📝 Original Info
- Title: 무선주파수 라디언스필드 기반 사전학습으로 실내 위치추정 일반화 혁신
- ArXiv ID: 2512.07309
- Date: 2025-12-08
- Authors: Guosheng Wang, Shen Wang, Lei Yang
📝 Abstract
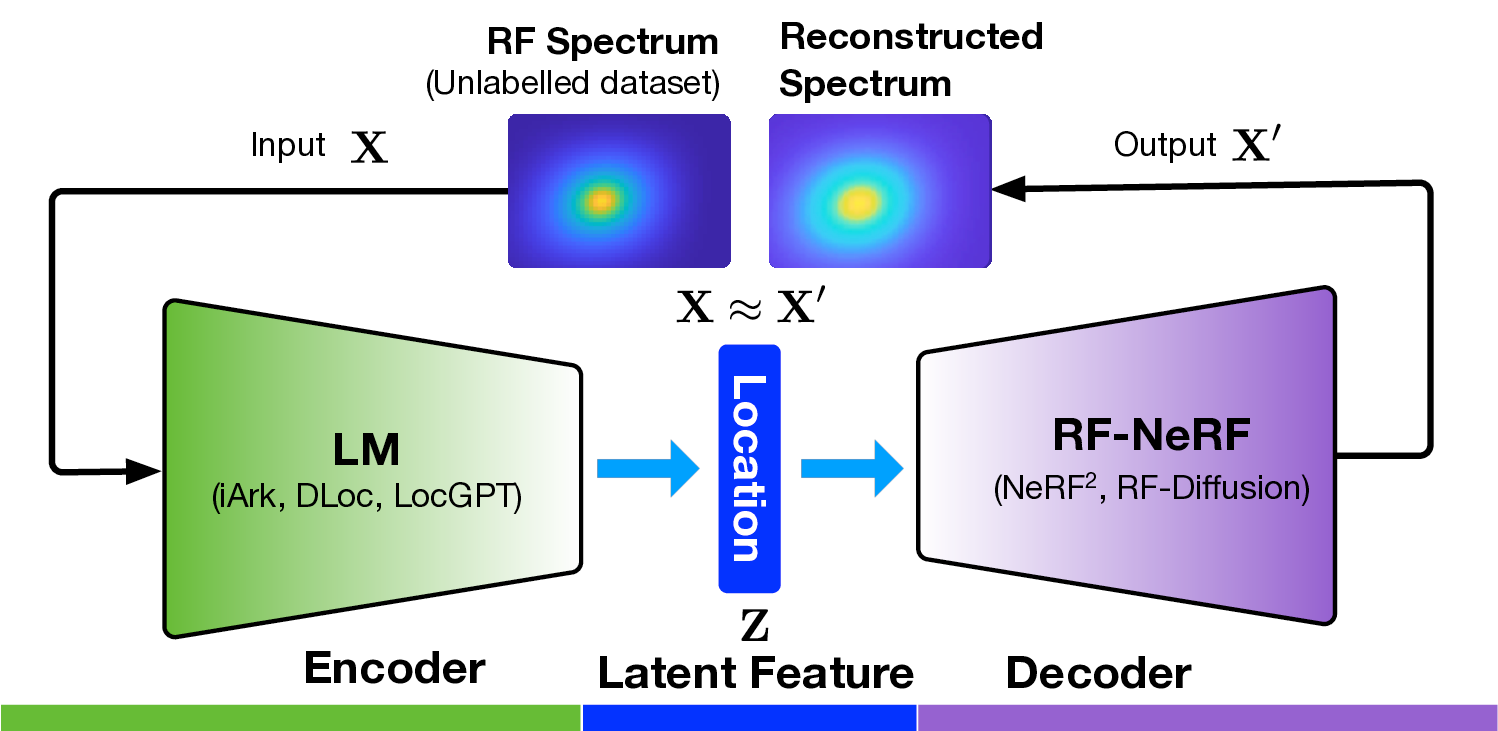
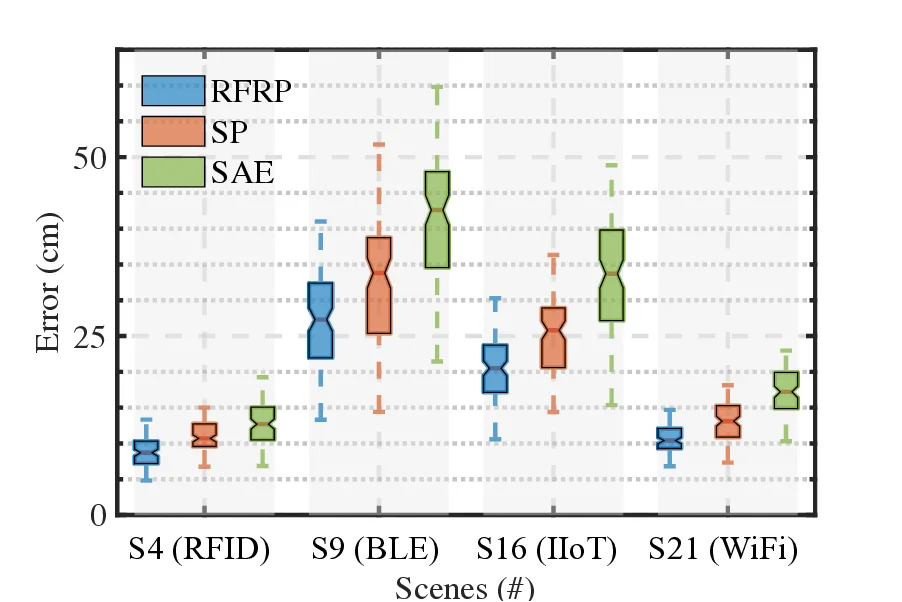
Radio frequency (RF)-based indoor localization offers significant promise for applications such as indoor navigation, augmented reality, and pervasive computing. While deep learning has greatly enhanced localization accuracy and robustness, existing localization models still face major challenges in cross-scene generalization due to their reliance on scene-specific labeled data. To address this, we introduce Radiance-Field Reinforced Pretraining (RFRP). This novel self-supervised pretraining framework couples a large localization model (LM) with a neural radio-frequency radiance field (RF-NeRF) in an asymmetrical autoencoder architecture. In this design, the LM encodes received RF spectra into latent, position-relevant representations, while the RF-NeRF decodes them to reconstruct the original spectra. This alignment between input and output enables effective representation learning using large-scale, unlabeled RF data, which can be collected continuously with minimal effort. To this end, we collected RF samples at 7,327,321 positions across 100 diverse scenes using four common wireless technologies-RFID, BLE, WiFi, and IIoT. Data from 75 scenes were used for training, and the remaining 25 for evaluation. Experimental results show that the RFRP-pretrained LM reduces localization error by over 40% compared to non-pretrained models and by 21% compared to those pretrained using supervised learning. Location (iArk, DLoc, LocGPT) LM RF-NeRF (NeRF 2 , RF-Diffusion) RF Spectrum (Unlabelled dataset
💡 Deep Analysis
Deep Dive into 무선주파수 라디언스필드 기반 사전학습으로 실내 위치추정 일반화 혁신.
