We introduce a two-stage self-supervised framework that combines the Joint-Embedding Predictive Architecture (JEPA) with a Density Adaptive Attention Mechanism (DAAM) for learning robust speech representations. Stage 1 uses JEPA with DAAM to learn semantic audio features via masked prediction in latent space, fully decoupled from waveform reconstruction. Stage 2 leverages these representations for efficient tokenization using Finite Scalar Quantization (FSQ) and a mixed-radix packing scheme, followed by high-fidelity waveform reconstruction with a HiFi-GAN decoder. By integrating Gaussian mixturebased density-adaptive gating into the JEPA encoder, the model performs adaptive temporal feature selection and discovers hierarchical speech structure at a low frame rate of 2.5 Hz. The resulting tokens (47.5 tokens/sec) provide a reversible, highly compressed, and language-model-friendly representation that is competitive with, and often more efficient than, existing neural audio codecs.
Deep Dive into 두 단계 자기지도 학습으로 구현한 고효율 음성 표현 및 압축 프레임워크.
We introduce a two-stage self-supervised framework that combines the Joint-Embedding Predictive Architecture (JEPA) with a Density Adaptive Attention Mechanism (DAAM) for learning robust speech representations. Stage 1 uses JEPA with DAAM to learn semantic audio features via masked prediction in latent space, fully decoupled from waveform reconstruction. Stage 2 leverages these representations for efficient tokenization using Finite Scalar Quantization (FSQ) and a mixed-radix packing scheme, followed by high-fidelity waveform reconstruction with a HiFi-GAN decoder. By integrating Gaussian mixturebased density-adaptive gating into the JEPA encoder, the model performs adaptive temporal feature selection and discovers hierarchical speech structure at a low frame rate of 2.5 Hz. The resulting tokens (47.5 tokens/sec) provide a reversible, highly compressed, and language-model-friendly representation that is competitive with, and often more efficient than, existing neural audio codecs.
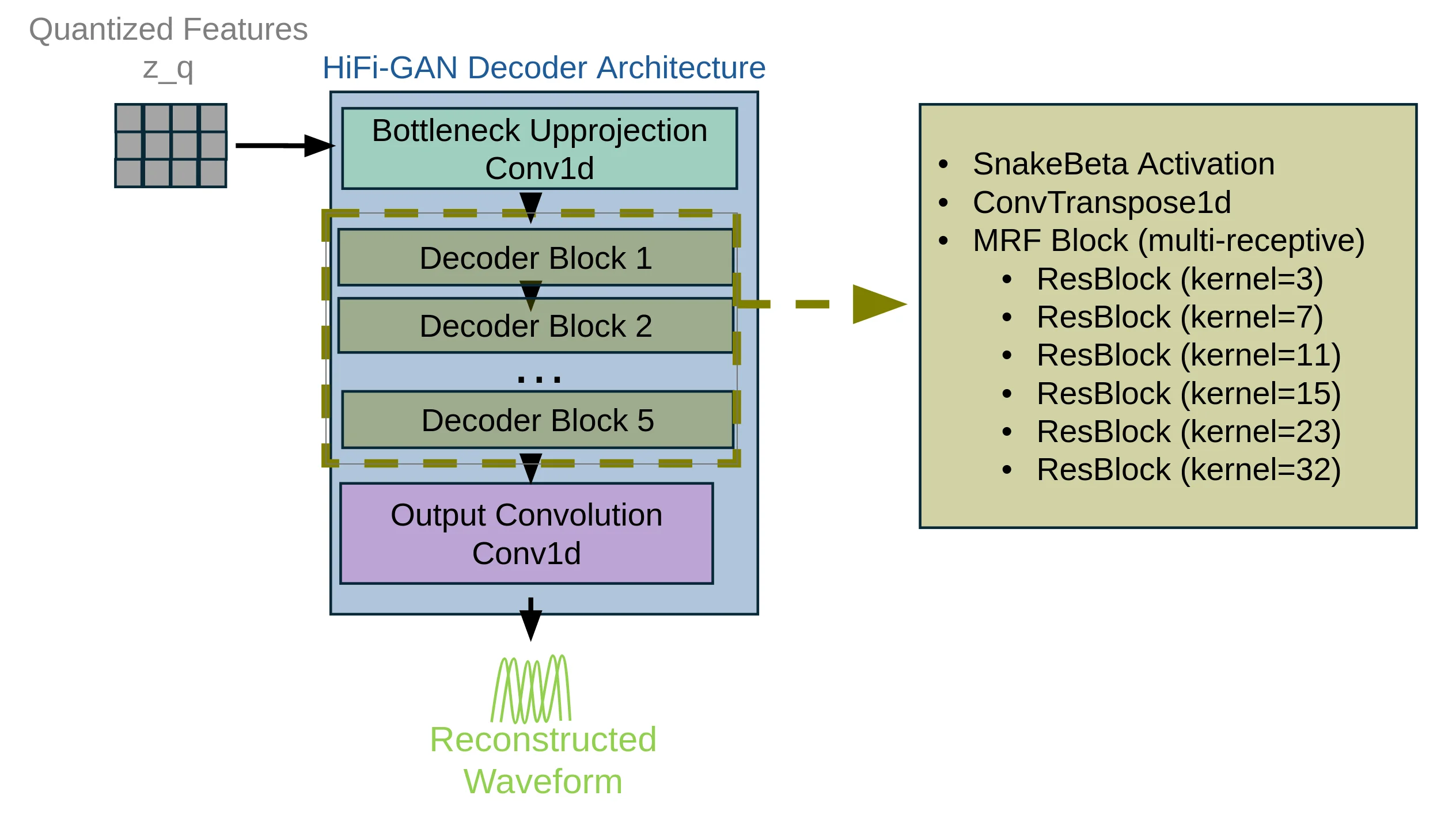
We introduce a two-stage self-supervised learning framework that combines the Joint-Embedding Predictive Architecture (JEPA) [Assran et al., 2023] with Density Adaptive Attention Mechanisms (DAAM) for learning robust speech representations. This approach decouples representation learning from reconstruction: Stage employs JEPA with DAAM to