📝 Original Info
- Title: STACHE: Local Black-Box Explanations for Reinforcement Learning Policies
- ArXiv ID: 2512.09909
- Date: 2025-12-10
- Authors: ** - Andrew Elashkin - Orna Grumberg **
📝 Abstract
Reinforcement learning agents often behave unexpectedly in sparse-reward or safetycritical environments, creating a strong need for reliable debugging and verification tools. In this paper, we propose STACHE, a comprehensive framework for generating local, black-box explanations for an agent's specific action within discrete Markov games. Our method produces a Composite Explanation consisting of two complementary components: (1) a Robustness Region, the connected neighborhood of states where the agent's action remains invariant, and (2) Minimal Counterfactuals, the smallest state perturbations required to alter that decision. By exploiting the structure of factored state spaces, we introduce an exact, search-based algorithm that circumvents the fidelity gaps of surrogate models. Empirical validation on Gymnasium environments demonstrates that our framework not only explains policy actions, but also effectively captures the evolution of policy logic during training -from erratic, unstable behavior to optimized, robust strategies -providing actionable insights into agent sensitivity and decision boundaries.
💡 Deep Analysis
Deep Dive into STACHE: Local Black-Box Explanations for Reinforcement Learning Policies.
Reinforcement learning agents often behave unexpectedly in sparse-reward or safetycritical environments, creating a strong need for reliable debugging and verification tools. In this paper, we propose STACHE, a comprehensive framework for generating local, black-box explanations for an agent’s specific action within discrete Markov games. Our method produces a Composite Explanation consisting of two complementary components: (1) a Robustness Region, the connected neighborhood of states where the agent’s action remains invariant, and (2) Minimal Counterfactuals, the smallest state perturbations required to alter that decision. By exploiting the structure of factored state spaces, we introduce an exact, search-based algorithm that circumvents the fidelity gaps of surrogate models. Empirical validation on Gymnasium environments demonstrates that our framework not only explains policy actions, but also effectively captures the evolution of policy logic during training -from erratic, unstab
📄 Full Content
STACHE: Local Black-Box Explanations for
Reinforcement Learning Policies