Radio frequency (RF)-based indoor localization offers significant promise for applications such as indoor navigation, augmented reality, and pervasive computing. While deep learning has greatly enhanced localization accuracy and robustness, existing localization models still face major challenges in cross-scene generalization due to their reliance on scene-specific labeled data. To address this, we introduce Radiance-Field Reinforced Pretraining (RFRP). This novel self-supervised pretraining framework couples a large localization model (LM) with a neural radio-frequency radiance field (RF-NeRF) in an asymmetrical autoencoder architecture. In this design, the LM encodes received RF spectra into latent, position-relevant representations, while the RF-NeRF decodes them to reconstruct the original spectra. This alignment between input and output enables effective representation learning using large-scale, unlabeled RF data, which can be collected continuously with minimal effort. To this e
📄 Full Content
Radio frequency (RF)-based indoor localization estimates device positions by analyzing wireless signals received at base stations, enabling reliable tracking in environments where GPS is unavailable or unreliable. High-precision indoor localization supports a wide range of applications, including indoor navigation, augmented reality, location-aware pervasive computing, targeted advertising, and social networking. Consequently, the task of tracking IoT devices within built environments has become a growing area of commercial and academic interest, giving rise to a substantial body of research over the past two decades [1]- [14].
In the wake of the deep learning surge, recent studies [20]- [25] have demonstrated the transformative potential of deep learning-based localization models (LMs) over traditional algorithms, particularly in addressing challenges related to accuracy, robustness, and adaptability. These models reframe indoor localization as an optimization task: using radio frequency signals received at base stations to probabilistically infer the spatial coordinates of RF devices [1], [25]. This paradigm aligns naturally with the strengths of deep neural networks (DNNs), which excel at uncovering intricate patterns in high-dimensional data.
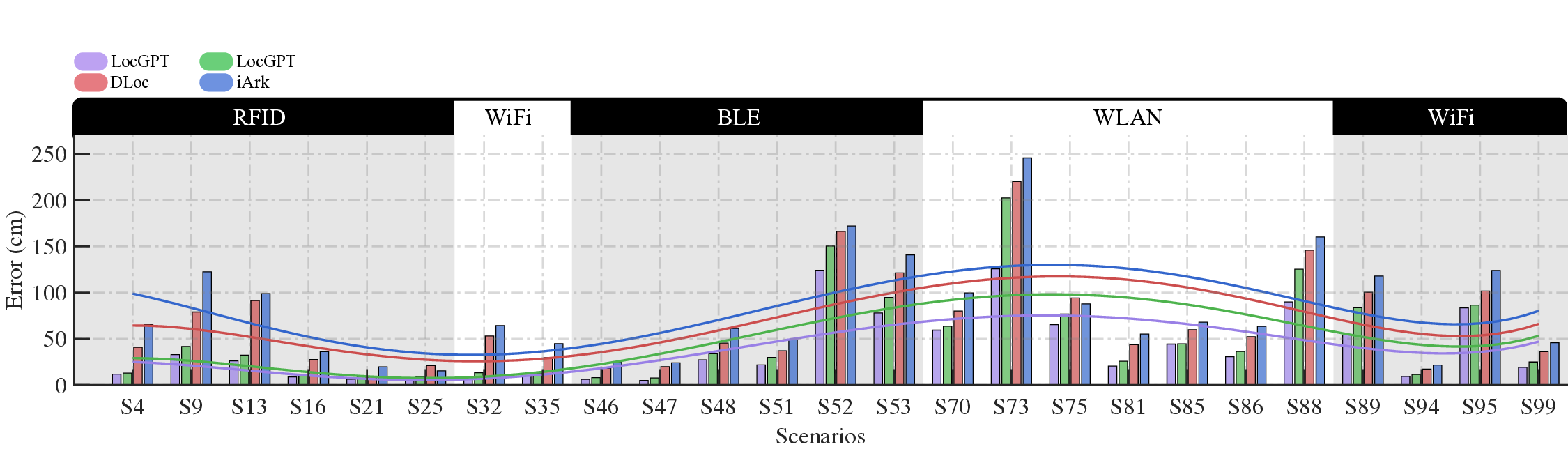
However, a key challenge persists: existing models exhibit poor cross-scene generalization, with performance closely tied to the spatial layouts and RF characteristics of their training environments. Models trained in one scene often suffer significant degradation when applied to unseen or dynamically changing settings, primarily due to their inability to extract and transfer invariant features across heterogeneous scenarios. To address this, recent work such as LocGPT [25] has explored pretraining large localization models (LMs) on aggregated multi-scene datasets. Yet, this pretraining method relies heavily on supervised learning, creating a major bottleneck-the need for extensive, high-quality position labels.