learn semantic audio features through masked prediction, while Stage leverages these representations for efficient tokenization via Finite Scalar Quantization (FSQ) [Mentzer et al., 2023] and high-quality reconstruction through HiFi-GAN [Kong et al., 2020].
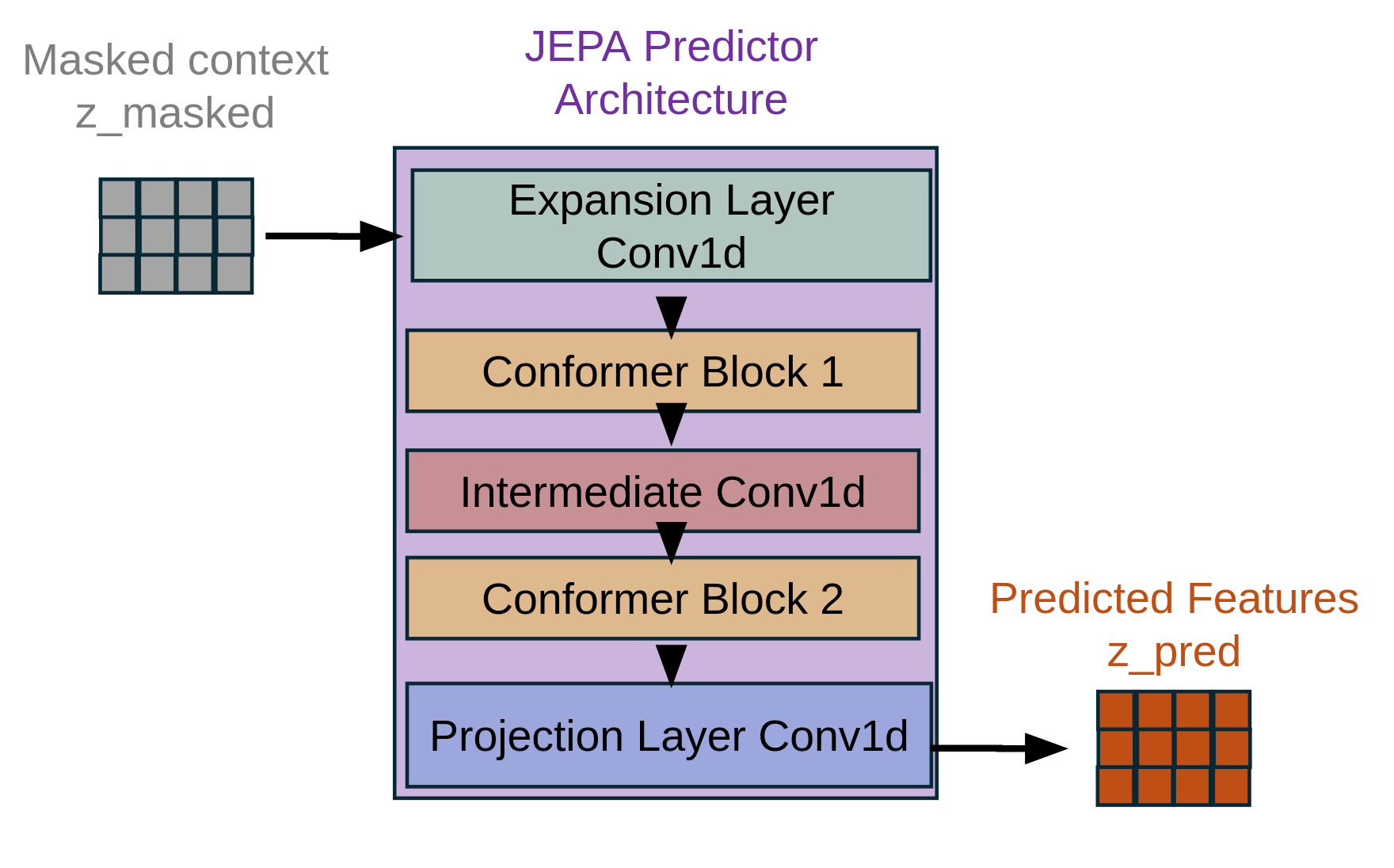
Key innovation. By integrating Density Adaptive Attention-based gating (Gaussian Mixture gating) [Ioannides et al., 2024] into the JEPA encoder, we achieve adaptive feature selection during self-supervised learning. Combined with a mixed-radix packing scheme, the learned representations capture hierarchical speech structure-due to progressive downsampling from layer to layer-at a low frame rate of 2.5 Hz, enabling efficient speech modeling without labeled data.
1.2 Motivation: Why JEPA for Speech?
Traditional speech codec training couples representation learning with reconstruction objectives, forcing the encoder to prioritize features that minimize waveform-level losses. This conflates two distinct goals:
Learning semantically meaningful representations that capture linguistic and acoustic structure.
Preserving perceptual quality for high-fidelity reconstruction.
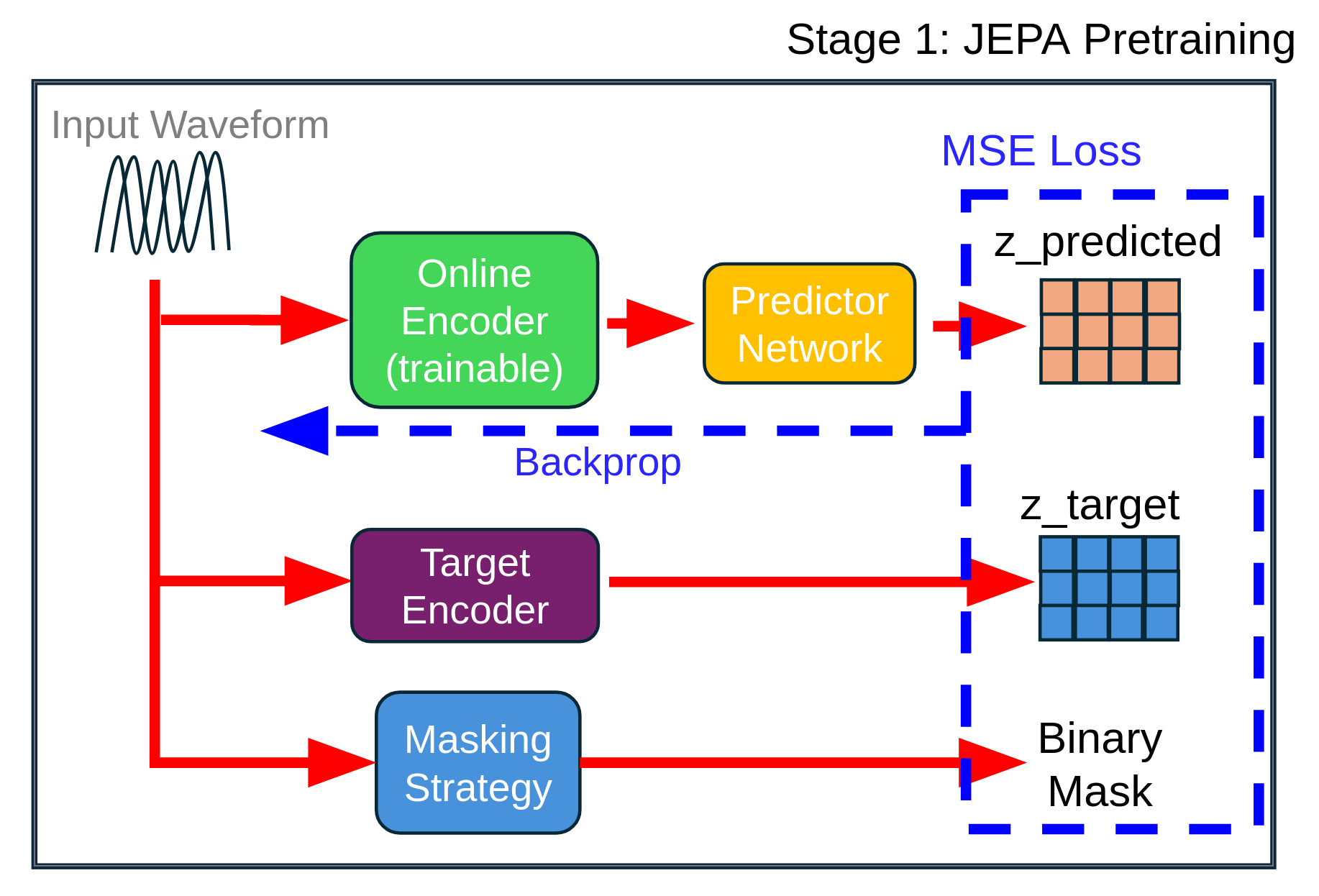
