Chain-of-thought (CoT) reasoning has been highly successful in solving complex tasks in natural language processing, and recent multimodal large language models (MLLMs) have extended this paradigm to video reasoning. However, these models typically build on lengthy reasoning chains and large numbers of input visual tokens. Motivated by empirical observations from our benchmark study, we hypothesize that concise reasoning combined with a reduced set of visual tokens can be sufficient for effective video reasoning. To evaluate this hypothesis, we design and validate an efficient post-training and inference framework that enhances a video MLLM's reasoning capability. Our framework enables models to operate on compressed visual tokens and generate brief reasoning traces prior to answering. The resulting models achieve substantially improved inference efficiency, deliver competitive performance across diverse benchmarks, and avoid reliance on manual CoT annotations or supervised fine-tuning. Collectively, our results suggest that long, human-like CoT reasoning may not be necessary for general video reasoning, and that concise reasoning can be both effective and efficient. Our code will be released at https://github.com/LaVi-Lab/Rethink_CoT_Video.
Deep Dive into Rethinking Chain-of-Thought Reasoning for Videos.
Chain-of-thought (CoT) reasoning has been highly successful in solving complex tasks in natural language processing, and recent multimodal large language models (MLLMs) have extended this paradigm to video reasoning. However, these models typically build on lengthy reasoning chains and large numbers of input visual tokens. Motivated by empirical observations from our benchmark study, we hypothesize that concise reasoning combined with a reduced set of visual tokens can be sufficient for effective video reasoning. To evaluate this hypothesis, we design and validate an efficient post-training and inference framework that enhances a video MLLM’s reasoning capability. Our framework enables models to operate on compressed visual tokens and generate brief reasoning traces prior to answering. The resulting models achieve substantially improved inference efficiency, deliver competitive performance across diverse benchmarks, and avoid reliance on manual CoT annotations or supervised fine-tuning
Rethinking Chain-of-Thought Reasoning for Videos
Yiwu Zhong1, Zi-Yuan Hu1, Yin Li2, Liwei Wang1*
1The Chinese University of Hong Kong, 2University of Wisconsin-Madison
Abstract
Chain-of-thought (CoT) reasoning has been highly success-
ful in solving complex tasks in natural language processing,
and recent multimodal large language models (MLLMs)
have extended this paradigm to video reasoning. However,
these models typically build on lengthy reasoning chains
and large numbers of input visual tokens.
Motivated by
empirical observations from our benchmark study, we hy-
pothesize that concise reasoning combined with a reduced
set of visual tokens can be sufficient for effective video rea-
soning. To evaluate this hypothesis, we design and validate
an efficient post-training and inference framework that en-
hances a video MLLM’s reasoning capability. Our frame-
work enables models to operate on compressed visual to-
kens and generate brief reasoning traces prior to answer-
ing. The resulting models achieve substantially improved
inference efficiency, deliver competitive performance across
diverse benchmarks, and avoid reliance on manual CoT an-
notations or supervised fine-tuning. Collectively, our re-
sults suggest that long, human-like CoT reasoning may not
be necessary for general video reasoning, and that concise
reasoning can be both effective and efficient.
Our code
will be released at https://github.com/LaVi-
Lab/Rethink_CoT_Video.
1. Introduction
Chain-of-Thought (CoT) [61, 80] aims to solve complex
tasks by generating explicit, step-by-step intermediate rea-
soning traces before producing a final answer.
CoT has
been a key driver of the strong reasoning capabilities in
latest large language models (LLMs) [15, 19].
Building
on this success, several recent efforts [12, 18, 59, 68, 71]
have extended CoT to multimodal large language models
(MLLMs), demonstrating improved reasoning over visual
inputs, including both images and videos.
Despite its success in vision, CoT reasoning in MLLMs
incurs major overhead in both inference and training. On
the inference side, visual inputs, especially videos, often
*Corresponding author.