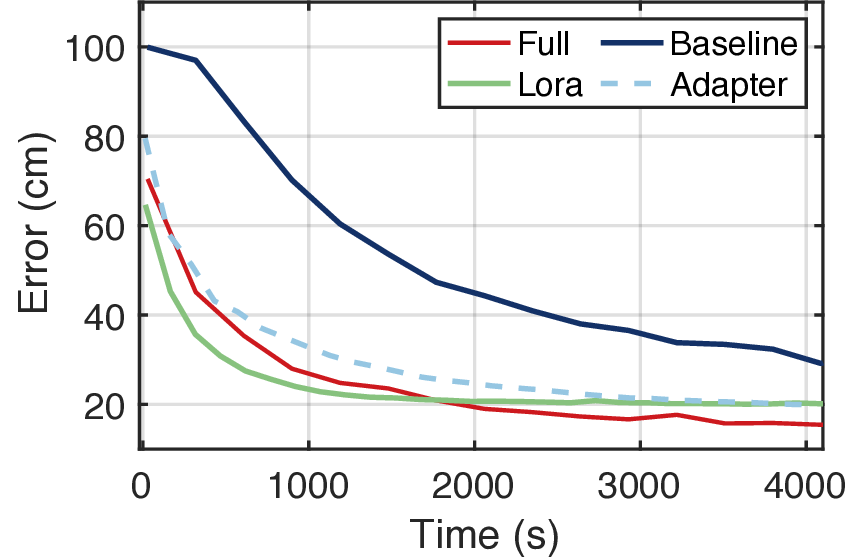
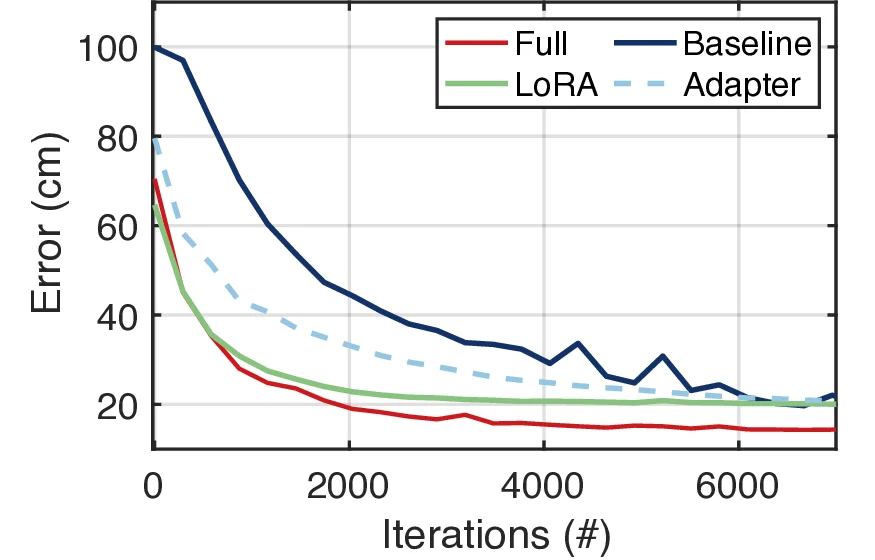
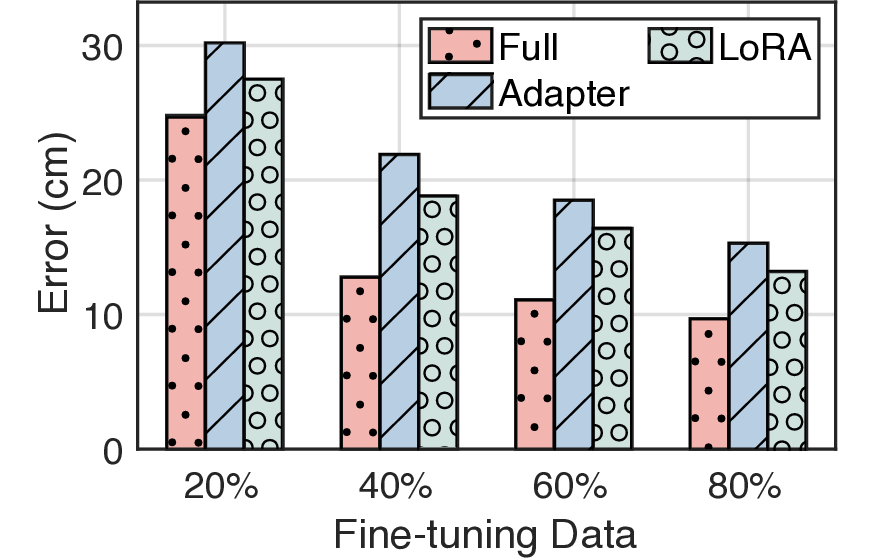
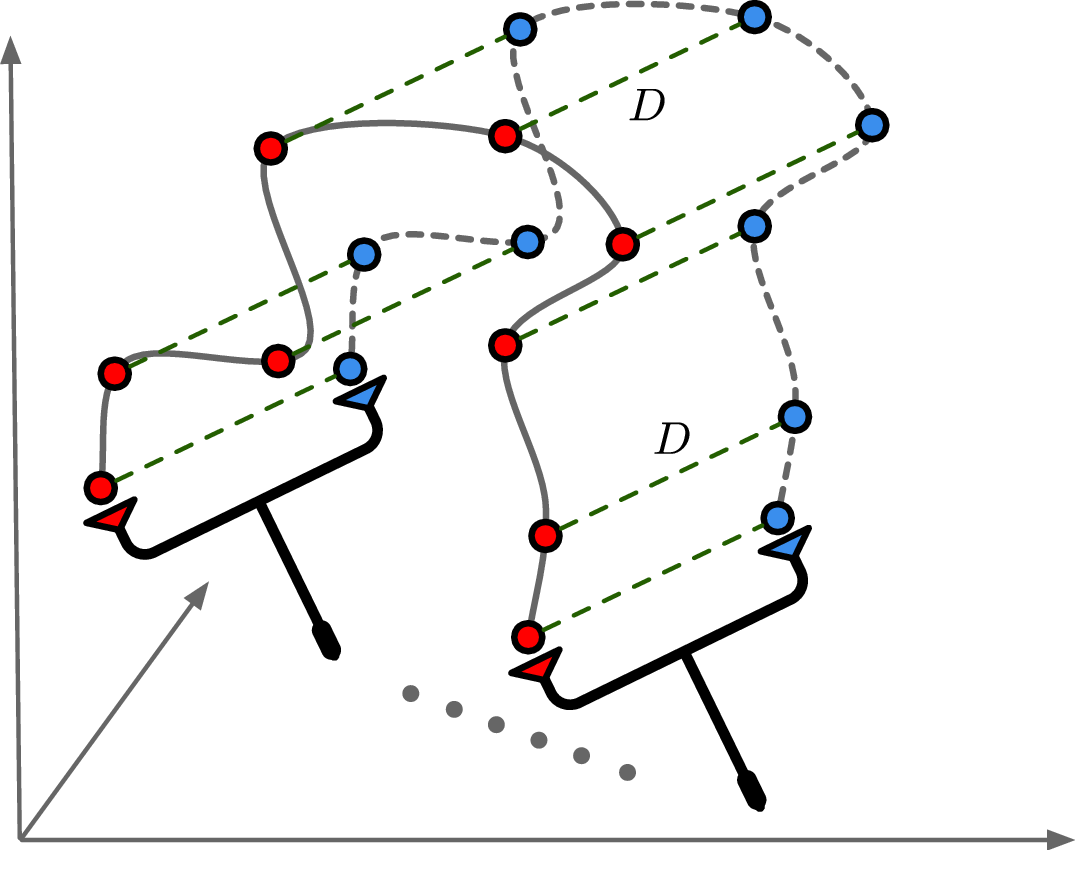
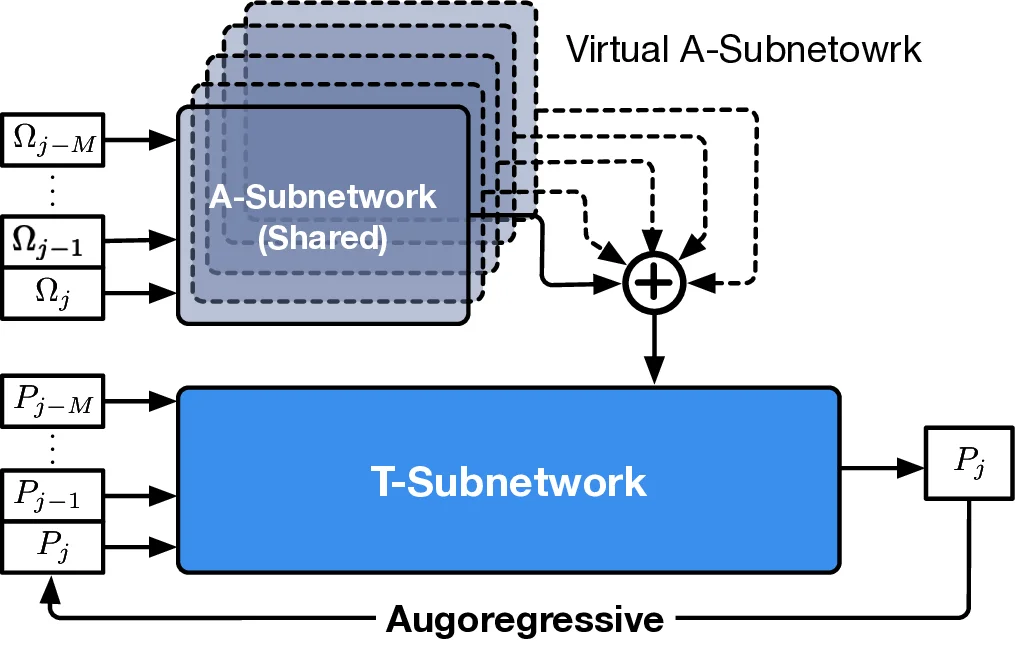
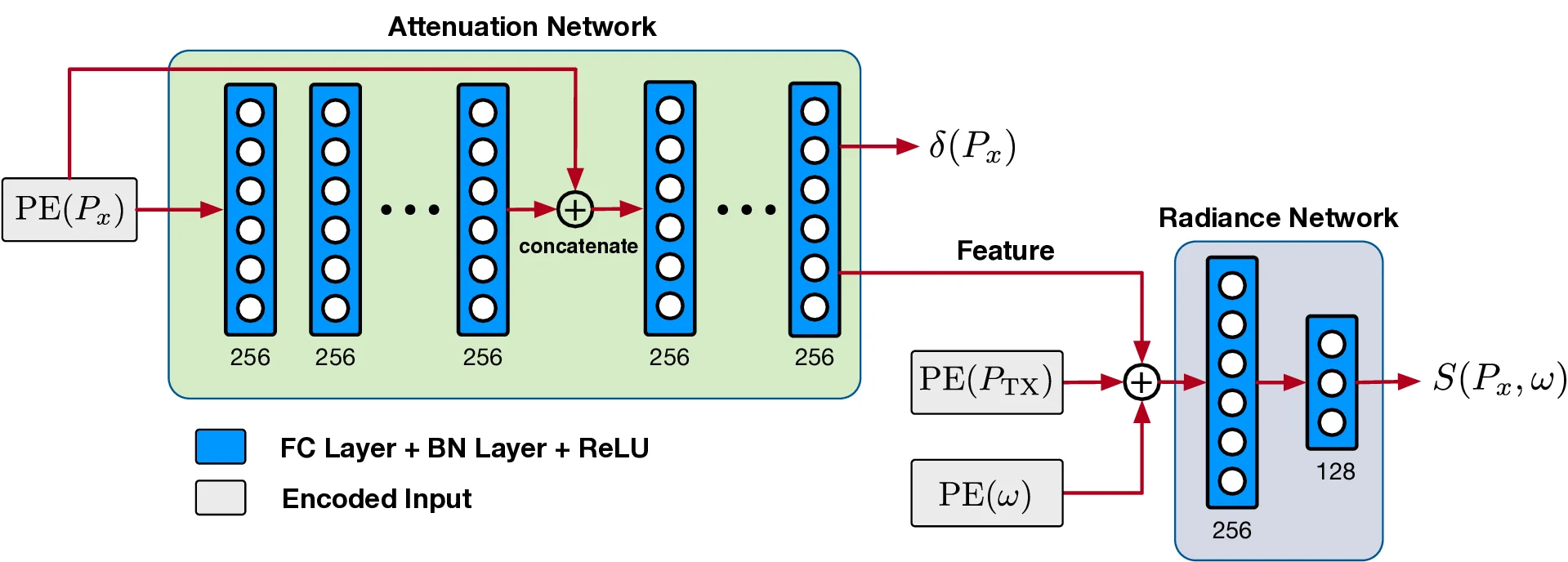
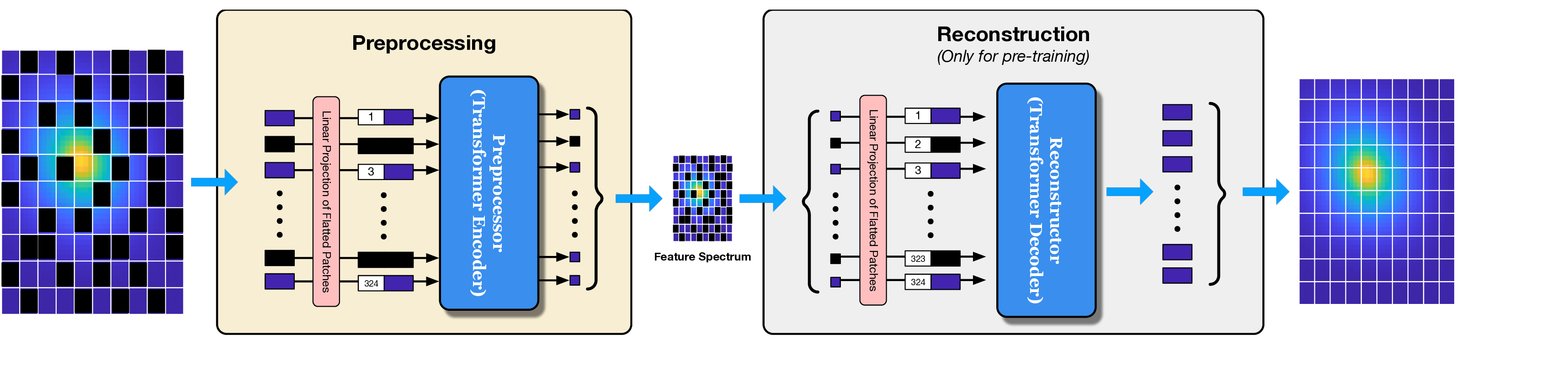
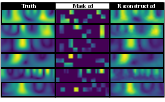
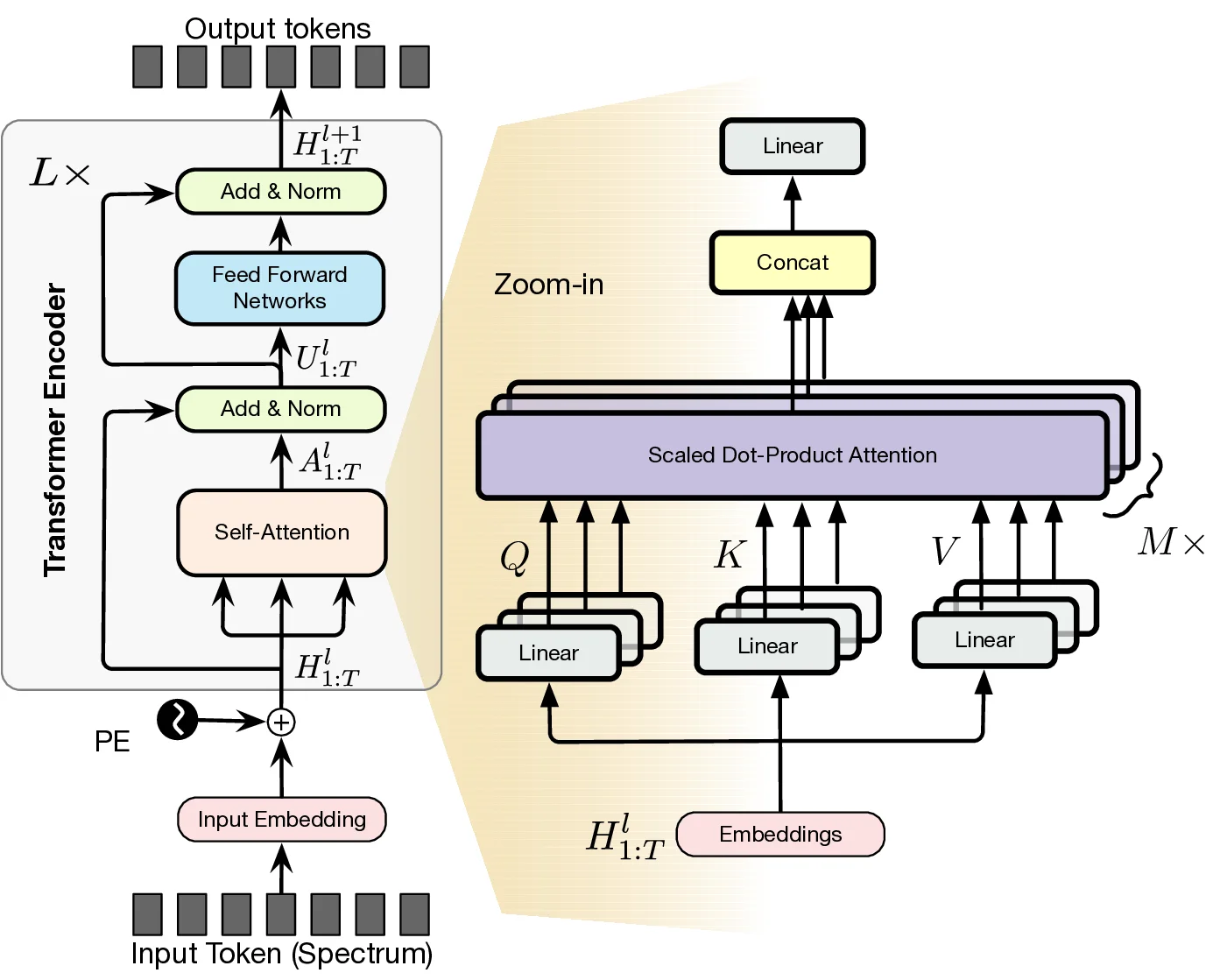
In this work, we propose Radiance-Field Reinforced Pretraining (RFRP), a novel approach that leverages large-scale unlabeled wireless data (i.e., without position labels) to pretrain LMs in a self-supervised manner. As illustrated in