs is proposed. It represents the adjacency matrix of a graph by a string of simple instructions. The instructions build the adjacency matrix step by step. The transformation is reversible, i.e., given a graph the string can be produced and vice versa. The proposed representation is compact, and it maintains the local structural patterns of the graph. Therefore, it is envisaged that it could be useful to boost the processing of graphs by deep learning models. A tentative computational experiment is reported, demonstrating improved classification performance and faster computation times with the proposed representation.
Deep Dive into Representation of the structure of graphs by sequences of instructions.
The representation of graphs is commonly based on the adjacency matrix concept. This formulation is the foundation of most algebraic and computational approaches to graph processing. The advent of deep learning language models offers a wide range of powerful computational models that are specialized in the processing of text. However, current procedures to represent graphs are not amenable to processing by these models. In this work, a new method to represent graphs is proposed. It represents the adjacency matrix of a graph by a string of simple instructions. The instructions build the adjacency matrix step by step. The transformation is reversible, i.e., given a graph the string can be produced and vice versa. The proposed representation is compact, and it maintains the local structural patterns of the graph. Therefore, it is envisaged that it could be useful to boost the processing of graphs by deep learning models. A tentative computational experiment is reported, demonstrating impr
REPRESENTATION OF THE STRUCTURE OF GRAPHS BY
SEQUENCES OF INSTRUCTIONS
A PREPRINT
Ezequiel López-Rubio∗
Department of Computer Languages and Computer Science
University of Málaga
Bulevar Louis Pasteur, 35
29071 Málaga, Spain
ezeqlr@lcc.uma.es
December 16, 2025
ABSTRACT
The representation of graphs is commonly based on the adjacency matrix concept. This formulation
is the foundation of most algebraic and computational approaches to graph processing. The advent
of deep learning language models offers a wide range of powerful computational models that are
specialized in the processing of text. However, current procedures to represent graphs are not
amenable to processing by these models. In this work, a new method to represent graphs is proposed.
It represents the adjacency matrix of a graph by a string of simple instructions. The instructions
build the adjacency matrix step by step. The transformation is reversible, i.e., given a graph the
string can be produced and vice versa. The proposed representation is compact, and it maintains the
local structural patterns of the graph. Therefore, it is envisaged that it could be useful to boost the
processing of graphs by deep learning models. A tentative computational experiment is reported,
demonstrating improved classification performance and faster computation times with the proposed
representation.
Keywords graph representation · adjacency matrix · instruction sequences · deep learning · language models · structural
patterns
1
Introduction
Graphs provide a flexible abstraction for relational data in domains such as social networks, molecules, knowledge
graphs, recommendation, and databases [Zhou et al., 2020, Khoshraftar and An, 2024, Ju et al., 2024]. The standard
approach to graph processing with deep learning models is to learn a suitable representation of them. The goal of
graph representation learning is to map nodes, edges, subgraphs, or whole graphs into low-dimensional vectors that
preserve structural properties and attributes, enabling downstream tasks such as node classification, link prediction,
graph classification, and anomaly detection [Khoshraftar and An, 2024, Ju et al., 2024].
Early work on graph representation focused on shallow embedding methods that learn a lookup table of node embeddings
optimized for proximity in the original graph [Khoshraftar and An, 2024]. Random-walk-based methods such as
DeepWalk and node2vec treat truncated random walks as sentences and apply word embedding techniques to enforce
that co-visited nodes obtain similar vectors [Perozzi et al., 2014, Grover and Leskovec, 2016]. Matrix factorization
approaches, including Laplacian eigenmaps and variants based on factorizing pointwise mutual information matrices,
can be interpreted as implicitly optimizing similar proximity objectives [Belkin and Niyogi, 2003, Ou et al., 2016].
These techniques are scalable and effective but decouple representation learning from node features and struggle to
generalize to unseen nodes or dynamic graphs [Khoshraftar and An, 2024, Ju et al., 2024].
∗Corresponding author. ITIS Software. Universidad de Málaga. C/ Arquitecto Francisco Peñalosa 18, 29010, Málaga, Spain
arXiv:2512.10429v2 [cs.AI] 13 Dec 2025
Representation of graphs by sequences of instructions
A PREPRINT
Extensions of shallow embeddings incorporate side information and edge types, e.g., for heterogeneous and knowledge
graphs. Knowledge graph embedding methods such as TransE, DistMult, and RotatE embed entities and relations into
continuous spaces and define scoring functions for triplets [Wang et al., 2017]. While powerful for link prediction, these
models typically ignore higher-order structure and are limited in expressivity compared to modern deep architectures
[Wang et al., 2017, Ju et al., 2024].
Deep graph representation learning is now dominated by Graph Neural Networks (GNNs), which implement message
passing over the graph structure [Zhou et al., 2020, Wu et al., 2021]. In the standard message-passing framework, each
node iteratively aggregates information from its neighbors and updates its hidden state using a permutation-invariant
function, yielding embeddings that combine local structure and node features [Gilmer et al., 2017, Zhou et al., 2020].
Popular instances include Graph Convolutional Networks (GCN), GraphSAGE, and Graph Attention Networks (GAT),
which differ mainly in their neighborhood aggregation and normalization schemes [Kipf and Welling, 2017, Hamilton
et al., 2017, Veliˇckovi´c et al., 2018].
GNNs can be categorized by their architectural principles [Zhou et al., 2020, Ju et al., 2024]. Spectral GNNs define
convolutions via the graph Laplacian eigenbasis, while spatial GNNs perform aggregation directly in the vertex domain
using learned filters [Bruna et al., 2014, Kipf and Welling, 2017]. Recurrent and attention-based variants replace simple
aggregators with recurrent units or attention mechanisms to capture more expressive interactions [Gilmer et al., 2
…(Full text truncated)…
This content is AI-processed based on ArXiv data.