Andrew Elashkin and Orna Grumberg
Faculty of Computer Science, Technion – Israel Institute of Technology
Abstract
Reinforcement learning agents often behave unexpectedly in sparse-reward or safety-
critical environments, creating a strong need for reliable debugging and verification tools.
In this paper, we propose STACHE, a comprehensive framework for generating local,
black-box explanations for an agent’s specific action within discrete Markov games. Our
method produces a Composite Explanation consisting of two complementary components:
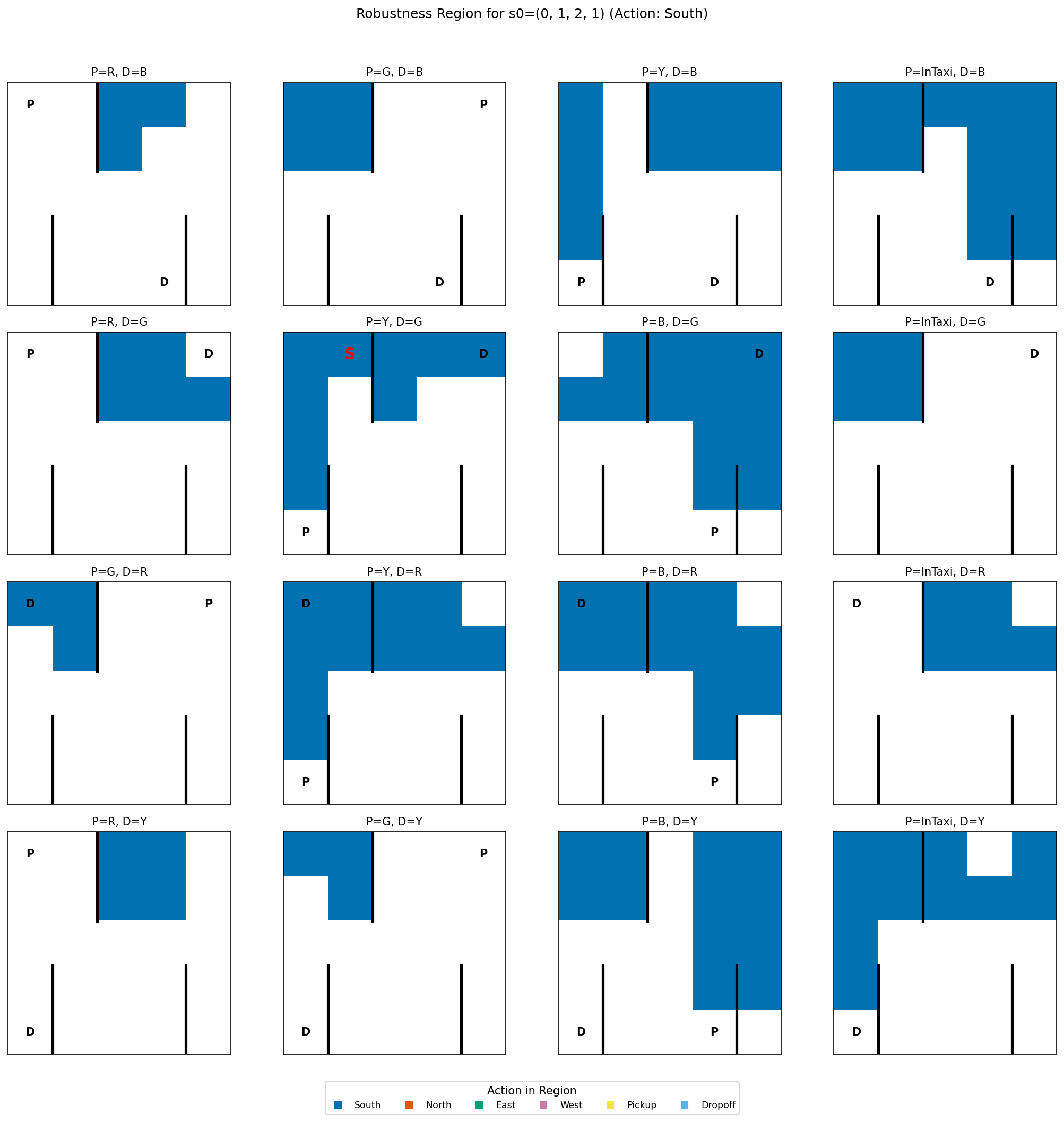
(1) a Robustness Region, the connected neighborhood of states where the agent’s action
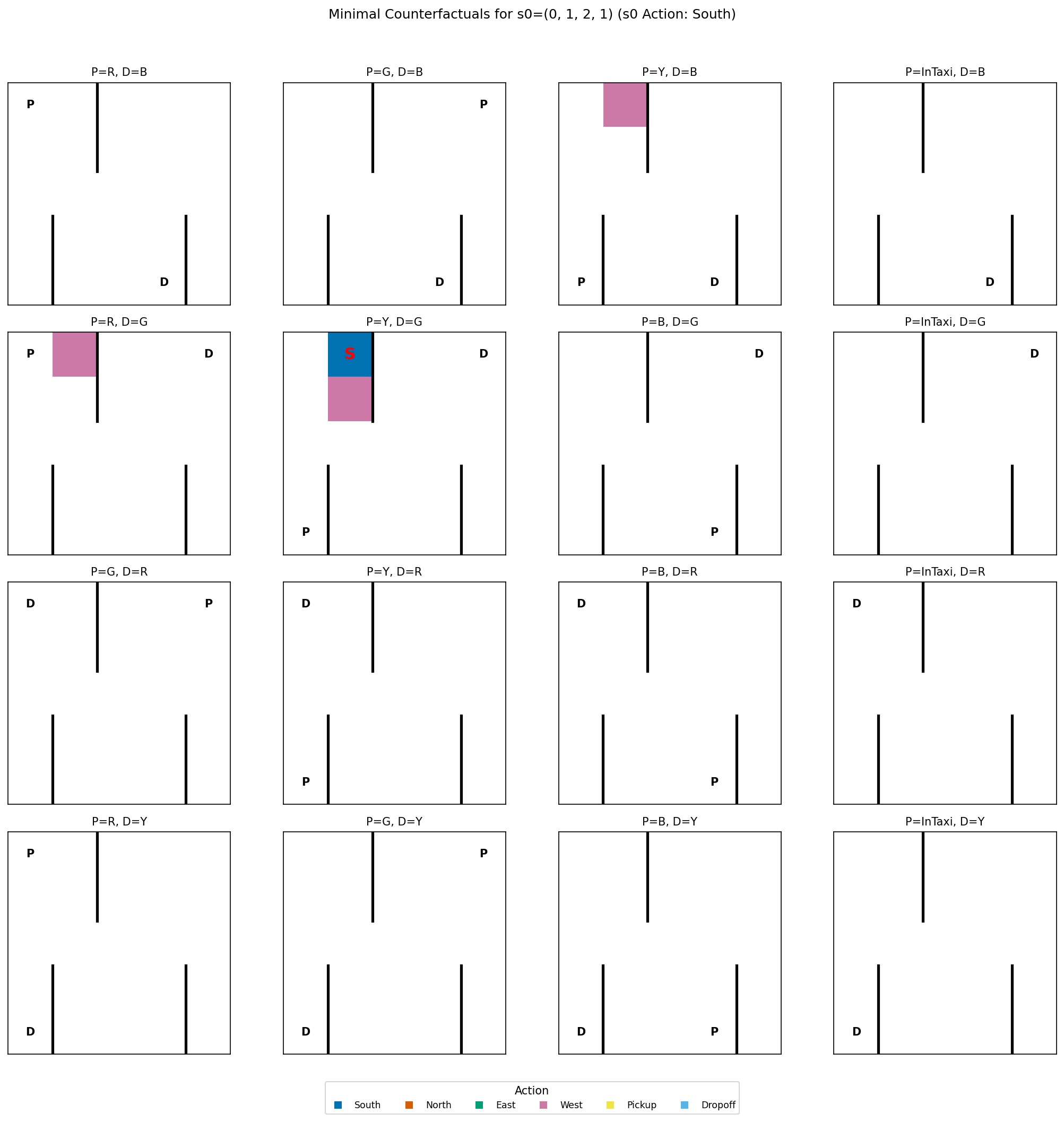
remains invariant, and (2) Minimal Counterfactuals, the smallest state perturbations
required to alter that decision. By exploiting the structure of factored state spaces,
we introduce an exact, search-based algorithm that circumvents the fidelity gaps of
surrogate models. Empirical validation on Gymnasium environments demonstrates that
our framework not only explains policy actions, but also effectively captures the evolution
of policy logic during training — from erratic, unstable behavior to optimized, robust
strategies — providing actionable insights into agent sensitivity and decision boundaries.
1
Introduction
Despite the impressive advances made by deep reinforcement learning (RL) agents, their
decision-making processes remain opaque (Cheng et al., 2025; Qing et al., 2022). This
"black-box" nature poses serious concerns for settings where trust and reliability are critical.
Deploying RL agents requires ensuring they make decisions for the right reasons, yet standard
metrics like cumulative reward do not reveal the logic behind individual actions (Milani
et al., 2022).
While much research focuses on explaining global policy behavior or summarizing trajec-
tories, there are critical scenarios where explaining a single action is paramount. For instance,
an agent that generally performs well might make a sudden, catastrophic error—such as a
taxi agent turning into a wall. Understanding the precise cause of such a decision requires
local explainability methods that can isolate the specific state factors responsible.
In this paper, we address this challenge by establishing a framework for Composite
Explanations. We argue that to fully understand an action a taken in state s, one must
answer two questions: "How stable is this decision?" and "What would make it change?".