JEPA addresses this by separating concerns: the encoder learns to predict masked representations in latent space (Stage 1), then a separate decoder learns to map these representations to audio (Stage 2). This architectural separation enables:
• Better representations: the encoder optimizes for semantic content rather than low-level waveform details.
• Efficiency: fine-tuning the encoder reduces Stage 2 training cost.
• Flexibility: the same encoder can support multiple downstream tasks (text-to-speech, voice conversion, automatic speech recognition, etc.).
• Scalability: Stage 1 can leverage large unlabeled datasets.
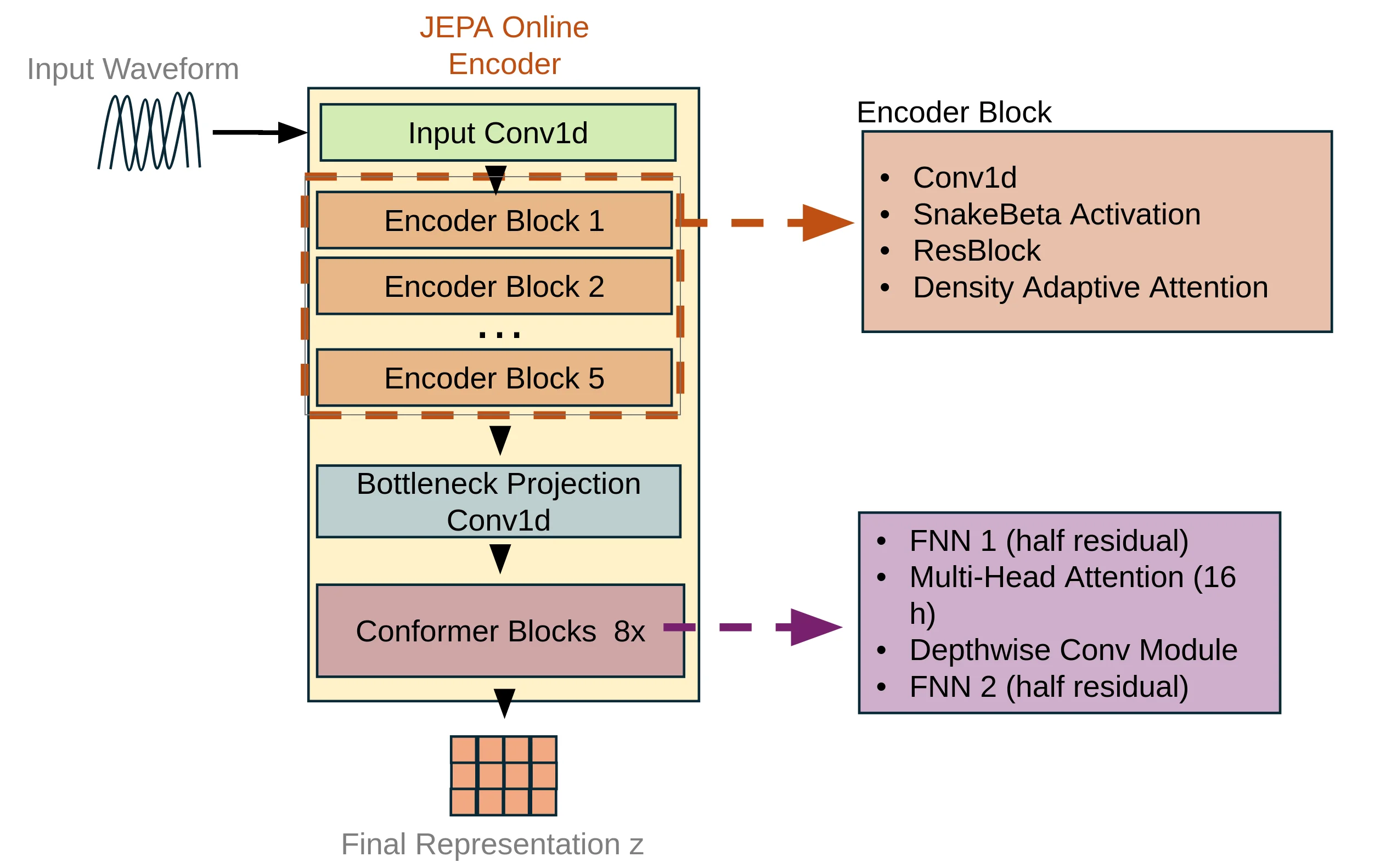
The integration of DAAM enhances this framework by introducing adaptive attention that learns which temporal regions and features are most informative for prediction, naturally discovering speech-relevant patterns.
2 Stage 1: Self-Supervised JEPA Encoder with DAAM
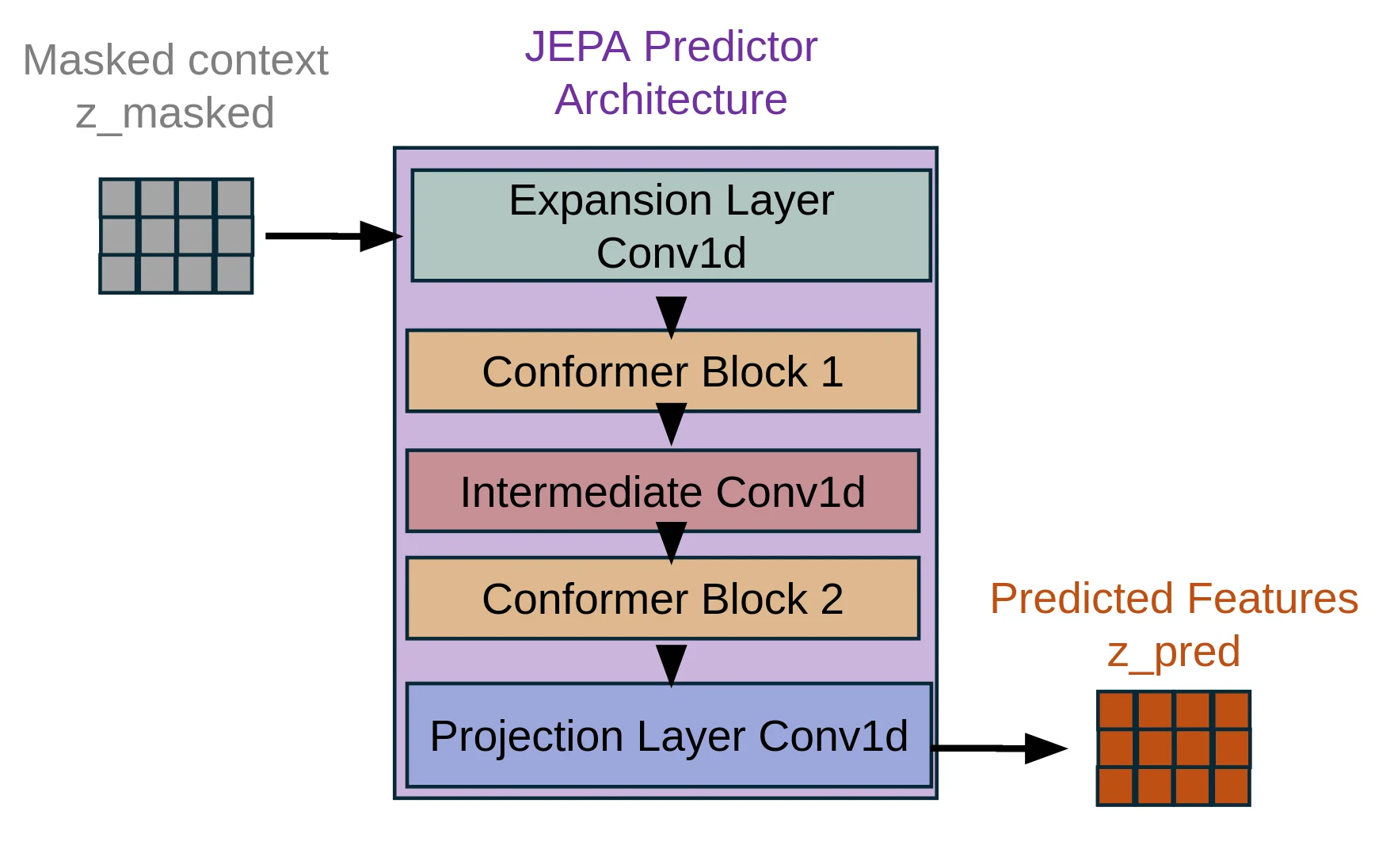
The JEPA framework employs block-based temporal masking to create a self-supervised learning objective. For a batch of audio sequences with temporal length T , binary masks m ∈ {0, 1} B×T are generated, where 1 indicates visible (context) regions and 0 indicates masked (target) regions.
