📝 Original Info
- Title: Aerial Vision-Language Navigation with a Unified Framework for Spatial, Temporal and Embodied Reasoning
- ArXiv ID: 2512.08639
- Date: 2025-12-09
- Authors: Researchers from original ArXiv paper
📝 Abstract
Aerial Vision-and-Language Navigation (VLN) aims to enable unmanned aerial vehicles (UAVs) to interpret natural language instructions and navigate complex urban environments using onboard visual observation. This task holds promise for real-world applications such as low-altitude inspection, searchand-rescue, and autonomous aerial delivery. Existing methods often rely on panoramic images, depth inputs, or odometry to support spatial reasoning and action planning. These requirements increase system cost and integration complexity, thus hindering practical deployment for lightweight UAVs. We present a unified aerial VLN framework that operates solely on egocentric monocular RGB observations and natural language instructions. The model formulates navigation as a next-token prediction problem, jointly optimizing spatial perception, trajectory reasoning, and action prediction through prompt-guided multi-task learning. Moreover, we propose a keyframe selection strategy to reduce visual redundancy by retaining semantically informative frames, along with an action merging and label reweighting mechanism that mitigates long-tailed supervision imbalance and facilitates stable multi-task co-training. Extensive experiments on the Aerial VLN benchmark validate the effectiveness of our method. Under the challenging monocular RGB-only setting, our model achieves strong results across both seen and unseen environments. It significantly outperforms existing RGB-only baselines and narrows the performance gap with state-of-the-art panoramic RGB-D counterparts. Comprehensive ablation studies further demonstrate the contribution of our task design and architectural choices.
💡 Deep Analysis
Deep Dive into Aerial Vision-Language Navigation with a Unified Framework for Spatial, Temporal and Embodied Reasoning.
Aerial Vision-and-Language Navigation (VLN) aims to enable unmanned aerial vehicles (UAVs) to interpret natural language instructions and navigate complex urban environments using onboard visual observation. This task holds promise for real-world applications such as low-altitude inspection, searchand-rescue, and autonomous aerial delivery. Existing methods often rely on panoramic images, depth inputs, or odometry to support spatial reasoning and action planning. These requirements increase system cost and integration complexity, thus hindering practical deployment for lightweight UAVs. We present a unified aerial VLN framework that operates solely on egocentric monocular RGB observations and natural language instructions. The model formulates navigation as a next-token prediction problem, jointly optimizing spatial perception, trajectory reasoning, and action prediction through prompt-guided multi-task learning. Moreover, we propose a keyframe selection strategy to reduce visual redun
📄 Full Content
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021
1
Aerial Vision-Language Navigation with a Unified Framework
for Spatial, Temporal and Embodied Reasoning
Huilin Xu, Graduate Student Member, IEEE, Zhuoyang Liu, Graduate Student Member, IEEE,
Yixiang Luomei, Member, IEEE, and Feng Xu, Senior Member, IEEE
Abstract—Aerial Vision-and-Language Navigation (VLN) aims
to enable unmanned aerial vehicles (UAVs) to interpret natural
language instructions and navigate complex urban environments
using onboard visual observation. This task holds promise for
real-world applications such as low-altitude inspection, search-
and-rescue, and autonomous aerial delivery. Existing methods
often rely on panoramic images, depth inputs, or odometry to
support spatial reasoning and action planning. These require-
ments increase system cost and integration complexity, thus hin-
dering practical deployment for lightweight UAVs. We present a
unified aerial VLN framework that operates solely on egocentric
monocular RGB observations and natural language instructions.