Fig. 1, RFRP adopts an encoder-decoder architecture (i.e., an autoencoder) by coupling a neural radio-frequency radiance field (RF-NeRF) with the large LM. The LM takes in the spectrum received by an RF base station (e.g., WiFi access point, BLE station, etc.) and outputs a latent representation related to the position of the RF device (e.g., WiFi client, BLE terminal, etc.). This latent feature is then reused as input to the RF-NeRF, which employs ray-tracing techniques to simulate the spectrum. The model is trained to align the input and reconstructed spectra, thereby enabling endto-end self-supervised learning. By extracting generalizable features from unlabeled RF signals, RFRP allows the LM to learn robust, scene-agnostic representations without requiring extensive labeled datasets. Once pretrained, the LM can be efficiently fine-tuned with a small number of labeled samples, substantially reducing the annotation burden.
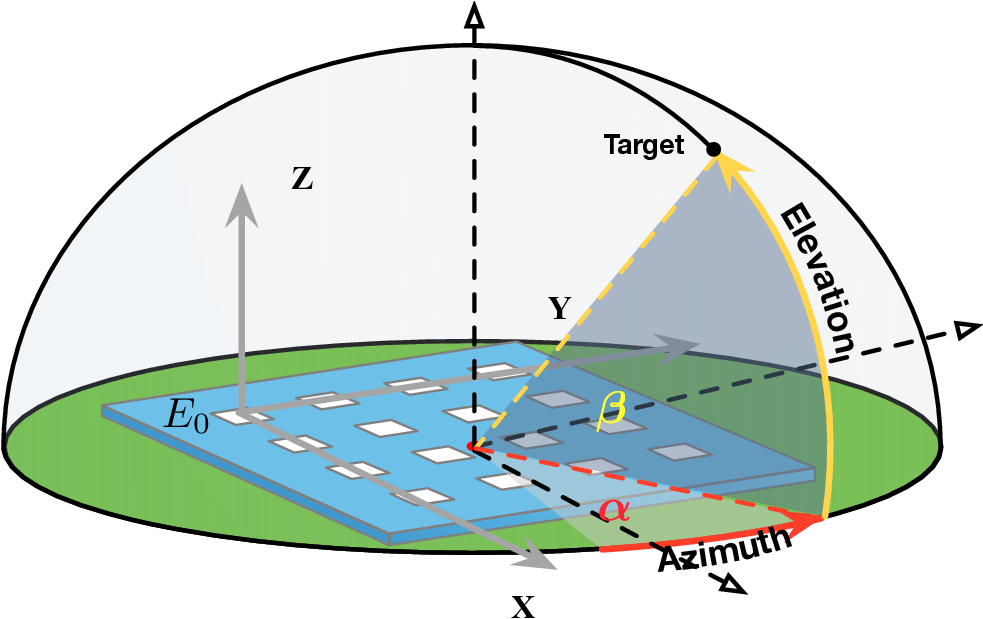
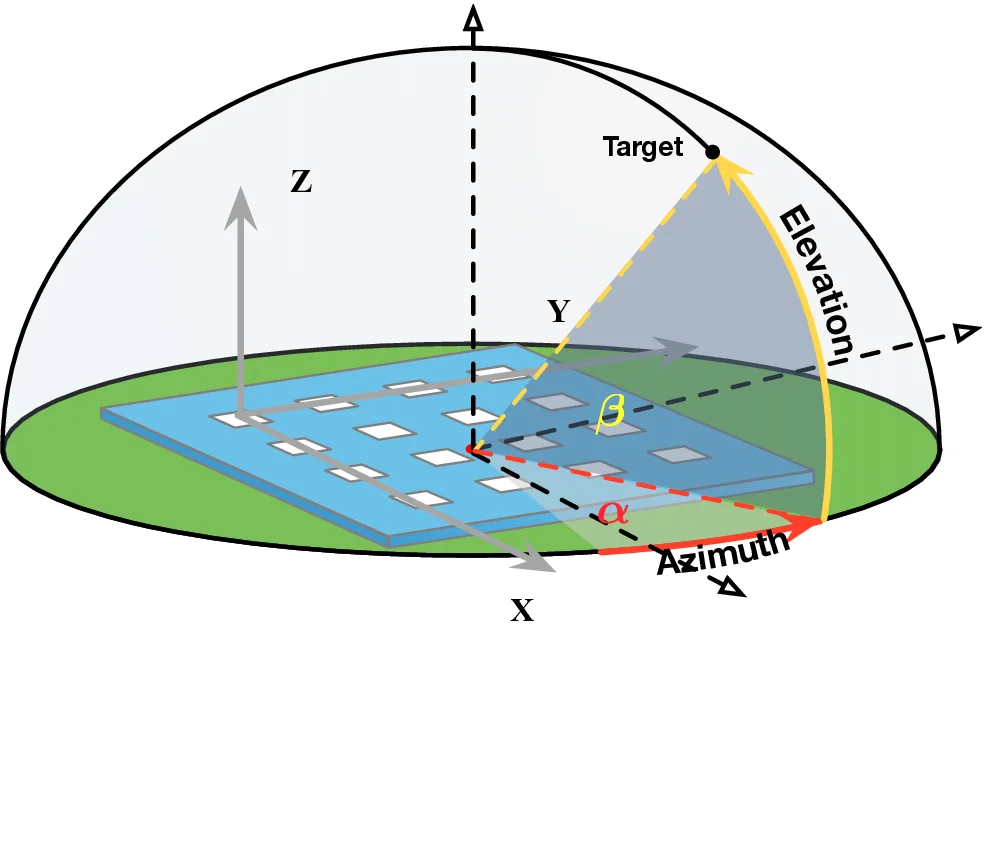
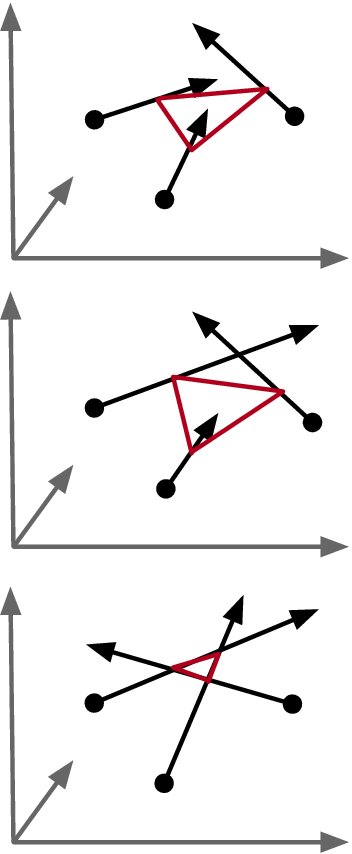
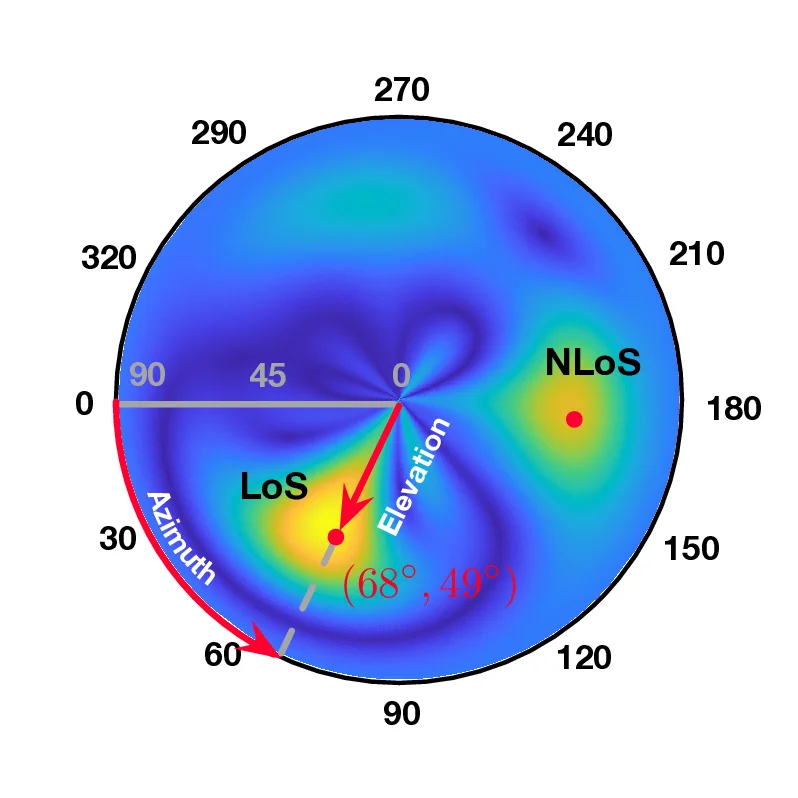
• What scene-agnostic features should the LM extract? Regardless of whether triangulation or trilateration is used, the core challenge in localization lies in accurately identifying the line-of-sight (LoS) path, which directly reflects the geometric relationship between the transmitter and base stations and is independent of the scene layout. However, multipath effects-caused by RF signals reflecting off surrounding objects-result in received signals being a superposition of multiple propagation paths, making the spectra highly scenedependent. Thus, the primary task of the localization model is to disentangle and extract features specifically associated with LoS propagation from these composite signals.
