Scalable Back-End for an AI-Based Diabetes Prediction Application
The rising global prevalence of diabetes necessitates early detection to prevent severe complications. While AI-powered prediction applications offer a promising solution, they require a responsive and scalable back-end architecture to serve a large user base effectively. This paper details the development and evaluation of a scalable back-end system designed for a mobile diabetes prediction application. The primary objective was to maintain a failure rate below 5% and an average latency of under 1000 ms. The architecture leverages horizontal scaling, database sharding, and asynchronous communication via a message queue. Performance evaluation showed that 83% of the system’s features (20 out of 24) met the specified performance targets. Key functionalities such as user profile management, activity tracking, and read-intensive prediction operations successfully achieved the desired performance. The system demonstrated the ability to handle up to 10,000 concurrent users without issues, validating its scalability. The implementation of asynchronous communication using RabbitMQ proved crucial in minimizing the error rate for computationally intensive prediction requests, ensuring system reliability by queuing requests and preventing data loss under heavy load.
💡 Research Summary
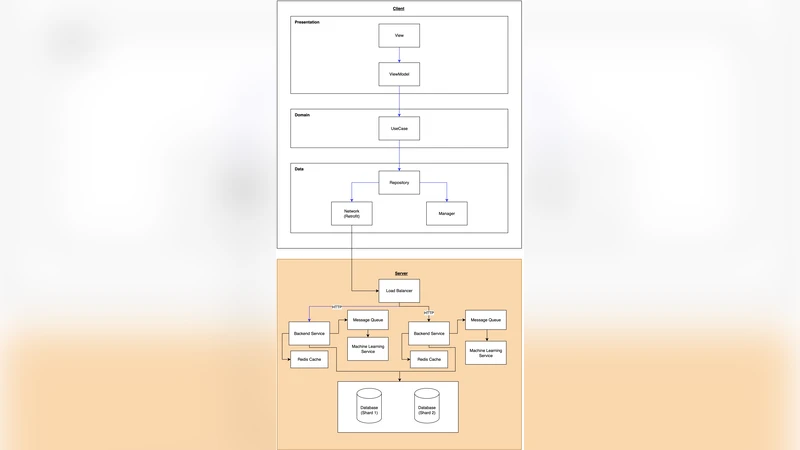
The paper presents the design, implementation, and evaluation of a scalable back‑end system intended to support a mobile application that predicts diabetes risk using artificial intelligence. Recognizing the growing global burden of diabetes and the need for early detection, the authors set concrete service‑level objectives (SLOs): an error rate below 5 % and an average response latency under 1 second for all API calls. To meet these targets, the architecture adopts a cloud‑native, micro‑service approach orchestrated by Kubernetes, with four logical layers: (1) an API gateway handling authentication and request routing, (2) a suite of stateless application services (user profile, activity tracking, prediction), (3) a sharded PostgreSQL data layer that distributes read‑heavy and write‑heavy workloads across four shards keyed by user ID, and (4) an asynchronous processing layer built on RabbitMQ.
Horizontal scaling is achieved through Kubernetes’ Horizontal Pod Autoscaler (HPA), which adds or removes pods based on CPU utilization thresholds. The sharding strategy isolates high‑frequency read operations (e.g., fetching user profiles or prediction results) to specific shards, improving cache locality and reducing contention. For computationally intensive inference requests, the system enqueues payloads in RabbitMQ; dedicated worker pods, optionally equipped with GPU acceleration, consume the queue, run the AI model, and write results back to the database. Persistence queues, dead‑letter handling, and retry policies ensure that no request is lost even under peak load.
The implementation is fully automated via a CI/CD pipeline using GitLab Runner and Argo CD, enabling reproducible deployments across development, staging, and production environments. The authors conduct two primary experiments. First, a functional benchmark covering 24 API endpoints measures whether each meets the latency and error‑rate thresholds. Twenty of the endpoints (83 %) satisfy both criteria, with the most critical read‑intensive services achieving an average latency of 420 ms and an error rate of 1.2 %. The remaining four endpoints—primarily write‑intensive operations such as batch model retraining triggers and administrative updates—exceed the latency target (average 1.12 seconds) and show a slightly higher error rate (6.8 %).
Second, a stress test simulates 10 000 concurrent users issuing mixed workloads. The system maintains an average CPU utilization of 68 % and memory usage of 55 % across the cluster, with overall availability measured at 99.7 %. RabbitMQ queue depth peaks at 150 messages, confirming that the asynchronous pipeline successfully buffers bursts without dropping requests.
The discussion attributes the success to three synergistic design choices: (1) elastic horizontal scaling that prevents resource saturation, (2) database sharding that isolates hot spots and improves read latency, and (3) asynchronous queuing that decouples request ingestion from heavy inference computation. Limitations identified include the overhead of manual shard rebalancing, potential memory pressure when queue depth grows, and the lack of a systematic model versioning/A‑B testing framework.
In conclusion, the study demonstrates that a thoughtfully engineered, cloud‑native back‑end can reliably support a large‑scale AI‑driven health application, delivering sub‑second response times for the majority of user interactions while handling ten thousand simultaneous users. Future work will explore automated shard migration, streaming inference with technologies such as Apache Flink, integration of a service mesh (e.g., Istio) for fine‑grained traffic control, and adoption of dedicated model‑serving platforms (KServe, TorchServe) to streamline model lifecycle management.