The model formulates navigation as a next-token prediction
problem, jointly optimizing spatial perception, trajectory rea-
soning, and action prediction through prompt-guided multi-task
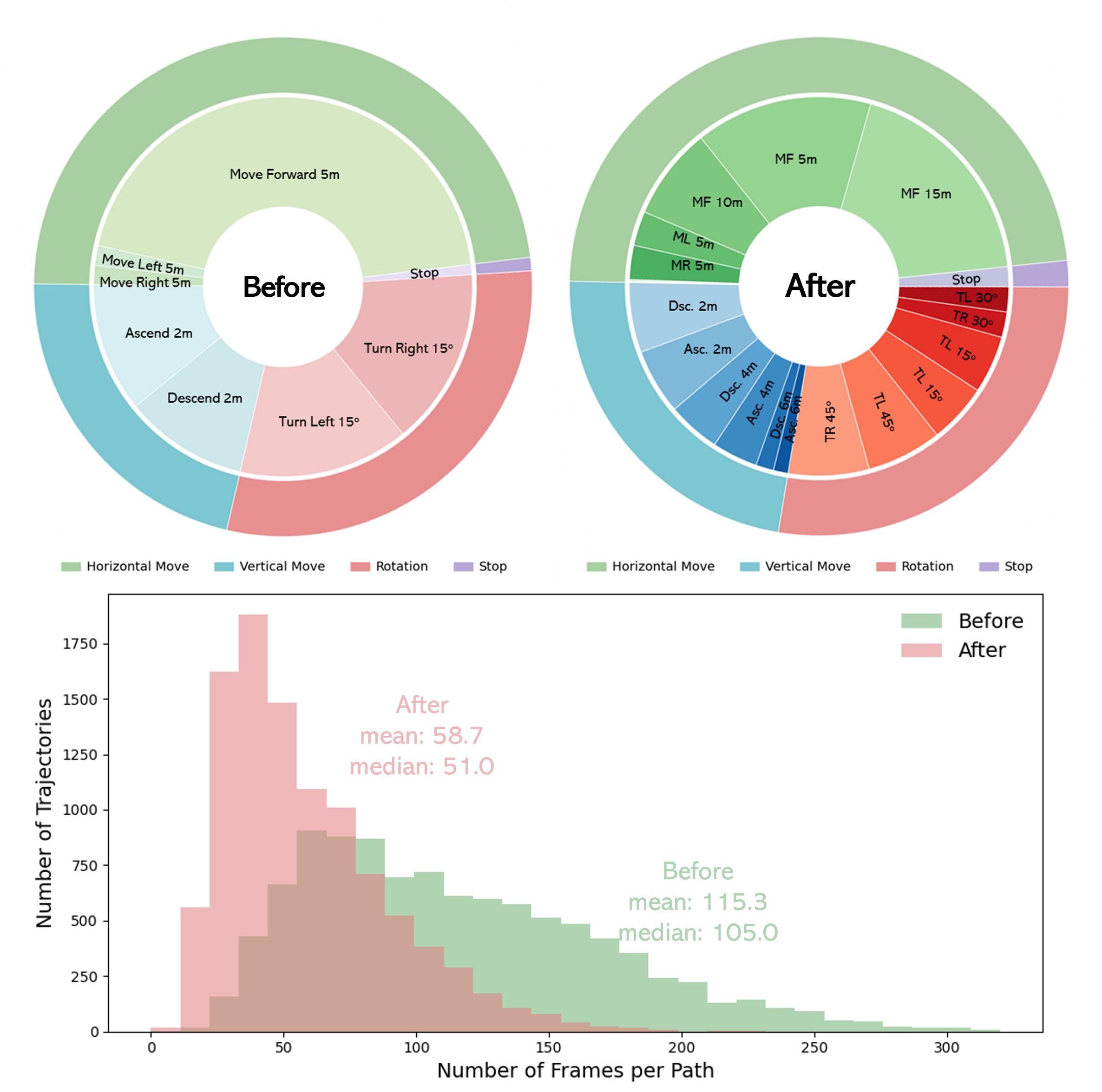
learning. Moreover, we propose a keyframe selection strategy to
reduce visual redundancy by retaining semantically informative
frames, along with an action merging and label reweighting
mechanism that mitigates long-tailed supervision imbalance and
facilitates stable multi-task co-training. Extensive experiments
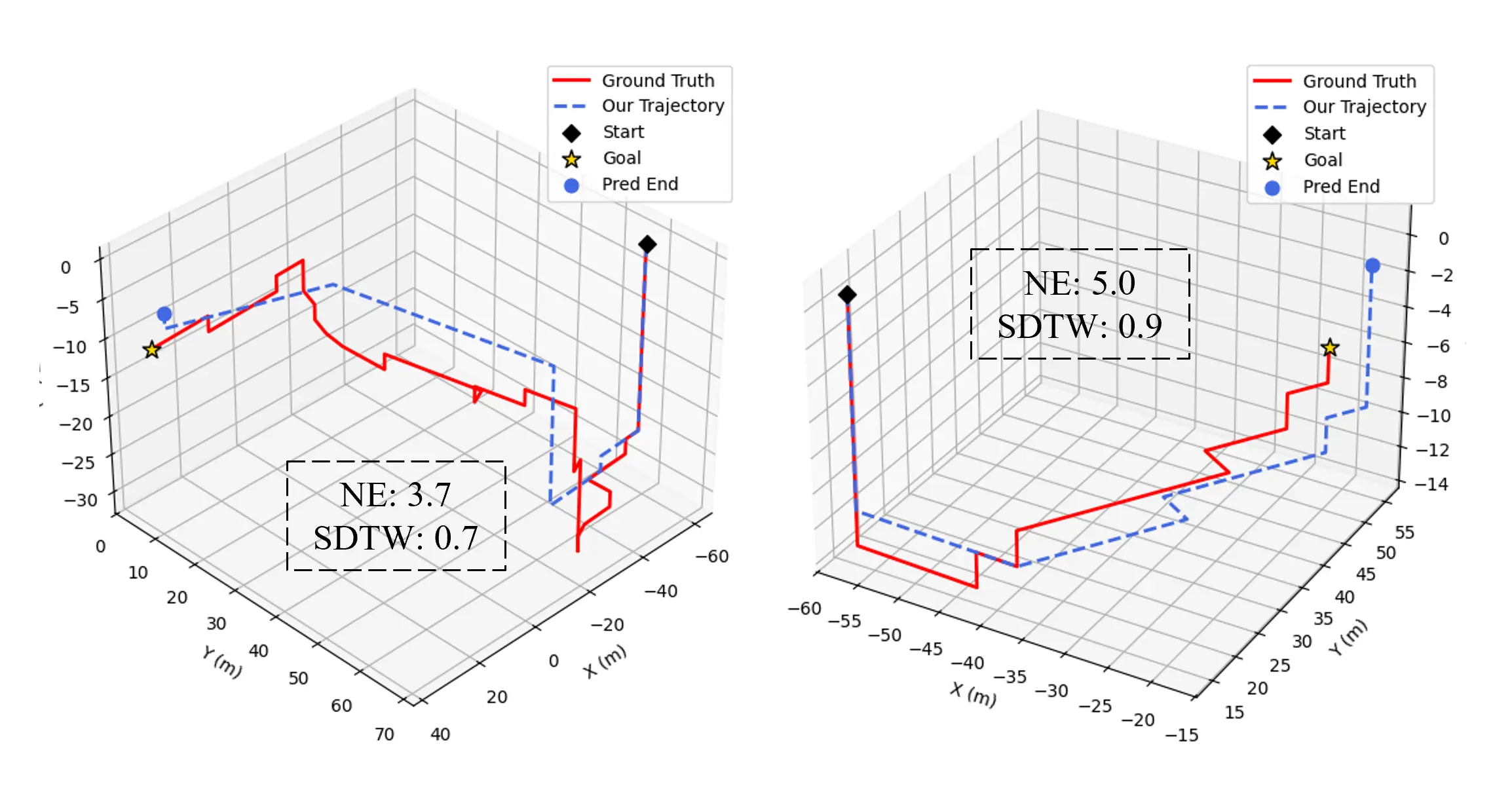
on the Aerial VLN benchmark validate the effectiveness of our
method. Under the challenging monocular RGB-only setting,
our model achieves strong results across both seen and unseen
environments. It significantly outperforms existing RGB-only
baselines and narrows the performance gap with state-of-the-art
panoramic RGB-D counterparts. Comprehensive ablation studies
further demonstrate the contribution of our task design and
architectural choices.
Index Terms—unmanned aerial vehicle (UAV), aerial naviga-
tion, Vision-and-Language Navigation (VLN)
I. INTRODUCTION
U
NMANNED Aerial Vehicle (UAV) has become an in-
dispensable tool in modern remote sensing applications,
playing a central role in infrastructure inspection, environ-
mental monitoring, and emergency response [1], [2]. Previous
research has largely focused on passive perception tasks,
including object detection [3], [4] and tracking [5], [6] from
aerial images or videos, without interaction with the world. In
contrast, aerial navigation tasks require the drone to perceive,
reason, and act in dynamic environments. Recently, aerial
Vision-and-Language Navigation (VLN) [7] has emerged as
a new paradigm, where drones follow high-level language
instructions to navigate the destination through 3D outdoor
environments. By leveraging natural language as a human-
centric interface, aerial VLN significantly reduces the reliance
on expert pilots, lowers the barrier of human-UAV interaction,
