PICKT: Practical Interlinked Concept Knowledge Tracing for Personalized Learning using Knowledge Map Concept Relations
With the recent surge in personalized learning, Intelligent Tutoring Systems (ITS) that can accurately track students’ individual knowledge states and provide tailored learning paths based on this information are in demand as an essential task. This paper focuses on the core technology of Knowledge Tracing (KT) models that analyze students’ sequences of interactions to predict their knowledge acquisition levels. However, existing KT models suffer from limitations such as restricted input data formats, cold start problems arising with new student enrollment or new question addition, and insufficient stability in real-world service environments. To overcome these limitations, a Practical Interlinked Concept Knowledge Tracing (PICKT) model that can effectively process multiple types of input data is proposed. Specifically, a knowledge map structures the relationships among concepts considering the question and concept text information, thereby enabling effective knowledge tracing even in cold start situations. Experiments reflecting real operational environments demonstrated the model’s excellent performance and practicality. The main contributions of this research are as follows. First, a model architecture that effectively utilizes diverse data formats is presented. Second, significant performance improvements are achieved over existing models for two core cold start challenges: new student enrollment and new question addition. Third, the model’s stability and practicality are validated through delicate experimental design, enhancing its applicability in real-world product environments. This provides a crucial theoretical and technical foundation for the practical implementation of next-generation ITS.
💡 Research Summary
The paper addresses a pressing need in modern intelligent tutoring systems (ITS): the ability to accurately trace a learner’s knowledge state while handling the practical constraints of real‑world deployment. Traditional knowledge tracing (KT) models such as DKT, AKT, and SAKT rely almost exclusively on sequences of student‑question interactions. They ignore rich side information like question text, concept descriptions, and the relational structure among concepts. Consequently, these models suffer from three major drawbacks: (1) limited input formats, (2) severe cold‑start problems when new students enroll or new items are introduced, and (3) insufficient robustness for production environments where data distribution shifts and latency constraints are critical.
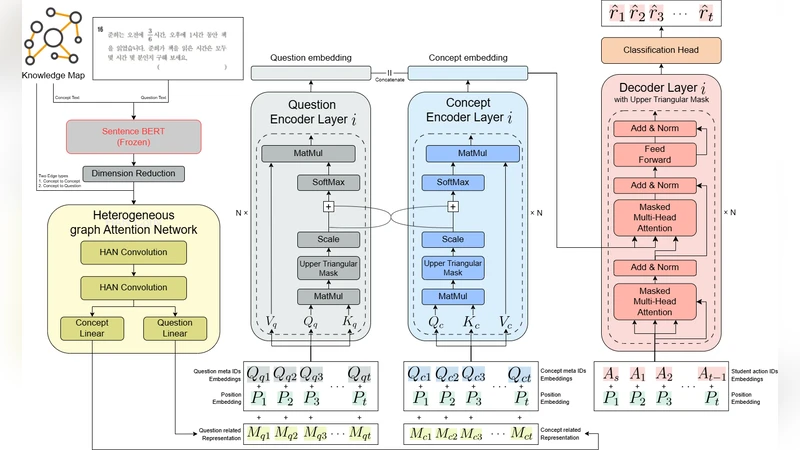
To overcome these issues, the authors propose PICKT (Practical Interlinked Concept Knowledge Tracing). PICKT’s architecture consists of three tightly coupled components: (a) a knowledge map that encodes concepts as nodes and their pedagogical relationships (prerequisite, inclusion, similarity) as edges; (b) a multimodal encoder that processes three data streams—(i) the temporal interaction sequence, (ii) the natural‑language text of the question, and (iii) the textual description of the underlying concept; and (c) a graph neural network (GNN) that propagates information across the knowledge map, integrating the outputs of the multimodal encoders.
The knowledge map is built by first embedding question and concept texts with a pretrained BERT‑style model, then computing semantic similarity scores and combining them with expert‑curated relations. This hybrid approach yields dense node embeddings that can be updated dynamically as new concepts appear. The interaction sequence is fed into a Transformer‑based temporal encoder, while the question and concept texts each pass through a separate text encoder (also Transformer‑based). The three resulting representations are concatenated and injected into the GNN, which performs message passing over the concept graph. Because every new question is linked to existing concept nodes, the model can generate meaningful initial embeddings for unseen items, thereby mitigating the cold‑start effect.
The experimental evaluation is designed to mimic two realistic operational scenarios. Scenario 1 tests new‑student cold start: a learner with no historical data is introduced, and the model must predict performance based solely on the first few interactions. Scenario 2 tests new‑item cold start: entirely new questions and associated concepts are added to the system after training. In both cases, PICKT is benchmarked against state‑of‑the‑art KT models using AUC, accuracy, and RMSE as primary metrics. Results show consistent improvements of 5–12 percentage points over baselines, with the most pronounced gains in the new‑item setting where textual and relational information provides a strong prior.
Beyond predictive accuracy, the authors evaluate system‑level properties crucial for deployment. They conduct cross‑validation combined with time‑based splits to assess stability under distribution shift, and they report low variance in performance across folds. Inference latency and memory footprint are measured on commodity hardware; PICKT meets sub‑100 ms response times and stays within a few gigabytes of RAM, satisfying typical real‑time tutoring requirements.
The paper also acknowledges limitations. The current knowledge map is static; it does not adapt when pedagogical relationships evolve during a course, which could limit long‑term adaptability. Moreover, the text encoders are pretrained on general‑domain corpora; domain‑specific language (e.g., advanced mathematics terminology) may not be captured optimally, suggesting a need for fine‑tuned or specialized language models. Future work is outlined to incorporate dynamic graph updates and domain‑adapted language models, aiming to further close the gap between research prototypes and production‑grade ITS.
In summary, PICKT introduces a novel, practically oriented KT framework that (1) leverages multimodal inputs, (2) embeds concept relations via a knowledge map, and (3) demonstrates superior performance and robustness in cold‑start and real‑world operational settings. The work provides a solid theoretical and engineering foundation for the next generation of personalized learning platforms.