…
…
Input Video Tokens
“
Let me think about …
Hmm … Wait … Oh, I see …
… ”
Prefilling Phrase
Decoding Phrase
…
…
…
……
LLM
Input Video Tokens
“
This video shows … So …
… ”
…
…
…
……
CoT
Reason
Concise
Reason
LLM
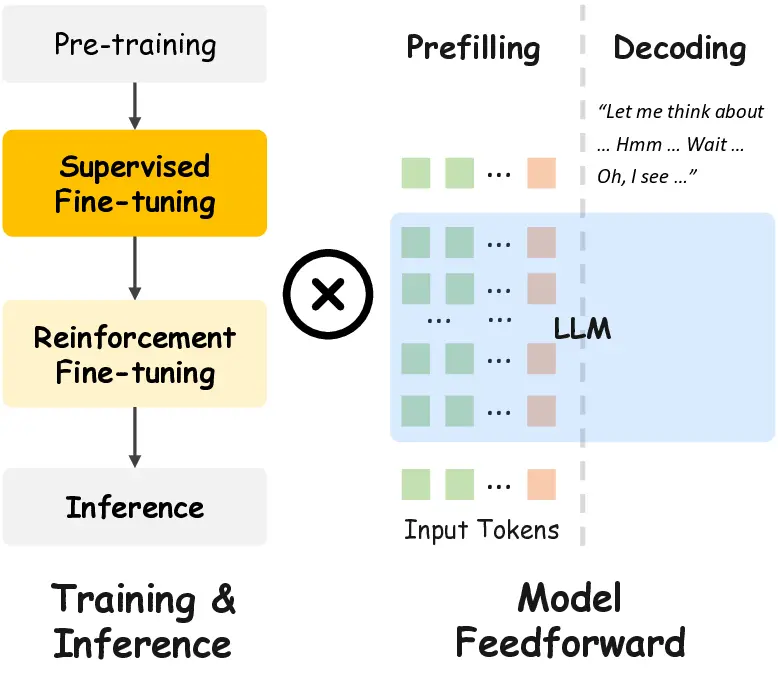
Figure 1. CoT Reasoning, with dense prefilling and lengthy de-
coding, incurs substatial computation load at both training and in-
ference. In contrast, Concise Reasoning coupled with token com-
pression is significantly more efficient, thanks to sparse prefilling
and concise decoding.
expand into thousands of visual tokens with high redun-
dancy, while CoT produces long reasoning sequences. To-
gether, these factors compound to sharply increased mem-
ory usage, compute cost, and carbon footprint during de-
ployment. Additionally, CoT training relies on supervised
fine-tuning (SFT) with heavily-labeled reasoning traces,
followed by reinforcement learning (RL) over long se-
quences [4, 12, 18, 49, 59, 68, 71, 76]. This pipeline not
only requires costly annotation, but also leads to prolonged
training cycles.
In this paper, we aim to reduce the inference and train-
ing overhead of reasoning-oriented video MLLMs. With a
Transformer-based architecture (Fig. 1), this overhead can
be decomposed into: (1) the cost of decoding phrase, which
scales with the number of output tokens for reasoning and
the total number of input tokens, and (2) the cost of pre-
filling phrase, which is determined by the number of input
tokens. Therefore, reducing CoT overhead requires either
shortening the output chain, which promotes more concise
reasoning, or decreasing the number of input tokens, which
is dominated by redundant visual tokens and can be reduced
1
arXiv:2512.09616v1 [cs.CV] 10 Dec 2025
via token compression [3, 42, 52, 79, 86]. With this intu-
ition, we conduct a systematic benchmark of MLLMs with
and without CoT across a suite of video datasets, covering
general, long-form, and complex video understanding tasks.
Our benchmark leads to several surprising observations.
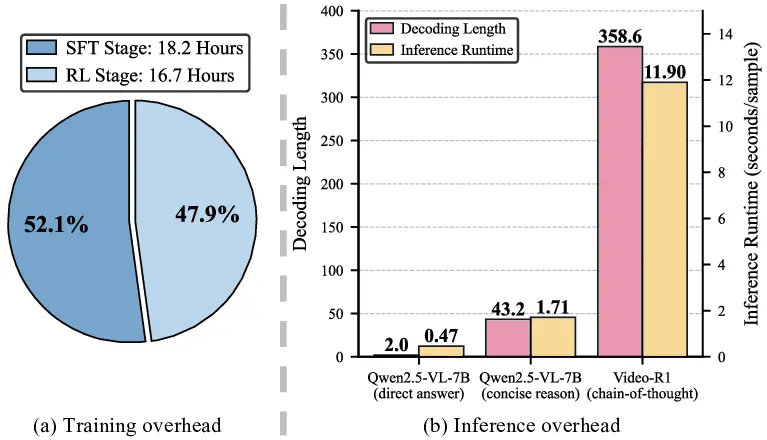
First, despite the overhead, adding CoT yields only modest
gains over the base pre-trained MLLM using direct answer-
ing. Indeed, we observe that CoT outputs frequently con-
tain human-like “pondering” patterns (e.g., “Hmm,” “Let’s
think,” or “Wait”) that contribute little to reasoning. Sec-
ond, prompting the base pre-trained MLLM to generate
concise reasoning chains leads to a major performance drop,
significantly worse than direct answering. We conjecture
that the model possesses the necessary knowledge to an-
swer the questions, yet is not well aligned with the concise
reasoning paradigm. Third, we find that token compres-
sion, although previously shown to be effective for video
MLLMs [86], causes notably larger performance degrada-
tion when the model i
…(Full text truncated)…
This content is AI-processed based on ArXiv data.