FunPhase: A Periodic Functional Autoencoder for Motion Generation via Phase Manifolds
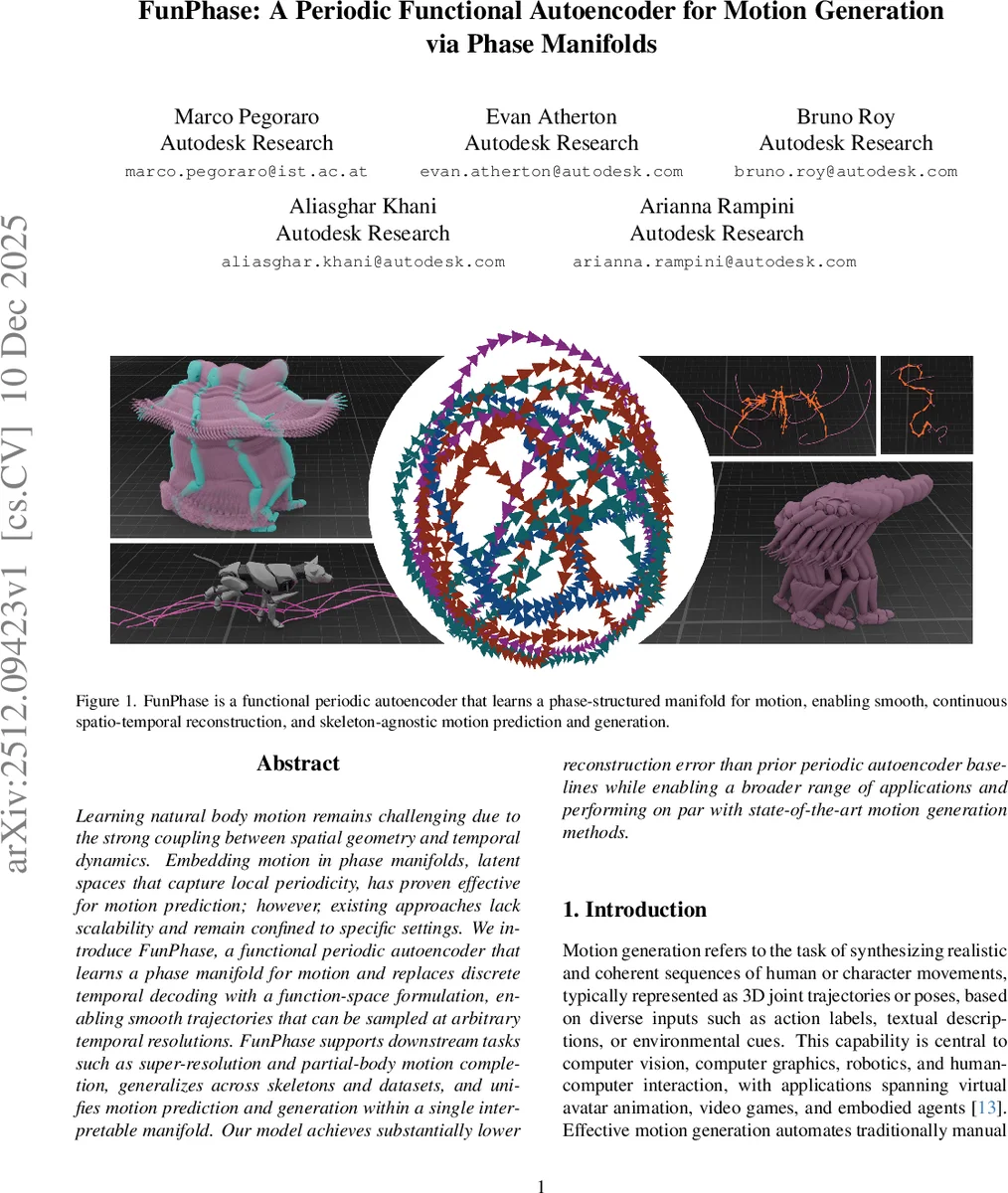
Learning natural body motion remains challenging due to the strong coupling between spatial geometry and temporal dynamics. Embedding motion in phase manifolds, latent spaces that capture local periodicity, has proven effective for motion prediction; however, existing approaches lack scalability and remain confined to specific settings. We introduce FunPhase, a functional periodic autoencoder that learns a phase manifold for motion and replaces discrete temporal decoding with a function-space formulation, enabling smooth trajectories that can be sampled at arbitrary temporal resolutions. FunPhase supports downstream tasks such as super-resolution and partial-body motion completion, generalizes across skeletons and datasets, and unifies motion prediction and generation within a single interpretable manifold. Our model achieves substantially lower reconstruction error than prior periodic autoencoder baselines while enabling a broader range of applications and performing on par with state-of-the-art motion generation methods.
💡 Research Summary
The paper “FunPhase: A Periodic Functional Autoencoder for Motion Generation via Phase Manifolds” introduces a novel framework for generating and predicting realistic human or character motion. The core challenge in motion modeling lies in the intricate coupling between spatial geometry (joint angles, positions) and temporal dynamics (velocity, acceleration). While phase-based representations, which encode the rhythmic progression of movement, have shown promise for improving temporal alignment (e.g., DeepPhase), existing methods are often limited to specific skeleton topologies, are not easily scalable, and lack a natural interface for probabilistic generative modeling.
FunPhase addresses these limitations by proposing a functional periodic autoencoder. Its key innovation is to model motion not as a discrete sequence of frames but as a continuous spatio-temporal function. This is achieved through a two-stage pipeline. First, the FunPhase autoencoder itself is trained. Its architecture employs separate Perceiver-based encoders for joint rotations (using the continuous 6D representation) and root positions. It incorporates graph-based spatial encodings (derived from skeleton topology) and Fourier-based temporal encodings, making it skeleton-agnostic and capable of handling variable-length sequences. The encoder compresses the input motion into a latent representation, which is then decomposed via a Fast Fourier Transform (FFT) layer and a linear regressor into periodic parameters for each latent channel: phase shift, amplitude, frequency, and bias. The decoder reconstructs the latent function by evaluating these sinusoidal parameters. Crucially, it uses cross-attention to query this reconstructed function at arbitrary spatio-temporal coordinates (time and joint index), enabling resolution-independent sampling. The training objective combines reconstruction losses for rotations and positions with physics-inspired penalties based on forward kinematics and foot contact constraints, promoting physical plausibility.
The second stage enables generative capabilities. A diffusion model is trained within the learned phase manifold—the space of periodic parameters produced by the FunPhase encoder. The authors argue that performing diffusion in this structured, phase-informed latent space provides a strong inductive bias, leading to more stable denoising and higher-quality motion generation compared to frame-based diffusion approaches.
The paper demonstrates that FunPhase achieves significantly lower reconstruction error than prior periodic autoencoder baselines. It showcases the model’s versatility in downstream tasks such as temporal super-resolution and partial-body motion completion. Furthermore, when combined with the latent diffusion model, FunPhase performs on par with state-of-the-art motion generation methods on standard benchmarks. The authors also introduce a proof-of-concept “Neural Motion Controller” that operates within the learned phase manifold, enabling phase-aligned and temporally consistent control.
In summary, FunPhase bridges the gap between structured, interpretable kinematic modeling (via phase manifolds) and modern functional generative models. It provides a unified, skeleton-agnostic framework that supports motion prediction, high-quality generation, and controllable editing within a single coherent latent space, offering a powerful foundation for applications in animation, robotics, and virtual interaction.
Comments & Academic Discussion
Loading comments...
Leave a Comment