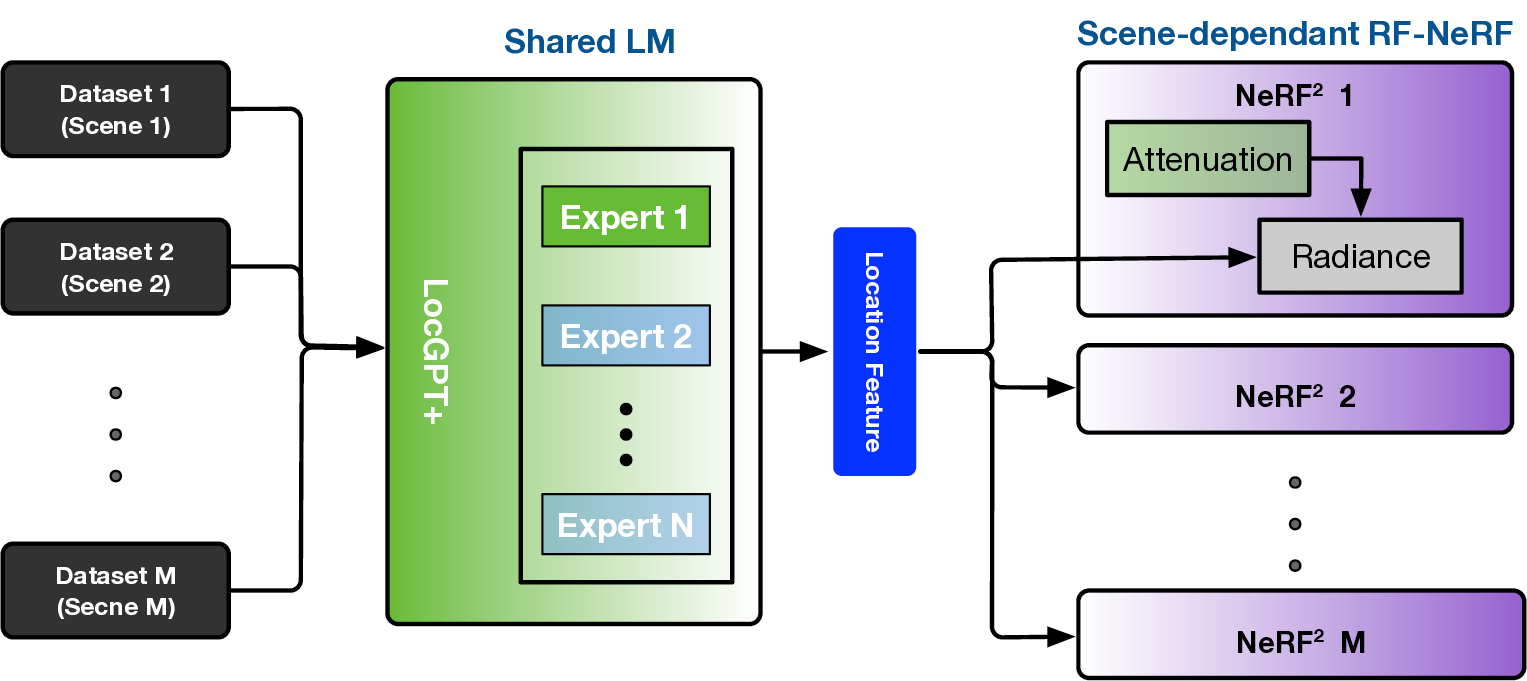
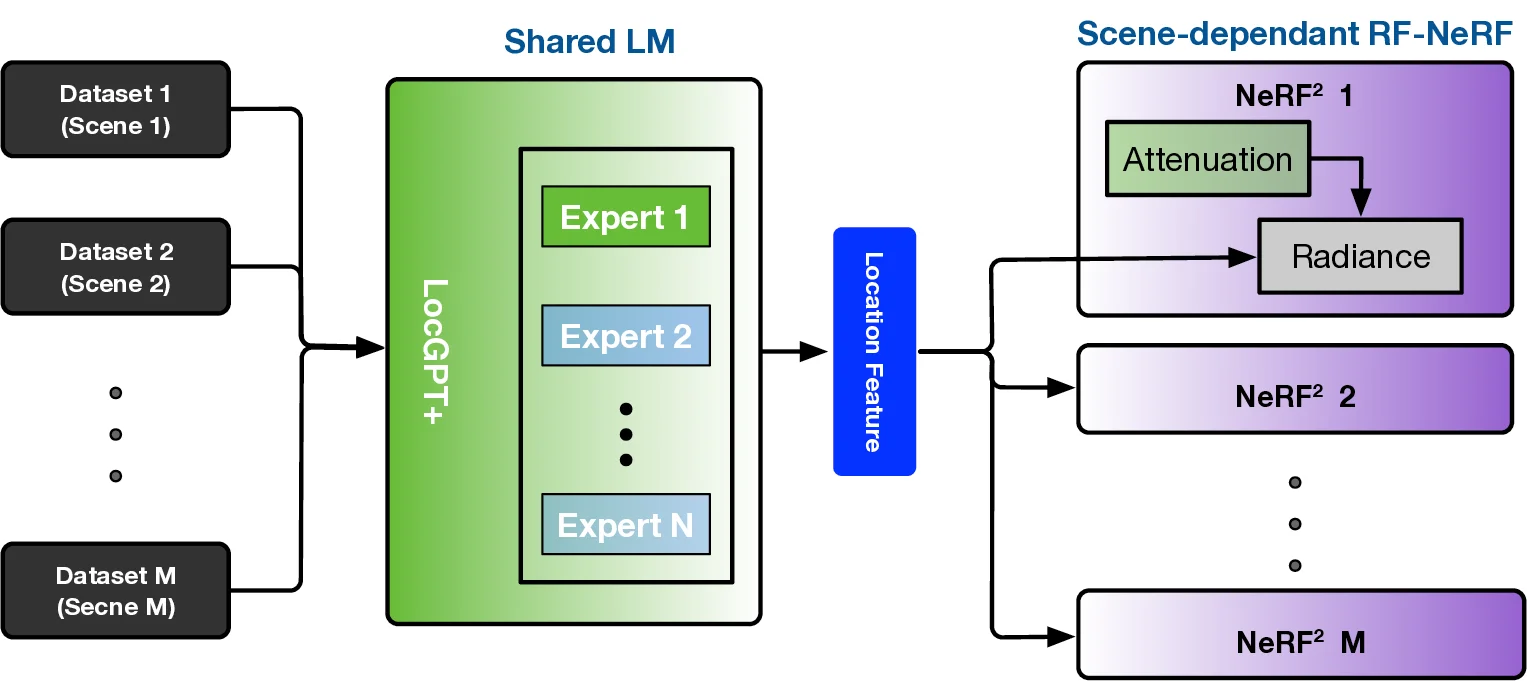
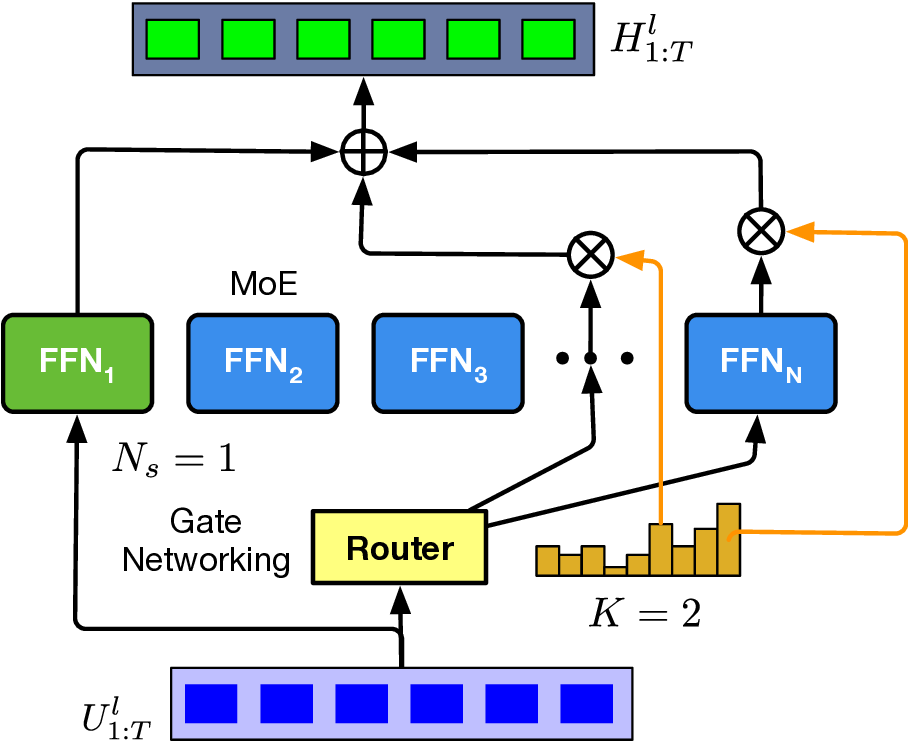
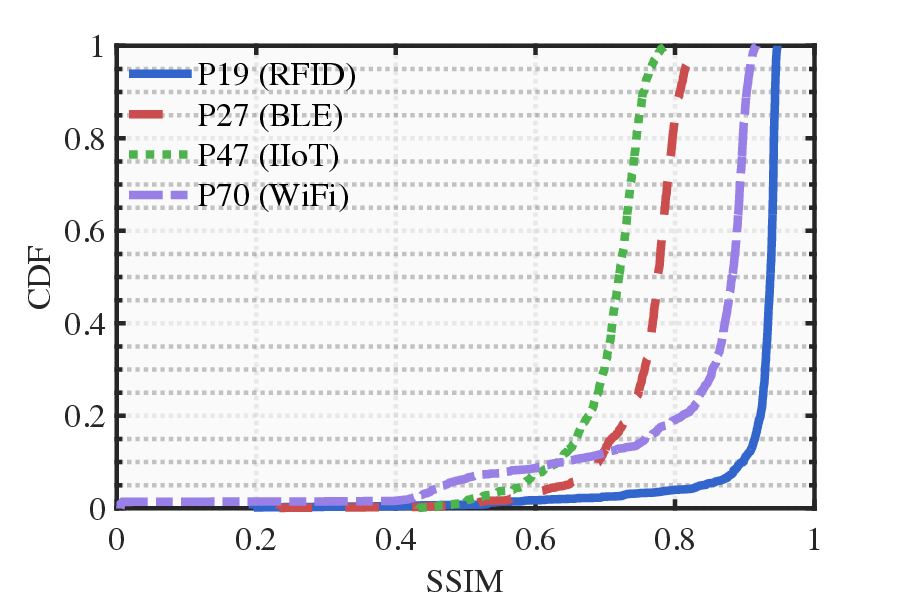
To this end, we extend the classical Transformer encoder into a 570-million-parameter localization model, referring to LocGPT+, by integrating a key enhancement: the Mixture of Experts (MoE) architecture. MoE is particularly suited for localization tasks due to its ability to manage complex and diverse spatial configurations. We hypothesize that each expert learns to specialize in different environment types, such as open areas or cluttered indoor settings. As the model is exposed to a wider range of scenes during