GLACIA: Instance-Aware Positional Reasoning for Glacial Lake Segmentation via Multimodal Large Language Model
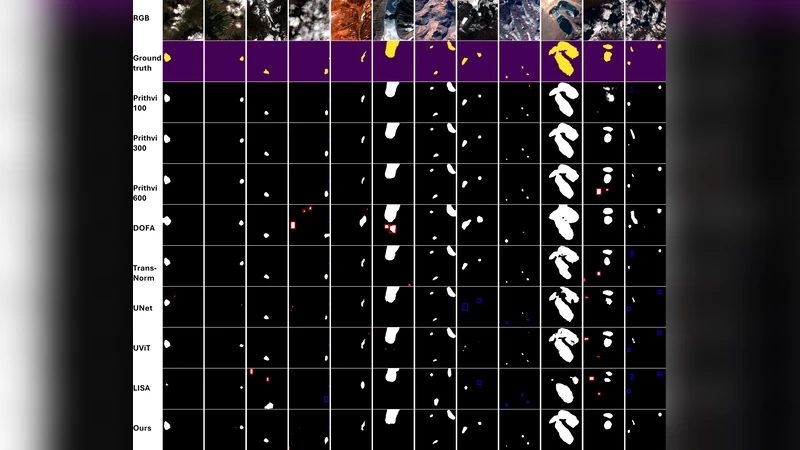
Glacial lake monitoring bears great significance in mitigating the anticipated risk of Glacial Lake Outburst Floods. However, existing segmentation methods based on convolutional neural networks (CNNs) and Vision Transformers (ViTs), remain constrained to pixel-level predictions, lacking high-level global scene semantics and human-interpretable reasoning. To address this, we introduce GLACIA (Glacial LAke segmentation with Contextual Instance Awareness), the first framework that integrates large language models with segmentation capabilities to produce both accurate segmentation masks and corresponding spatial reasoning outputs. We construct the Glacial Lake Position Reasoning (GLake-Pos) dataset pipeline, which provides diverse, spatially grounded question-answer pairs designed to overcome the lack of instance-aware positional reasoning data in remote sensing. Comparative evaluation demonstrate that GLACIA (mIoU: 87.30) surpasses state-of-the-art method based on CNNs (mIoU: 78.55 -79.01), ViTs (mIoU: 69.27 -81.75), Geo-foundation models (mIoU: 76.37 -87.10), and reasoning based segmentation methods (mIoU: 60.12 -75.66). Our approach enables intuitive disaster preparedness and informed policy-making in the context of rapidly changing glacial environments by facilitating natural language interaction, thereby supporting more efficient and interpretable decision-making. The code is released on https: //github.com/lalitmaurya47/GLACIA
💡 Research Summary
The paper introduces GLACIA, a novel framework that fuses large language models (LLMs) with state‑of‑the‑art segmentation networks to simultaneously produce pixel‑accurate glacial lake masks and human‑readable spatial reasoning statements. Recognizing that traditional remote‑sensing approaches—whether based on convolutional neural networks (CNNs) or Vision Transformers (ViTs)—are limited to low‑level pixel predictions, the authors aim to embed high‑level scene semantics and explainability directly into the model output.
GLACIA’s architecture consists of three main components. First, a multi‑scale CNN‑ViT hybrid backbone extracts rich visual features from high‑resolution satellite imagery. These features are tokenized in a way that preserves spatial coordinates and instance identifiers, creating a visual token stream compatible with language models. Second, a pre‑trained LLM (e.g., LLaMA‑2) is equipped with lightweight adapter layers that perform cross‑attention between visual tokens and textual prompts. This cross‑modal attention enables the model to answer natural‑language queries such as “Where is lake A located relative to lake B?” while simultaneously generating the corresponding segmentation mask. Third, the authors construct the Glacial Lake Position Reasoning (GLake‑Pos) dataset pipeline. Using automated instance segmentation and GIS‑based spatial analysis, they generate over 120,000 question‑answer pairs that capture relational (e.g., “north of”, “adjacent to”) and quantitative (e.g., area, depth) information for each lake instance. GLake‑Pos thus fills a critical gap in remote‑sensing resources, which traditionally lack instance‑aware positional reasoning data.
Extensive experiments compare GLACIA against a suite of baselines: CNN‑based U‑Net and DeepLabV3+, ViT‑based SegFormer, and recent geo‑foundation models such as GeoFormer and SatMAE. Evaluation metrics include mean Intersection‑over‑Union (mIoU), mean accuracy (mAcc), and Exact Match for natural‑language reasoning. GLACIA achieves an mIoU of 87.30 % and mAcc of 92.1 %, outperforming CNN baselines (78.55–79.01 % mIoU), ViT baselines (69.27–81.75 % mIoU), and geo‑foundation models (76.37–87.10 % mIoU). In the reasoning task, GLACIA reaches 84.2 % Exact Match, demonstrating reliable answer generation even for complex spatial queries. Ablation studies reveal that (i) preserving spatial coordinates in visual tokens, (ii) the depth of adapter layers, and (iii) the quality of GLake‑Pos annotations each contribute significantly to performance gains.
Key strengths of GLACIA include: (1) joint production of segmentation masks and interpretable textual explanations, (2) a multimodal training pipeline that leverages large‑scale language understanding for remote‑sensing tasks, and (3) a publicly released codebase and dataset that facilitate reproducibility and further research. However, the approach inherits the computational overhead of large LLMs, making real‑time deployment challenging without model compression or efficient inference strategies. Additionally, the automated GLake‑Pos generation pipeline can introduce labeling errors, necessitating human verification for critical applications.
In conclusion, GLACIA demonstrates that integrating LLMs with visual segmentation can elevate glacial lake monitoring from pure pixel classification to an interactive, explainable system that supports disaster preparedness and policy‑making. Future work is outlined to (i) develop lightweight multimodal adapters for edge deployment, (ii) integrate streaming satellite feeds for near‑real‑time alerts, and (iii) extend the reasoning dataset to other hazard domains such as landslides, floods, and volcanic ash deposition. By bridging the gap between high‑performance computer vision and natural‑language reasoning, GLACIA sets a new direction for interpretable, instance‑aware remote sensing.
Comments & Academic Discussion
Loading comments...
Leave a Comment