Block Masking Algorithm. Given mask ratio ρ ∈ [0, 1], minimum span length s min , and maximum span length s max , we construct masks as follows:
- Initialize: m ← 1 B×T (all positions visible). Figure 1: The input waveform is processed by three parallel pathways: (1) an online encoder (trainable, green) that processes the full audio and feeds into a predictor network (yellow) after feature-space masking with a learned mask token, (2) a target encoder (purple) updated via EMA that also processes the full audio to generate z target , and (3) a masking strategy module (blue) that generates binary masks. The MSE loss is computed only on masked regions between z predicted and z target (stop-gradient), with gradients backpropagating only through the online encoder and predictor. The target encoder provides stable representations without receiving gradients directly [Grill et al., 2020].
(e) Update counter: n masked ← n masked + (t end -t start ).
This block masking strategy creates contiguous masked spans rather than random individual positions, forcing the model to learn longer-range temporal dependencies and semantic content.
• Mask ratio: ρ = 0.5 (50% of timesteps masked).
• Minimum span: s min = 2 frames.
• Maximum span: s max = T /4 frames (adaptive to sequence length).
At 2.5 Hz frame rate, this corresponds to variable spans adapted to the sequence length.
The core innovation integrating a stabilized version of the original DAAM into JEPA is the DensityAdap-tiveAttention module, which computes adaptive attention gates based on learned Gaussian mixture distributions. Unlike standard self-attention that computes pairwise dot-products between positions, DAAM learns to identify statistically salient temporal regions based on their distributional characteristics.
For input features x ∈ R B×C×T (batch size, channels, time), the DAAM module operates along the temporal axis.
Step 1: Temporal statistics. For each batch and channel, compute the mean and variance across time:
(2)
Step 2: Learnable Gaussian parameters. For K Gaussian components, we maintain learnable parameters:
The positive scales are computed via softplus:
with ϵ = 10 -3 for numerical stability.
Step 3: Standardized deviations. For each component k and timestep t:
Step 4: Log-density under each Gaussian. The l
…(Full text truncated)…
This content is AI-processed based on ArXiv data.