training, the ensemble of experts collectively improves localization performance. Critically, the MoE framework enhances generalization by dynamically routing each input to the most relevant experts based on learned similarity. When encountering a new scene, the model can leverage knowledge from previously seen environments with similar characteristics. By distributing learning across multiple experts and selectively activating the most relevant ones, the MoE architecture significantly boosts the generalization of the localization model.
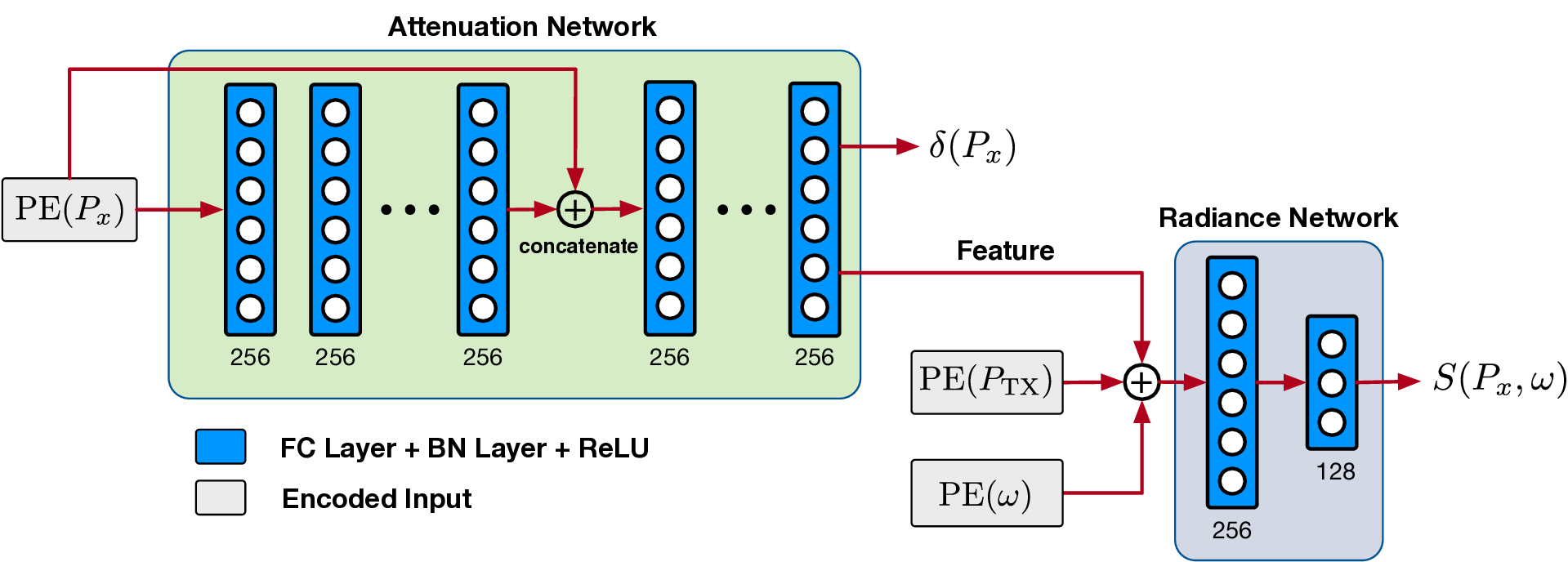
• How does the RF-NeRF guide the pretraining of the LM?
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.