To this end, we combine two analytical constructs:
1
arXiv:2512.09909v1 [cs.LG] 10 Dec 2025
• Robustness Regions: The set of states in the local neighborhood of s where the
agent’s policy remains invariant. This quantifies stability and reveals which factors the
agent is ignoring (robustness) versus which it is strictly adhering to.
• Minimal Counterfactuals: The smallest perturbations to s that trigger a change
in action. This identifies the decision boundary and the specific features the agent is
most sensitive to.
We make three main contributions: (1) We formalize a model-agnostic framework for local
explanations in discrete Markov games, integrating Robustness Regions—connected compo-
nents of invariant behavior—with Minimal Counterfactuals to simultaneously characterize
decision stability and sensitivity without relying on policy approximations; (2) We introduce
an exact, search-based algorithm that treats the policy purely as a black box—requiring no
access to internal weights or gradients—to compute these explanations with 100% fidelity
to the agent’s actual logic; and (3) We empirically demonstrate that our metrics effectively
track the evolution of policy logic, revealing that competent policies tend to develop narrow
stability regions for actions requiring precision (like pickups) while growing broader, more
stable regions for general navigation, offering a practical way to spot brittle behavior.
Implementation:
The complete code for STACHE, including all experiments and visual-
ization tools used in this paper, is available at https://github.com/aelashkin/STACHE.
2
Related Work
Our work sits at the intersection of Explainable AI (XAI), Reinforcement Learning (RL), and
robustness analysis. We distinguish our contribution by focusing on exact, model-agnostic
explanations for discrete environments, contrasting with approximation-based or white-box
approaches.
Explainable AI (XAI).
Early XAI focused on supervised learning. Feature attribution
methods like LIME (Ribeiro et al., 2016) and SHAP (Lundberg and Lee, 2017) approximate
local behavior via surrogate models or Shapley values. While powerful, these methods provide
scalar importance scores rather than concrete alternative states. Our work aligns with the
"counterfactual" branch of XAI (Wachter et al., 2017), which offers contrastive explanations
("Why P rather than Q?"), arguing these are more cognitively accessible to humans (Miller,
2019).
Explainable RL (XRL).
Global XRL methods often
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.