The authors are with the Key Laboratory for Information Science of
Electromagnetic Waves (Ministry of Education), School of Information Sci-
ence and Technology, Fudan University, Shanghai 200433, China (e-mail:
fengxu@fudan.edu.cn).
Fig. 1.
Aerial vision-language navigation. Left: A drone receives a natural-
language instruction along with egocentric visual observations and is required
to navigate to the destination in a complex outdoor environment. Right: This
task relies on the agent’s ability to maintain an accurate understanding of its
navigational situation, including estimating its current position, interpreting
its progress within the instruction, and determining the next movement
consistent with the described route. The example highlights these dimensions
of temporal and spatial reasoning, which are central to reliable long-horizon
aerial navigation.
and enables intuitive task specification in high-stakes scenar-
ios.
Recent works have explored the design of benchmarks and
datasets to facilitate research in aerial vision-and-language
navigation. AVDN [8] first proposed a dialogue-based setting
involving asynchronous interactions between a human com-
mander and a UAV agent. AerialVLN [7] introduced high-
fidelity city-scale simulations with diverse human-annotated
trajectories. CityNav [9] extended this line by leveraging real-
world urban reconstructions. OpenUAV [10] formulated aerial
VLN as full-trajectory prediction with human-in-the-loop eval-
uation, and OpenFly [11] scaled up scene and instruction
diversity via automatic generation. AeroDuo [12] explores
the collaborative setting with multi-agent instruction following
with altitude-aware role assignment. Moreover, CityEQA [13]
and 3D Open-EQA [14] have proposed embodied question
answering benchmarks to assess model’s perception and rea-
soning capabilities from aerial perspective. However, as illus-
trated in Fig. 1, aerial VLN requires an agent to continuously
integrate current
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.